Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
PaddlePaddle
Paddle-Lite
提交
8dc7b259
P
Paddle-Lite
项目概览
PaddlePaddle
/
Paddle-Lite
通知
338
Star
4
Fork
1
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
271
列表
看板
标记
里程碑
合并请求
78
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
P
Paddle-Lite
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
271
Issue
271
列表
看板
标记
里程碑
合并请求
78
合并请求
78
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
You need to sign in or sign up before continuing.
提交
8dc7b259
编写于
5月 20, 2020
作者:
H
huzhiqiang
提交者:
GitHub
5月 20, 2020
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
[Doc][Python API][Opt] update python API & opt doc for release/v2.6.0 (#3666)
上级
d760bb43
变更
15
隐藏空白更改
内联
并排
Showing
15 changed file
with
1199 addition
and
880 deletion
+1199
-880
docs/api_reference/python_api/CxxConfig.md
docs/api_reference/python_api/CxxConfig.md
+200
-0
docs/api_reference/python_api/CxxPredictor.md
docs/api_reference/python_api/CxxPredictor.md
+94
-0
docs/api_reference/python_api/LightPredictor.md
docs/api_reference/python_api/LightPredictor.md
+88
-0
docs/api_reference/python_api/MobileConfig.md
docs/api_reference/python_api/MobileConfig.md
+147
-0
docs/api_reference/python_api/PowerMode.md
docs/api_reference/python_api/PowerMode.md
+33
-0
docs/api_reference/python_api/Tensor.md
docs/api_reference/python_api/Tensor.md
+140
-0
docs/api_reference/python_api/TypePlace.md
docs/api_reference/python_api/TypePlace.md
+54
-0
docs/api_reference/python_api/create_paddle_predictor.md
docs/api_reference/python_api/create_paddle_predictor.md
+32
-0
docs/api_reference/python_api/opt.md
docs/api_reference/python_api/opt.md
+128
-0
docs/api_reference/python_api_doc.md
docs/api_reference/python_api_doc.md
+12
-738
docs/user_guides/model_optimize_tool.md
docs/user_guides/model_optimize_tool.md
+28
-139
docs/user_guides/opt/opt_bin.md
docs/user_guides/opt/opt_bin.md
+96
-0
docs/user_guides/opt/opt_python.md
docs/user_guides/opt/opt_python.md
+103
-0
docs/user_guides/opt/x2paddle&opt.md
docs/user_guides/opt/x2paddle&opt.md
+43
-0
docs/user_guides/tutorial.md
docs/user_guides/tutorial.md
+1
-3
未找到文件。
docs/api_reference/python_api/CxxConfig.md
0 → 100755
浏览文件 @
8dc7b259
## CxxConfig
```
python
class
CxxConfig
;
```
`CxxConfig`
用来配置构建CxxPredictor的配置信息,如protobuf格式的模型地址、能耗模式、工作线程数、place信息等等。
示例:
```
python
from
paddlelite.lite
import
*
config
=
CxxConfig
()
# 设置模型目录,加载非combined模型时使用
config
.
set_model_dir
(
<
your_model_dir_path
>
)
# 设置工作线程数(该接口只支持armlinux)
# config.set_threads(4);
# 设置能耗模式(该接口只支持armlinux)
# config.set_power_mode(PowerMode.LITE_POWER_NO_BIND)
# 设置valid places
places
=
[
Place
(
TargetType
.
ARM
,
PrecisionType
.
FP32
)]
config
.
set_valid_places
(
places
)
# 根据CxxConfig创建CxxPredictor
predictor
=
lite
.
create_paddle_predictor
(
config
)
```
### `set_model_dir(model_dir)`
设置模型文件夹路径,当需要从磁盘加载非combined模型时使用。
参数:
-
`model_dir(str)`
- 模型文件夹路径
返回:
`None`
返回类型:
`None`
### `model_dir()`
返回设置的模型文件夹路径。
参数:
-
`None`
返回:模型文件夹路径
返回类型:
`str`
### `set_model_file(model_file)`
设置模型文件路径,加载combined形式模型时使用。
参数:
-
`model_file(str)`
- 模型文件路径
返回类型:
`None`
### `model_file()`
获取设置模型文件路径,加载combined形式模型时使用。
参数:
-
`None`
返回:模型文件路径
返回类型:
`str`
### `set_param_file(param_file)`
设置模型参数文件路径,加载combined形式模型时使用。
参数:
-
`param_file(str)`
- 模型文件路径
返回类型:
`None`
### `param_file()`
获取设置模型参数文件路径,加载combined形式模型时使用。
参数:
-
`None`
返回:模型参数文件路径
返回类型:
`str`
### `set_valid_places(valid_places)`
设置可用的places列表。
参数:
-
`valid_places(list)`
- 可用place列表。
返回类型:
`None`
示例:
```
python
from
paddlelite.lite
import
*
config
=
CxxConfig
()
# 设置模型目录,加载非combined模型时使用
config
.
set_model_dir
(
<
your_model_dir_path
>
)
# 设置valid places
# 注意,valid_places列表中Place的排序表明了用户对Place的偏好程度,如用户想优先使用ARM上Int8精度的
# kernel,则应把Place(TargetType.ARM, PrecisionType.INT8)置于valid_places列表的首位。
places
=
[
Place
(
TargetType
.
ARM
,
PrecisionType
.
INT8
),
Place
(
TargetType
.
ARM
,
PrecisionType
.
FP32
)]
config
.
set_valid_places
(
places
)
# 根据CxxConfig创建CxxPredictor
predictor
=
create_paddle_predictor
(
config
)
```
### `set_power_mode(mode)`
设置CPU能耗模式,该接口只支持
`armlinux`
平台。若不设置,则默认使用
`PowerMode.LITE_POWER_HIGH`
。
*注意:只在开启`OpenMP`时生效,否则系统自动调度。此函数只在使用`LITE_WITH_ARM`编译选项下生效。*
参数:
-
`mode(PowerMode)`
- CPU能耗模式
返回:
`None`
返回类型:
`None`
### `power_mode()`
获取设置的CPU能耗模式,该接口只支持
`armlinux`
平台。
*注意:此函数只在使用`LITE_WITH_ARM`编译选项下生效。*
参数:
-
`None`
返回:设置的CPU能耗模式
返回类型:
`PowerMode`
### `set_threads(threads)`
设置工作线程数,该接口只支持
`armlinux`
平台。若不设置,则默认使用单线程。
*注意:只在开启`OpenMP`的模式下生效,否则只使用单线程。此函数只在使用`LITE_WITH_ARM`编译选项下生效。*
参数:
-
`threads(int)`
- 工作线程数
返回:
`None`
返回类型:
`None`
### `threads()`
获取设置的工作线程数,该接口只支持
`armlinux`
平台。
*注意:此函数只在使用`LITE_WITH_ARM`编译选项下生效。*
参数:
-
`None`
返回:工作线程数
返回类型:
`int`
docs/api_reference/python_api/CxxPredictor.md
0 → 100755
浏览文件 @
8dc7b259
## CxxPredictor
```
c++
class
CxxPredictor
```
`CxxPredictor`
是Paddle-Lite的预测器,由
`create_paddle_predictor`
根据
`CxxConfig`
进行创建。用户可以根据CxxPredictor提供的接口设置输入数据、执行模型预测、获取输出以及获得当前使用lib的版本信息等。
示例:
```
python
from
paddlelite.lite
import
*
from
lite_core
import
*
# 1. 设置CxxConfig
config
=
CxxConfig
()
if
args
.
model_file
!=
''
and
args
.
param_file
!=
''
:
config
.
set_model_file
(
args
.
model_file
)
config
.
set_param_file
(
args
.
param_file
)
else
:
config
.
set_model_dir
(
args
.
model_dir
)
places
=
[
Place
(
TargetType
.
ARM
,
PrecisionType
.
FP32
)]
config
.
set_valid_places
(
places
)
# 2. 创建CxxPredictor
predictor
=
create_paddle_predictor
(
config
)
# 3. 设置输入数据
input_tensor
=
predictor
.
get_input
(
0
)
input_tensor
.
resize
([
1
,
3
,
224
,
224
])
input_tensor
.
set_float_data
([
1.
]
*
3
*
224
*
224
)
# 4. 运行模型
predictor
.
run
()
# 5. 获取输出数据
output_tensor
=
predictor
.
get_output
(
0
)
print
(
output_tensor
.
shape
())
print
(
output_tensor
.
float_data
()[:
10
])
```
### `get_input(index)`
获取输入Tensor,用来设置模型的输入数据。
参数:
-
`index(int)`
- 输入Tensor的索引
返回:第
`index`
个输入
`Tensor`
返回类型:
`Tensor`
### `get_output(index)`
获取输出Tensor,用来获取模型的输出结果。
参数:
-
`index(int)`
- 输出Tensor的索引
返回:第
`index`
个输出
`Tensor`
返回类型:
`Tensor`
### `run()`
执行模型预测,需要在
***设置输入数据后**
*
调用。
参数:
-
`None`
返回:
`None`
返回类型:
`None`
### `get_version()`
用于获取当前lib使用的代码版本。若代码有相应tag则返回tag信息,如
`v2.0-beta`
;否则返回代码的
`branch(commitid)`
,如
`develop(7e44619)`
。
参数:
-
`None`
返回:当前lib使用的代码版本信息
返回类型:
`str`
docs/api_reference/python_api/LightPredictor.md
0 → 100755
浏览文件 @
8dc7b259
## LightPredictor
```
c++
class
LightPredictor
```
`LightPredictor`
是Paddle-Lite的预测器,由
`create_paddle_predictor`
根据
`MobileConfig`
进行创建。用户可以根据LightPredictor提供的接口设置输入数据、执行模型预测、获取输出以及获得当前使用lib的版本信息等。
示例:
```
python
from
__future__
import
print_function
from
paddlelite.lite
import
*
# 1. 设置MobileConfig
config
=
MobileConfig
()
config
.
set_model_dir
(
args
.
model_dir
)
# 2. 创建LightPredictor
predictor
=
create_paddle_predictor
(
config
)
# 3. 设置输入数据
input_tensor
=
predictor
.
get_input
(
0
)
input_tensor
.
resize
([
1
,
3
,
224
,
224
])
input_tensor
.
set_float_data
([
1.
]
*
3
*
224
*
224
)
# 4. 运行模型
predictor
.
run
()
# 5. 获取输出数据
output_tensor
=
predictor
.
get_output
(
0
)
print
(
output_tensor
.
shape
())
print
(
output_tensor
.
float_data
()[:
10
])
```
### `get_input(index)`
获取输入Tensor,用来设置模型的输入数据。
参数:
-
`index(int)`
- 输入Tensor的索引
返回:第
`index`
个输入
`Tensor`
返回类型:
`Tensor`
### `get_output(index)`
获取输出Tensor,用来获取模型的输出结果。
参数:
-
`index(int)`
- 输出Tensor的索引
返回:第
`index`
个输出
`Tensor`
返回类型:
`Tensor`
### `run()`
执行模型预测,需要在
***设置输入数据后**
*
调用。
参数:
-
`None`
返回:
`None`
返回类型:
`None`
### `get_version()`
用于获取当前lib使用的代码版本。若代码有相应tag则返回tag信息,如
`v2.0-beta`
;否则返回代码的
`branch(commitid)`
,如
`develop(7e44619)`
。
参数:
-
`None`
返回:当前lib使用的代码版本信息
返回类型:
`str`
docs/api_reference/python_api/MobileConfig.md
0 → 100755
浏览文件 @
8dc7b259
## MobileConfig
```
python
class
MobileConfig
;
```
`MobileConfig`
用来配置构建LightPredictor的配置信息,如NaiveBuffer格式的模型地址、能耗模式、工作线程数等等。
示例:
```
python
from
paddlelite.lite
import
*
config
=
MobileConfig
()
# 设置NaiveBuffer格式模型目录
config
.
set_model_from_file
(
<
your_model_path
>
)
# 设置工作线程数
config
.
set_threads
(
4
);
# 设置能耗模式
config
.
set_power_mode
(
PowerMode
.
LITE_POWER_NO_BIND
)
# 根据MobileConfig创建LightPredictor
predictor
=
create_paddle_predictor
(
config
)
```
### `set_model_from_file(model_file)`
**注意**
:
`model_file`
应该是经过
`opt`
优化后产生的
`NaiveBuffer`
格式的模型。
设置模型文件夹路径。
参数:
-
`model_file(str)`
- 模型文件路径
返回:
`None`
返回类型:
`None`
### `set_model_dir(model_dir)`
**注意**
:Lite模型格式在release/v2.3.0之后修改,本接口为加载老格式模型的接口,将在release/v3.0.0废弃。建议替换为
`setModelFromFile`
接口。
`model_dir`
应该是经过
`Model Optimize Tool`
优化后产生的
`NaiveBuffer`
格式的模型。
设置模型文件夹路径。
参数:
-
`model_dir(str)`
- 模型文件夹路径
返回:
`None`
返回类型:
`None`
### `set_model_from_buffer(model_buffer)`
设置模型的内存数据,当需要从内存加载模型时使用。
参数:
-
`model_buffer(str)`
- 内存中的模型数据
返回:
`None`
返回类型:
`void`
### `model_dir()`
返回设置的模型文件夹路径。
参数:
-
`None`
返回:模型文件夹路径
返回类型:
`str`
### `set_power_mode(mode)`
设置CPU能耗模式。若不设置,则默认使用
`PowerMode.LITE_POWER_HIGH`
。
*注意:只在开启`OpenMP`时生效,否则系统自动调度。此函数只在使用`LITE_WITH_ARM`编译选项下生效。*
参数:
-
`mode(PowerMode)`
- CPU能耗模式
返回:
`None`
返回类型:
`None`
### `power_mode()`
获取设置的CPU能耗模式,该接口只支持
`armlinux`
平台。
*注意:此函数只在使用`LITE_WITH_ARM`编译选项下生效。*
参数:
-
`None`
返回:设置的CPU能耗模式
返回类型:
`PowerMode`
### `set_threads(threads)`
设置工作线程数,该接口只支持
`armlinux`
平台。若不设置,则默认使用单线程。
*注意:只在开启`OpenMP`的模式下生效,否则只使用单线程。此函数只在使用`LITE_WITH_ARM`编译选项下生效。*
参数:
-
`threads(int)`
- 工作线程数
返回:
`None`
返回类型:
`None`
### `threads()`
获取设置的工作线程数,该接口只支持
`armlinux`
平台。
*注意:此函数只在使用`LITE_WITH_ARM`编译选项下生效。*
参数:
-
`None`
返回:工作线程数
返回类型:
`int`
docs/api_reference/python_api/PowerMode.md
0 → 100755
浏览文件 @
8dc7b259
## PowerMode
```
python
class
PowerMode
;
```
`PowerMode`
为ARM CPU能耗模式,用户可以根据应用场景设置能耗模式获得最优的能效比。
示例:
```
python
from
paddlelite.lite
import
*
config
=
MobileConfig
()
# 设置NaiveBuffer格式模型目录
config
.
set_model_dir
(
<
your_model_dir_path
>
)
# 设置能耗模式
config
.
set_power_mode
(
PowerMode
.
LITE_POWER_NO_BIND
)
# 根据MobileConfig创建LightPredictor
predictor
=
create_paddle_predictor
(
config
)
```
PowerMode详细说明如下:
| 选项 | 说明 |
| :------------------: | ------------------------------------------------------------ |
| LITE_POWER_HIGH | 绑定大核运行模式。如果ARM CPU支持big.LITTLE,则优先使用并绑定Big cluster。如果设置的线程数大于大核数量,则会将线程数自动缩放到大核数量。如果系统不存在大核或者在一些手机的低电量情况下会出现绑核失败,如果失败则进入不绑核模式。 |
| LITE_POWER_LOW | 绑定小核运行模式。如果ARM CPU支持big.LITTLE,则优先使用并绑定Little cluster。如果设置的线程数大于小核数量,则会将线程数自动缩放到小核数量。如果找不到小核,则自动进入不绑核模式。 |
| LITE_POWER_FULL | 大小核混用模式。线程数可以大于大核数量。当线程数大于核心数量时,则会自动将线程数缩放到核心数量。 |
| LITE_POWER_NO_BIND | 不绑核运行模式(推荐)。系统根据负载自动调度任务到空闲的CPU核心上。 |
| LITE_POWER_RAND_HIGH | 轮流绑定大核模式。如果Big cluster有多个核心,则每预测10次后切换绑定到下一个核心。 |
| LITE_POWER_RAND_LOW | 轮流绑定小核模式。如果Little cluster有多个核心,则每预测10次后切换绑定到下一个核心。 |
docs/api_reference/python_api/Tensor.md
0 → 100755
浏览文件 @
8dc7b259
## Tensor
```
c++
class
Tensor
```
Tensor是Paddle-Lite的数据组织形式,用于对底层数据进行封装并提供接口对数据进行操作,包括设置Shape、数据、LoD信息等。
*注意:用户应使用`CxxPredictor`或`LightPredictor`的`get_input`和`get_output`接口获取输入/输出的`Tensor`。*
示例:
```
python
from
paddlelite.lite
import
*
from
lite_core
import
*
# 1. 设置CxxConfig
config
=
CxxConfig
()
if
args
.
model_file
!=
''
and
args
.
param_file
!=
''
:
config
.
set_model_file
(
args
.
model_file
)
config
.
set_param_file
(
args
.
param_file
)
else
:
config
.
set_model_dir
(
args
.
model_dir
)
places
=
[
Place
(
TargetType
.
ARM
,
PrecisionType
.
FP32
)]
config
.
set_valid_places
(
places
)
# 2. 创建CxxPredictor
predictor
=
create_paddle_predictor
(
config
)
# 3. 设置输入数据
input_tensor
=
predictor
.
get_input
(
0
)
input_tensor
.
resize
([
1
,
3
,
224
,
224
])
input_tensor
.
set_float_data
([
1.
]
*
3
*
224
*
224
)
# 4. 运行模型
predictor
.
run
()
# 5. 获取输出数据
output_tensor
=
predictor
.
get_output
(
0
)
print
(
output_tensor
.
shape
())
print
(
output_tensor
.
float_data
()[:
10
])
```
### `resize(shape)`
设置Tensor的维度信息。
参数:
-
`shape(list)`
- 维度信息
返回:
`None`
返回类型:
`None`
### `shape()`
获取Tensor的维度信息。
参数:
-
`None`
返回:Tensor的维度信息
返回类型:
`list`
### `float_data()`
获取Tensor的持有的float型数据。
示例:
```
python
output_tensor
=
predictor
.
get_output
(
0
)
print
(
output_tensor
.
shape
())
print
(
output_tensor
.
float_data
()[:
10
])
```
参数:
-
`None`
返回:
`Tensor`
持有的float型数据
返回类型:
`list`
### `set_float_data(float_data)`
设置Tensor持有float数据。
示例:
```
python
input_tensor
=
predictor
.
get_input
(
0
)
input_tensor
.
resize
([
1
,
3
,
224
,
224
])
input_tensor
.
set_float_data
([
1.
]
*
3
*
224
*
224
)
```
参数:
-
`float_data(list)`
- 待设置的float型数据
返回:
`None`
返回类型:
`None`
### `set_lod(lod)`
设置Tensor的LoD信息。
参数:
-
`lod(list[list])`
- Tensor的LoD信息
返回:
`None`
返回类型:
`None`
### `lod()`
获取Tensor的LoD信息
参数:
-
`None`
返回:
`Tensor`
的LoD信息
返回类型:
`list[list]`
docs/api_reference/python_api/TypePlace.md
0 → 100755
浏览文件 @
8dc7b259
## TargetType
```
python
class
TargetType
;
```
`TargetType`
为目标设备硬件类型,用户可以根据应用场景选择硬件平台类型。
枚举型变量
`TargetType`
的所有可能取值包括:
`{X86, CUDA, ARM, OpenCL, FPGA, NPU}`
## PrecisionType
```
python
class
PrecisionType
{
FP32
};
```
`PrecisionType`
为模型中Tensor的数据精度,默认值为FP32(float32)。
枚举型变量
`PrecisionType`
的所有可能取值包括:
`{FP32, INT8, INT32, INT64}`
## DataLayoutType
```
python
class
DataLayoutType
{
NCHW
};
```
`DataLayoutType`
为Tensor的数据格式,默认值为NCHW(number, channel, height, weigth)。
枚举型变量
`DataLayoutType`
的所有可能取值包括:
` {NCHW, NHWC}`
## Place
```
python
class
Place
{
TargetType
target
;
PrecisionType
precision
{
FP32
};
DataLayoutType
layout
{
NCHW
}
}
```
`Place`
是
`TargetType`
、
`PrecisionType`
和
`DataLayoutType`
的集合,说明运行时的设备类型、数据精度和数据格式。
示例:
```
python
from
lite_core
import
*
Place
{
TargetType
(
ARM
),
PrecisionType
(
FP32
),
DataLayoutType
(
NCHW
)}
```
docs/api_reference/python_api/create_paddle_predictor.md
0 → 100755
浏览文件 @
8dc7b259
## create_paddle_predictor
```
python
CxxPredictor
create_paddle_predictor
(
config
);
# config为CxxConfig类型
LightPredictor
create_paddle_predictor
(
config
);
# config为MobileConfig类型
```
`create_paddle_predictor`
函数用来根据
`CxxConfig`
或
`MobileConfig`
构建预测器。
示例:
```
python
from
paddlelite.lite
import
*
# 设置CxxConfig
config
=
CxxConfig
()
config
.
set_model_dir
(
<
your_model_dir_path
>
)
places
=
[
Place
(
TargetType
.
ARM
,
PrecisionType
.
FP32
)]
config
.
set_valid_places
(
places
)
# 根据CxxConfig创建CxxPredictor
predictor
=
create_paddle_predictor
(
config
)
```
参数:
-
`config(CxxConfig或MobileConfig)`
- 用于构建Predictor的配置信息。
返回:预测器
`predictor`
返回类型:
`CxxPredictor`
或
`LightPredictor`
docs/api_reference/python_api/opt.md
0 → 100755
浏览文件 @
8dc7b259
## Opt
```
python
class
Opt
;
```
`Opt`
模型离线优化接口,Paddle原生模型需经
`opt`
优化图结构后才能在Paddle-Lite上运行。
示例:
假设待转化模型问当前文件夹下的
`mobilenet_v1`
,可以使用以下脚本转换
```
python
# 引用Paddlelite预测库
from
paddlelite.lite
import
*
# 1. 创建opt实例
opt
=
Opt
()
# 2. 指定输入模型地址
opt
.
set_model_dir
(
"./mobilenet_v1"
)
# 3. 指定转化类型: arm、x86、opencl、xpu、npu
opt
.
set_valid_places
(
"arm"
)
# 4. 指定模型转化类型: naive_buffer、protobuf
opt
.
set_model_type
(
"naive_buffer"
)
# 4. 输出模型地址
opt
.
set_optimize_out
(
"mobilenetv1_opt"
)
# 5. 执行模型优化
opt
.
run
()
```
### `set_model_dir(model_dir)`
设置模型文件夹路径,当需要从磁盘加载非combined模型时使用。
参数:
-
`model_dir(str)`
- 模型文件夹路径
返回:
`None`
### `set_model_file(model_file)`
设置模型文件路径,加载combined形式模型时使用。
参数:
-
`model_file(str)`
- 模型文件路径
### `set_param_file(param_file)`
设置模型参数文件路径,加载combined形式模型时使用。
参数:
-
`param_file(str)`
- 模型文件路径
### `set_model_type(type)`
设置模型的输出类型,当前支持
`naive_buffer`
和
`protobuf`
两种格式,移动端预测需要转化为
`naive_buffer`
参数:
-
`type(str)`
- 模型格式(
`naive_buffer/protobuf`
)
### `set_valid_places(valid_places)`
设置可用的places列表。
参数:
-
`valid_places(str)`
- 可用place列表,不同place用
`,`
隔开
示例:
```
python
# 引用Paddlelite预测库
from
paddlelite.lite
import
*
# 1. 创建opt实例
opt
=
Opt
()
# 2. 指定转化类型: arm、x86、opencl、xpu、npu
opt
.
set_valid_places
(
"arm, opencl"
)
```
### `set_optimize_out(optimized_model_name)`
设置优化后模型的名称,优化后模型文件以
`.nb`
作为文件后缀。
参数:
-
`optimized_model_name(str)`
### `run()`
执行模型优化,用以上接口设置完
`模型路径`
、
`model_type`
、
`optimize_out`
和
`valid_places`
后,执行
`run()`
接口会根据以上设置转化模型,转化后模型保存在当前路径下。
### `run_optimize(model_dir, model_file, param_file, type, valid_places, optimized_model_name)`
执行模型优化,无需设置以上接口,直接指定
`模型路径`
、
`model_type`
、
`optimize_out`
和
`valid_places`
并执行模型转化。
参数:
-
`model_dir(str)`
- 模型文件夹路径
-
`model_file(str)`
- 模型文件路径
-
`param_file(str)`
- 模型文件路径
-
`type(str)`
- 模型格式(
`naive_buffer/protobuf`
)
-
`valid_places(str)`
- 可用place列表,不同place用
`,`
隔开
-
`optimized_model_name(str)`
```
python
# 引用Paddlelite预测库
from
paddlelite.lite
import
*
# 1. 创建opt实例
opt
=
Opt
()
# 2. 执行模型优化
opt
.
run_optimize
(
"./mobilenet_v1"
,
""
,
""
,
"arm"
,
"mobilenetv1_opt"
);
```
docs/api_reference/python_api_doc.md
浏览文件 @
8dc7b259
# Python API
# Python API
## create_paddle_predictor
```
python
### [create_paddle_predictor](./python_api/create_paddle_predictor)
CxxPredictor
create_paddle_predictor
(
config
);
# config为CxxConfig类型
LightPredictor
create_paddle_predictor
(
config
);
# config为MobileConfig类型
```
`create_paddle_predictor`
函数用来根据
`CxxConfig`
或
`MobileConfig`
构建预测器。
创建预测执行器
[
`CxxPredictor`
](
./python_api/CxxPredictor
)
或者
[
`LightPredictor`
](
./python_api/LightPredictor
)
示例:
### [Opt](./python_api/opt)
```
python
```
python
from
lite_core
import
*
class
Opt
;
# 设置CxxConfig
config
=
CxxConfig
()
config
.
set_model_dir
(
<
your_model_dir_path
>
)
places
=
[
Place
(
TargetType
.
ARM
,
PrecisionType
.
FP32
)]
config
.
set_valid_places
(
places
)
# 根据CxxConfig创建CxxPredictor
predictor
=
create_paddle_predictor
(
config
)
```
```
参数:
`Opt`
模型离线优化接口,Paddle原生模型需经
`opt`
优化图结构后才能在Paddle-Lite上运行。
-
`config(CxxConfig或MobileConfig)`
- 用于构建Predictor的配置信息。
返回:预测器
`predictor`
返回类型:
`CxxPredictor`
或
`LightPredictor`
## CxxConfig
### [CxxConfig](./python_api/CxxConfig)
```
python
```
python
class
CxxConfig
;
class
CxxConfig
;
```
```
`CxxConfig`
用来配置构建CxxPredictor的配置信息,如protobuf格式的模型地址、能耗模式、工作线程数、place信息等等。
`CxxConfig`
用来配置构建CxxPredictor的配置信息,如protobuf格式的模型地址、能耗模式、工作线程数、place信息等等。
示例:
```
python
from
lite_core
import
*
config
=
CxxConfig
()
# 设置模型目录,加载非combined模型时使用
config
.
set_model_dir
(
<
your_model_dir_path
>
)
# 设置工作线程数
config
.
set_threads
(
4
);
# 设置能耗模式
config
.
set_power_mode
(
PowerMode
.
LITE_POWER_NO_BIND
)
# 设置valid places
places
=
[
Place
(
TargetType
.
ARM
,
PrecisionType
.
FP32
)]
config
.
set_valid_places
(
places
)
# 根据CxxConfig创建CxxPredictor
predictor
=
create_paddle_predictor
(
config
)
```
### `set_model_dir(model_dir)`
设置模型文件夹路径,当需要从磁盘加载非combined模型时使用。
参数:
-
`model_dir(str)`
- 模型文件夹路径
返回:
`None`
返回类型:
`None`
### `model_dir()`
返回设置的模型文件夹路径。
参数:
-
`None`
返回:模型文件夹路径
返回类型:
`str`
### `set_model_file(model_file)`
设置模型文件路径,加载combined形式模型时使用。
参数:
-
`model_file(str)`
- 模型文件路径
返回类型:
`None`
### `model_file()`
获取设置模型文件路径,加载combined形式模型时使用。
参数:
-
`None`
返回:模型文件路径
返回类型:
`str`
### `set_param_file(param_file)`
设置模型参数文件路径,加载combined形式模型时使用。
### [MobileConfig](./python_api/MobileConfig)
参数:
-
`param_file(str)`
- 模型文件路径
返回类型:
`None`
### `param_file()`
获取设置模型参数文件路径,加载combined形式模型时使用。
参数:
-
`None`
返回:模型参数文件路径
返回类型:
`str`
### `set_valid_places(valid_places)`
设置可用的places列表。
参数:
-
`valid_places(list)`
- 可用place列表。
返回类型:
`None`
示例:
```
python
from
lite_core
import
*
config
=
CxxConfig
()
# 设置模型目录,加载非combined模型时使用
config
.
set_model_dir
(
<
your_model_dir_path
>
)
# 设置valid places
# 注意,valid_places列表中Place的排序表明了用户对Place的偏好程度,如用户想优先使用ARM上Int8精度的
# kernel,则应把Place(TargetType.ARM, PrecisionType.INT8)置于valid_places列表的首位。
places
=
[
Place
(
TargetType
.
ARM
,
PrecisionType
.
INT8
),
Place
(
TargetType
.
ARM
,
PrecisionType
.
FP32
)]
config
.
set_valid_places
(
places
)
# 根据CxxConfig创建CxxPredictor
predictor
=
create_paddle_predictor
(
config
)
```
### `set_power_mode(mode)`
设置CPU能耗模式。若不设置,则默认使用
`PowerMode.LITE_POWER_HIGH`
。
*注意:只在开启`OpenMP`时生效,否则系统自动调度。此函数只在使用`LITE_WITH_ARM`编译选项下生效。*
参数:
-
`mode(PowerMode)`
- CPU能耗模式
返回:
`None`
返回类型:
`None`
### `power_mode()`
获取设置的CPU能耗模式。
*注意:此函数只在使用`LITE_WITH_ARM`编译选项下生效。*
参数:
-
`None`
返回:设置的CPU能耗模式
返回类型:
`PowerMode`
### `set_threads(threads)`
设置工作线程数。若不设置,则默认使用单线程。
*注意:只在开启`OpenMP`的模式下生效,否则只使用单线程。此函数只在使用`LITE_WITH_ARM`编译选项下生效。*
参数:
-
`threads(int)`
- 工作线程数
返回:
`None`
返回类型:
`None`
### `threads()`
获取设置的工作线程数。
*注意:此函数只在使用`LITE_WITH_ARM`编译选项下生效。*
参数:
-
`None`
返回:工作线程数
返回类型:
`int`
## MobileConfig
```
python
```
python
class
MobileConfig
;
class
MobileConfig
;
...
@@ -241,388 +29,31 @@ class MobileConfig;
...
@@ -241,388 +29,31 @@ class MobileConfig;
`MobileConfig`
用来配置构建LightPredictor的配置信息,如NaiveBuffer格式的模型地址、能耗模式、工作线程数等等。
`MobileConfig`
用来配置构建LightPredictor的配置信息,如NaiveBuffer格式的模型地址、能耗模式、工作线程数等等。
示例:
```
python
from
lite_core
import
*
config
=
MobileConfig
()
# 设置NaiveBuffer格式模型目录
config
.
set_model_from_file
(
<
your_model_path
>
)
# 设置工作线程数
config
.
set_threads
(
4
);
# 设置能耗模式
config
.
set_power_mode
(
PowerMode
.
LITE_POWER_NO_BIND
)
# 根据MobileConfig创建LightPredictor
predictor
=
create_paddle_predictor
(
config
)
```
### `set_model_from_file(model_file)`
**注意**
:
`model_file`
应该是经过
`opt`
优化后产生的
`NaiveBuffer`
格式的模型。
设置模型文件夹路径。
参数:
-
`model_file(str)`
- 模型文件路径
返回:
`None`
返回类型:
`None`
### `set_model_dir(model_dir)`
**注意**
:Lite模型格式在release/v2.3.0之后修改,本接口为加载老格式模型的接口,将在release/v3.0.0废弃。建议替换为
`setModelFromFile`
接口。
`model_dir`
应该是经过
`Model Optimize Tool`
优化后产生的
`NaiveBuffer`
格式的模型。
设置模型文件夹路径。
参数:
-
`model_dir(str)`
- 模型文件夹路径
返回:
`None`
返回类型:
`None`
### `set_model_from_buffer(model_buffer)`
设置模型的内存数据,当需要从内存加载模型时使用。
参数:
-
`model_buffer(str)`
- 内存中的模型数据
返回:
`None`
返回类型:
`void`
### `model_dir()`
返回设置的模型文件夹路径。
参数:
-
`None`
返回:模型文件夹路径
返回类型:
`str`
### `set_power_mode(mode)`
设置CPU能耗模式。若不设置,则默认使用
`PowerMode.LITE_POWER_HIGH`
。
*注意:只在开启`OpenMP`时生效,否则系统自动调度。此函数只在使用`LITE_WITH_ARM`编译选项下生效。*
参数:
-
`mode(PowerMode)`
- CPU能耗模式
返回:
`None`
返回类型:
`None`
### `power_mode()`
获取设置的CPU能耗模式。
*注意:此函数只在使用`LITE_WITH_ARM`编译选项下生效。*
参数:
-
`None`
返回:设置的CPU能耗模式
返回类型:
`PowerMode`
### `set_threads(threads)`
设置工作线程数。若不设置,则默认使用单线程。
*注意:只在开启`OpenMP`的模式下生效,否则只使用单线程。此函数只在使用`LITE_WITH_ARM`编译选项下生效。*
参数:
-
`threads(int)`
- 工作线程数
返回:
`None`
返回类型:
`None`
### `threads()`
获取设置的工作线程数。
*注意:此函数只在使用`LITE_WITH_ARM`编译选项下生效。*
参数:
-
`None`
### [CxxPredictor](./python_api/CxxPredictor)
返回:工作线程数
```
python
返回类型:
`int`
## CxxPredictor
```
c++
class
CxxPredictor
class
CxxPredictor
```
```
`CxxPredictor`
是Paddle-Lite的预测器,由
`create_paddle_predictor`
根据
`CxxConfig`
进行创建。用户可以根据CxxPredictor提供的接口设置输入数据、执行模型预测、获取输出以及获得当前使用lib的版本信息等。
`CxxPredictor`
是Paddle-Lite的预测器,由
`create_paddle_predictor`
根据
`CxxConfig`
进行创建。用户可以根据CxxPredictor提供的接口设置输入数据、执行模型预测、获取输出以及获得当前使用lib的版本信息等。
示例:
```
python
from
__future__
import
print_function
from
lite_core
import
*
# 1. 设置CxxConfig
config
=
CxxConfig
()
if
args
.
model_file
!=
''
and
args
.
param_file
!=
''
:
config
.
set_model_file
(
args
.
model_file
)
config
.
set_param_file
(
args
.
param_file
)
else
:
config
.
set_model_dir
(
args
.
model_dir
)
places
=
[
Place
(
TargetType
.
ARM
,
PrecisionType
.
FP32
)]
config
.
set_valid_places
(
places
)
# 2. 创建CxxPredictor
predictor
=
create_paddle_predictor
(
config
)
# 3. 设置输入数据
input_tensor
=
predictor
.
get_input
(
0
)
input_tensor
.
resize
([
1
,
3
,
224
,
224
])
input_tensor
.
set_float_data
([
1.
]
*
3
*
224
*
224
)
# 4. 运行模型
predictor
.
run
()
# 5. 获取输出数据
output_tensor
=
predictor
.
get_output
(
0
)
print
(
output_tensor
.
shape
())
print
(
output_tensor
.
float_data
()[:
10
])
```
### `get_input(index)`
获取输入Tensor,用来设置模型的输入数据。
参数:
-
`index(int)`
- 输入Tensor的索引
返回:第
`index`
个输入
`Tensor`
返回类型:
`Tensor`
### `get_output(index)`
获取输出Tensor,用来获取模型的输出结果。
参数:
-
`index(int)`
- 输出Tensor的索引
返回:第
`index`
个输出
`Tensor`
返回类型:
`Tensor`
### `run()`
执行模型预测,需要在
***设置输入数据后**
*
调用。
参数:
-
`None`
返回:
`None`
返回类型:
`None`
### `get_version()`
用于获取当前lib使用的代码版本。若代码有相应tag则返回tag信息,如
`v2.0-beta`
;否则返回代码的
`branch(commitid)`
,如
`develop(7e44619)`
。
参数:
-
`None`
返回:当前lib使用的代码版本信息
返回类型:
`str`
## LightPredictor
```
c++
class
LightPredictor
```
`LightPredictor`
是Paddle-Lite的预测器,由
`create_paddle_predictor`
根据
`MobileConfig`
进行创建。用户可以根据LightPredictor提供的接口设置输入数据、执行模型预测、获取输出以及获得当前使用lib的版本信息等。
示例:
```
python
from
__future__
import
print_function
from
lite_core
import
*
# 1. 设置MobileConfig
config
=
MobileConfig
()
config
.
set_model_dir
(
args
.
model_dir
)
# 2. 创建LightPredictor
predictor
=
create_paddle_predictor
(
config
)
# 3. 设置输入数据
input_tensor
=
predictor
.
get_input
(
0
)
input_tensor
.
resize
([
1
,
3
,
224
,
224
])
input_tensor
.
set_float_data
([
1.
]
*
3
*
224
*
224
)
# 4. 运行模型
predictor
.
run
()
# 5. 获取输出数据
output_tensor
=
predictor
.
get_output
(
0
)
print
(
output_tensor
.
shape
())
print
(
output_tensor
.
float_data
()[:
10
])
```
### `get_input(index)`
获取输入Tensor,用来设置模型的输入数据。
参数:
-
`index(int)`
- 输入Tensor的索引
返回:第
`index`
个输入
`Tensor`
返回类型:
`Tensor`
### `get_output(index)`
获取输出Tensor,用来获取模型的输出结果。
参数:
-
`index(int)`
- 输出Tensor的索引
返回:第
`index`
个输出
`Tensor`
返回类型:
`Tensor`
### [TargetType 、PrecisionType、DataLayoutType、Place](./python_api/TypePlace)
### `run()`
执行模型预测,需要在
***设置输入数据后**
*
调用。
参数:
-
`None`
返回:
`None`
返回类型:
`None`
### `get_version()`
用于获取当前lib使用的代码版本。若代码有相应tag则返回tag信息,如
`v2.0-beta`
;否则返回代码的
`branch(commitid)`
,如
`develop(7e44619)`
。
参数:
-
`None`
返回:当前lib使用的代码版本信息
返回类型:
`str`
## TargetType
```
python
class
TargetType
;
```
`TargetType`
为目标设备硬件类型,用户可以根据应用场景选择硬件平台类型。
`TargetType`
为目标设备硬件类型,用户可以根据应用场景选择硬件平台类型。
枚举型变量
`TargetType`
的所有可能取值包括:
`{X86, CUDA, ARM, OpenCL, FPGA, NPU}`
## PrecisionType
```
python
class
PrecisionType
{
FP32
};
```
`PrecisionType`
为模型中Tensor的数据精度,默认值为FP32(float32)。
`PrecisionType`
为模型中Tensor的数据精度,默认值为FP32(float32)。
枚举型变量
`PrecisionType`
的所有可能取值包括:
`{FP32, INT8, INT32, INT64}`
## DataLayoutType
```
python
class
DataLayoutType
{
NCHW
};
```
`DataLayoutType`
为Tensor的数据格式,默认值为NCHW(number, channel, height, weigth)。
`DataLayoutType`
为Tensor的数据格式,默认值为NCHW(number, channel, height, weigth)。
枚举型变量
`DataLayoutType`
的所有可能取值包括:
` {NCHW, NHWC}`
## Place
```
python
class
Place
{
TargetType
target
;
PrecisionType
precision
{
FP32
};
DataLayoutType
layout
{
NCHW
}
}
```
`Place`
是
`TargetType`
、
`PrecisionType`
和
`DataLayoutType`
的集合,说明运行时的设备类型、数据精度和数据格式。
`Place`
是
`TargetType`
、
`PrecisionType`
和
`DataLayoutType`
的集合,说明运行时的设备类型、数据精度和数据格式。
示例:
```
python
from
lite_core
import
*
Place
{
TargetType
(
ARM
),
PrecisionType
(
FP32
),
DataLayoutType
(
NCHW
)}
```
##
PowerMode
##
# [PowerMode](./python_api/PowerMode)
```
python
```
python
class
PowerMode
;
class
PowerMode
;
...
@@ -630,35 +61,9 @@ class PowerMode;
...
@@ -630,35 +61,9 @@ class PowerMode;
`PowerMode`
为ARM CPU能耗模式,用户可以根据应用场景设置能耗模式获得最优的能效比。
`PowerMode`
为ARM CPU能耗模式,用户可以根据应用场景设置能耗模式获得最优的能效比。
示例:
```
python
from
lite_core
import
*
config
=
MobileConfig
()
### [Tensor](./python_api/Tensor)
# 设置NaiveBuffer格式模型目录
config
.
set_model_dir
(
<
your_model_dir_path
>
)
# 设置能耗模式
config
.
set_power_mode
(
PowerMode
.
LITE_POWER_NO_BIND
)
# 根据MobileConfig创建LightPredictor
predictor
=
create_paddle_predictor
(
config
)
```
PowerMode详细说明如下:
| 选项 | 说明 |
| :------------------: | ------------------------------------------------------------ |
| LITE_POWER_HIGH | 绑定大核运行模式。如果ARM CPU支持big.LITTLE,则优先使用并绑定Big cluster。如果设置的线程数大于大核数量,则会将线程数自动缩放到大核数量。如果系统不存在大核或者在一些手机的低电量情况下会出现绑核失败,如果失败则进入不绑核模式。 |
| LITE_POWER_LOW | 绑定小核运行模式。如果ARM CPU支持big.LITTLE,则优先使用并绑定Little cluster。如果设置的线程数大于小核数量,则会将线程数自动缩放到小核数量。如果找不到小核,则自动进入不绑核模式。 |
| LITE_POWER_FULL | 大小核混用模式。线程数可以大于大核数量。当线程数大于核心数量时,则会自动将线程数缩放到核心数量。 |
| LITE_POWER_NO_BIND | 不绑核运行模式(推荐)。系统根据负载自动调度任务到空闲的CPU核心上。 |
| LITE_POWER_RAND_HIGH | 轮流绑定大核模式。如果Big cluster有多个核心,则每预测10次后切换绑定到下一个核心。 |
| LITE_POWER_RAND_LOW | 轮流绑定小核模式。如果Little cluster有多个核心,则每预测10次后切换绑定到下一个核心。 |
## Tensor
```
c++
```
c++
class
Tensor
class
Tensor
...
@@ -667,134 +72,3 @@ class Tensor
...
@@ -667,134 +72,3 @@ class Tensor
Tensor是Paddle-Lite的数据组织形式,用于对底层数据进行封装并提供接口对数据进行操作,包括设置Shape、数据、LoD信息等。
Tensor是Paddle-Lite的数据组织形式,用于对底层数据进行封装并提供接口对数据进行操作,包括设置Shape、数据、LoD信息等。
*注意:用户应使用`CxxPredictor`或`LightPredictor`的`get_input`和`get_output`接口获取输入/输出的`Tensor`。*
*注意:用户应使用`CxxPredictor`或`LightPredictor`的`get_input`和`get_output`接口获取输入/输出的`Tensor`。*
示例:
```
python
from
__future__
import
print_function
from
lite_core
import
*
# 1. 设置CxxConfig
config
=
CxxConfig
()
if
args
.
model_file
!=
''
and
args
.
param_file
!=
''
:
config
.
set_model_file
(
args
.
model_file
)
config
.
set_param_file
(
args
.
param_file
)
else
:
config
.
set_model_dir
(
args
.
model_dir
)
places
=
[
Place
(
TargetType
.
ARM
,
PrecisionType
.
FP32
)]
config
.
set_valid_places
(
places
)
# 2. 创建CxxPredictor
predictor
=
create_paddle_predictor
(
config
)
# 3. 设置输入数据
input_tensor
=
predictor
.
get_input
(
0
)
input_tensor
.
resize
([
1
,
3
,
224
,
224
])
input_tensor
.
set_float_data
([
1.
]
*
3
*
224
*
224
)
# 4. 运行模型
predictor
.
run
()
# 5. 获取输出数据
output_tensor
=
predictor
.
get_output
(
0
)
print
(
output_tensor
.
shape
())
print
(
output_tensor
.
float_data
()[:
10
])
```
### `resize(shape)`
设置Tensor的维度信息。
参数:
-
`shape(list)`
- 维度信息
返回:
`None`
返回类型:
`None`
### `shape()`
获取Tensor的维度信息。
参数:
-
`None`
返回:Tensor的维度信息
返回类型:
`list`
### `float_data()`
获取Tensor的持有的float型数据。
示例:
```
python
output_tensor
=
predictor
.
get_output
(
0
)
print
(
output_tensor
.
shape
())
print
(
output_tensor
.
float_data
()[:
10
])
```
参数:
-
`None`
返回:
`Tensor`
持有的float型数据
返回类型:
`list`
### `set_float_data(float_data)`
设置Tensor持有float数据。
示例:
```
python
input_tensor
=
predictor
.
get_input
(
0
)
input_tensor
.
resize
([
1
,
3
,
224
,
224
])
input_tensor
.
set_float_data
([
1.
]
*
3
*
224
*
224
)
```
参数:
-
`float_data(list)`
- 待设置的float型数据
返回:
`None`
返回类型:
`None`
### `set_lod(lod)`
设置Tensor的LoD信息。
参数:
-
`lod(list[list])`
- Tensor的LoD信息
返回:
`None`
返回类型:
`None`
### `lod()`
获取Tensor的LoD信息
参数:
-
`None`
返回:
`Tensor`
的LoD信息
返回类型:
`list[list]`
docs/user_guides/model_optimize_tool.md
浏览文件 @
8dc7b259
...
@@ -5,168 +5,57 @@ Paddle-Lite 提供了多种策略来自动优化原始的训练模型,其中
...
@@ -5,168 +5,57 @@ Paddle-Lite 提供了多种策略来自动优化原始的训练模型,其中
具体使用方法介绍如下:
具体使用方法介绍如下:
**注意**
:
`v2.2.0`
之前的模型转化工具名称为
`model_optimize_tool`
,从
`v2.3`
开始模型转化工具名称修改为
`opt`
**注意**
:
`v2.2.0`
之前的模型转化工具名称为
`model_optimize_tool`
,从
`v2.3`
开始模型转化工具名称修改为
`opt`
,从
`v2.6.0`
开始支持python调用
`opt`
转化模型(Windows/Ubuntu/Mac)
## 准备opt
## 准备opt
当前获得
opt
方法有三种:
当前获得
`opt`
工具的
方法有三种:
1.
**推荐!**
可以进入Paddle-Lite Github仓库的
[
release界面
](
https://github.com/PaddlePaddle/Paddle-Lite/releases
)
,选择release版本下载对应的转化工具
`opt`
-
方法一: 安装opt的python版本
(release/v2.2.0之前的转化工具为model_optimize_tool、release/v2.3.0之后为opt)
2.
本文提供
`release/v2.3`
和
`release/v2.2.0`
版本的优化工具下载
|版本 | Linux | MacOS|
安装
`paddlelite`
python库,安装成功后调用opt转化模型(支持
`windows\Mac\Ubuntu`
)
|---|---|---|
|
`release/v2.3`
|
[
opt
](
https://paddlelite-data.bj.bcebos.com/model_optimize_tool/opt
)
|
[
opt_mac
](
https://paddlelite-data.bj.bcebos.com/model_optimize_tool/opt_mac
)
|
|
`release/v2.2.0`
|
[
model_optimize_tool
](
https://paddlelite-data.bj.bcebos.com/model_optimize_tool/model_optimize_tool
)
|
[
model_optimize_tool_mac
](
https://paddlelite-data.bj.bcebos.com/model_optimize_tool/model_optimize_tool_mac
)
|
3.
如果 release 列表里的工具不符合您的环境,可以下载Paddle-Lite 源码,源码编译出opt工具
```
bash
git clone https://github.com/PaddlePaddle/Paddle-Lite.git
cd
Paddle-Lite
git checkout <release-version-tag>
./lite/tools/build.sh build_optimize_tool
```
编译结果位于
`Paddle-Lite/build.opt/lite/api/opt`
**注意**
:从源码编译opt前需要先
[
安装Paddle-Lite的开发环境
](
source_compile
)
。
## 使用opt
opt是 x86 平台上的可执行文件,需要在PC端运行:支持Linux终端和Mac终端。
### 帮助信息
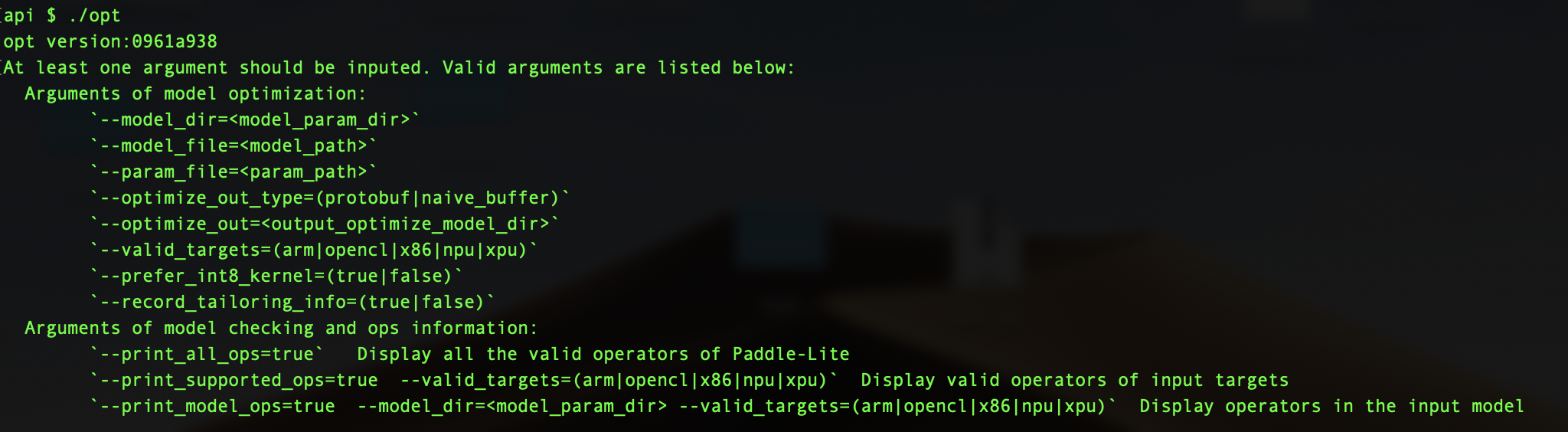
执行opt时不加入任何输入选项,会输出帮助信息,提示当前支持的选项:
```
bash
```
bash
./opt
pip
install
paddlelite
```
```
### 功能一:转化模型为Paddle-Lite格式
-
方法二: 下载opt可执行文件
opt可以将PaddlePaddle的部署模型格式转化为Paddle-Lite 支持的模型格式,期间执行的操作包括:
从
[
release界面
](
https://github.com/PaddlePaddle/Paddle-Lite/releases
)
,选择当前预测库对应版本的
`opt`
转化工具
-
将protobuf格式的模型文件转化为naive_buffer格式的模型文件,有效降低模型体积
本文提供
`release/v2.6`
和
`release/v2.2.0`
版本的优化工具下载
-
执行“量化、子图融合、混合调度、Kernel优选”等图优化操作,提升其在Paddle-Lite上的运行速度、内存占用等效果
模型优化过程:
|版本 | Linux | MacOS|
|---|---|---|
(1)准备待优化的PaddlePaddle模型
|
`release/v2.3`
|
[
opt
](
https://paddlelite-data.bj.bcebos.com/model_optimize_tool/opt
)
|
[
opt_mac
](
https://paddlelite-data.bj.bcebos.com/model_optimize_tool/opt_mac
)
|
|
`release/v2.2.0`
|
[
model_optimize_tool
](
https://paddlelite-data.bj.bcebos.com/model_optimize_tool/model_optimize_tool
)
|
[
model_optimize_tool_mac
](
https://paddlelite-data.bj.bcebos.com/model_optimize_tool/model_optimize_tool_mac
)
|
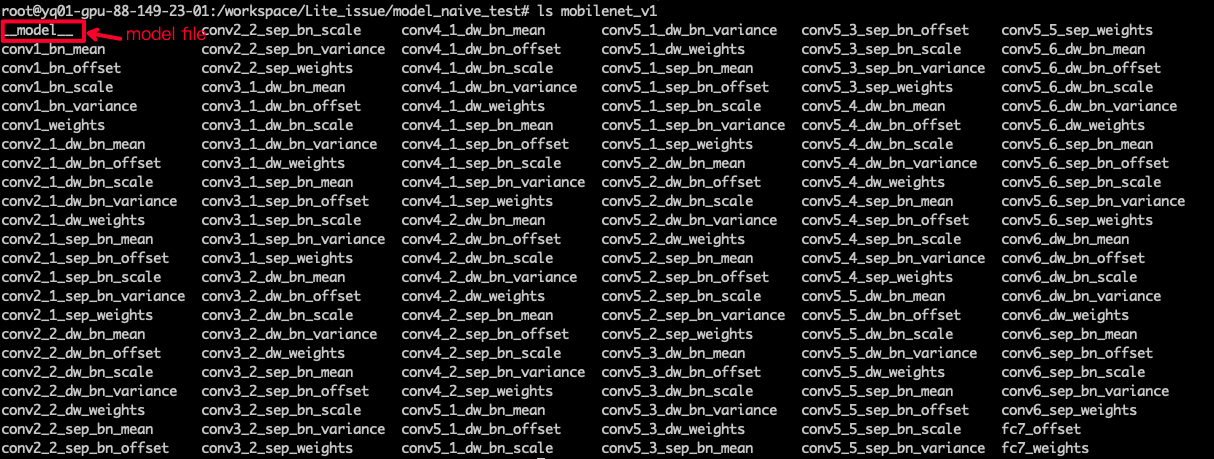
PaddlePaddle模型有两种保存格式:
Combined Param:所有参数信息保存在单个文件
`params`
中,模型的拓扑信息保存在
`__model__`
文件中。

Seperated Param:参数信息分开保存在多个参数文件中,模型的拓扑信息保存在
`__model__`
文件中。
(2) 终端中执行
`opt`
优化模型
-
方法三: 源码编译opt
**使用示例**
:转化
`mobilenet_v1`
模型
源码编译 opt 可执行文件
```
```
./opt --model_dir=./mobilenet_v1 \
cd Paddle-Lite && ./lite/tools/build.sh build_optimize_tool
--valid_targets=arm \
--optimize_out_type=naive_buffer \
--optimize_out=mobilenet_v1_opt
```
```
以上命令可以将
`mobilenet_v1`
模型转化为arm硬件平台、naive_buffer格式的Paddle_Lite支持模型,优化后的模型文件为
`mobilenet_v1_opt.nb`
,转化结果如下图所示:

编译结果位于
`build.opt/lite/api/`
下的可执行文件
`opt`
## 使用opt
当前使用
`opt`
工具转化模型的方法有以下三种:
(3)
**更详尽的转化命令**
总结:
-
方法一:
[
安装 python版本opt后,使用终端命令
](
./opt/opt_python
)
(支持Mac/Ubuntu)
-
方法二:
[
安装python版本opt后,使用python脚本
](
../api_reference/python_api/opt
)
(支持window/Mac/Ubuntu)
-
方法三:
[
直接下载并执行opt可执行工具
](
./opt/opt_bin
)
(支持Mac/Ubuntu)
-
Q&A:如何安装python版本opt ?
可以通过以下命令安装paddlelite的python库(支持
`windows/Mac/Ubuntu`
):
```
shell
```
shell
./opt
\
pip
install
paddlelite
--model_dir
=
<model_param_dir>
\
--model_file
=
<model_path>
\
--param_file
=
<param_path>
\
--optimize_out_type
=(
protobuf|naive_buffer
)
\
--optimize_out
=
<output_optimize_model_dir>
\
--valid_targets
=(
arm|opencl|x86|npu|xpu
)
\
--record_tailoring_info
=(
true
|false
)
```
```
| 选项 | 说明 |
| ------------------- | ------------------------------------------------------------ |
| --model_dir | 待优化的PaddlePaddle模型(非combined形式)的路径 |
| --model_file | 待优化的PaddlePaddle模型(combined形式)的网络结构文件路径。 |
| --param_file | 待优化的PaddlePaddle模型(combined形式)的权重文件路径。 |
| --optimize_out_type | 输出模型类型,目前支持两种类型:protobuf和naive_buffer,其中naive_buffer是一种更轻量级的序列化/反序列化实现。若您需要在mobile端执行模型预测,请将此选项设置为naive_buffer。默认为protobuf。 |
| --optimize_out | 优化模型的输出路径。 |
| --valid_targets | 指定模型可执行的backend,默认为arm。目前可支持x86、arm、opencl、npu、xpu,可以同时指定多个backend(以空格分隔),Model Optimize Tool将会自动选择最佳方式。如果需要支持华为NPU(Kirin 810/990 Soc搭载的达芬奇架构NPU),应当设置为npu, arm。 |
| --record_tailoring_info | 当使用
[
根据模型裁剪库文件
](
./library_tailoring.html
)
功能时,则设置该选项为true,以记录优化后模型含有的kernel和OP信息,默认为false。 |
*
如果待优化的fluid模型是非combined形式,请设置
`--model_dir`
,忽略
`--model_file`
和
`--param_file`
。
*
如果待优化的fluid模型是combined形式,请设置
`--model_file`
和
`--param_file`
,忽略
`--model_dir`
。
*
优化后的模型为以
`.nb`
名称结尾的单个文件。
*
删除
`prefer_int8_kernel`
的输入参数,
`opt`
自动判别是否是量化模型,进行相应的优化操作。
### 功能二:统计模型算子信息、判断是否支持
## 合并x2paddle和opt的一键脚本
opt可以统计并打印出model中的算子信息、判断Paddle-Lite是否支持该模型。并可以打印出当前Paddle-Lite的算子支持情况。
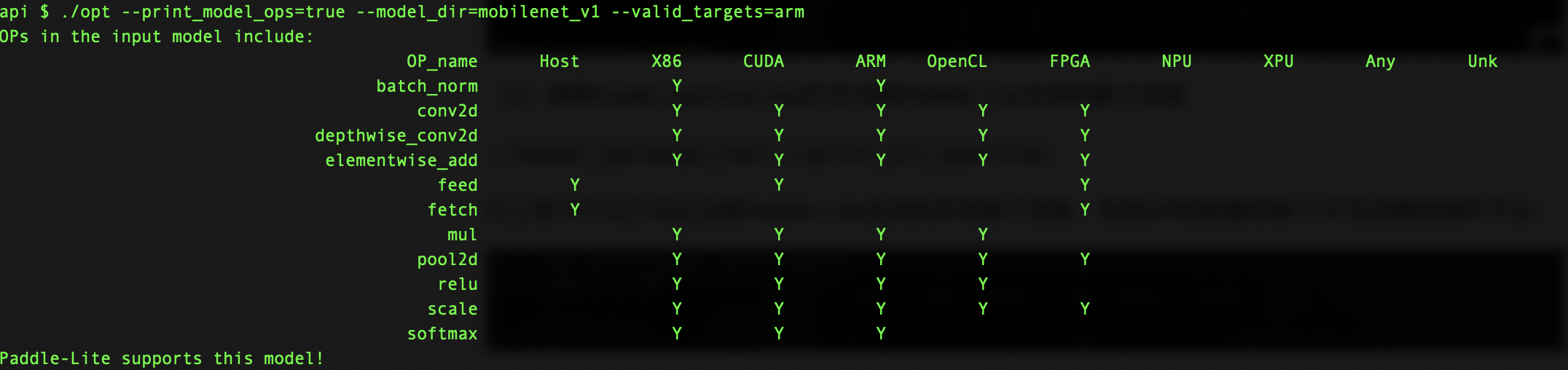
(1)使用opt统计模型中算子信息
下面命令可以打印出mobilenet_v1模型中包含的所有算子,并判断在硬件平台
`valid_targets`
下Paddle-Lite是否支持该模型
`./opt --print_model_ops=true --model_dir=mobilenet_v1 --valid_targets=arm`
(2)使用opt打印当前Paddle-Lite支持的算子信息
`./opt --print_all_ops=true`
以上命令可以打印出当前Paddle-Lite支持的所有算子信息,包括OP的数量和每个OP支持哪些硬件平台:

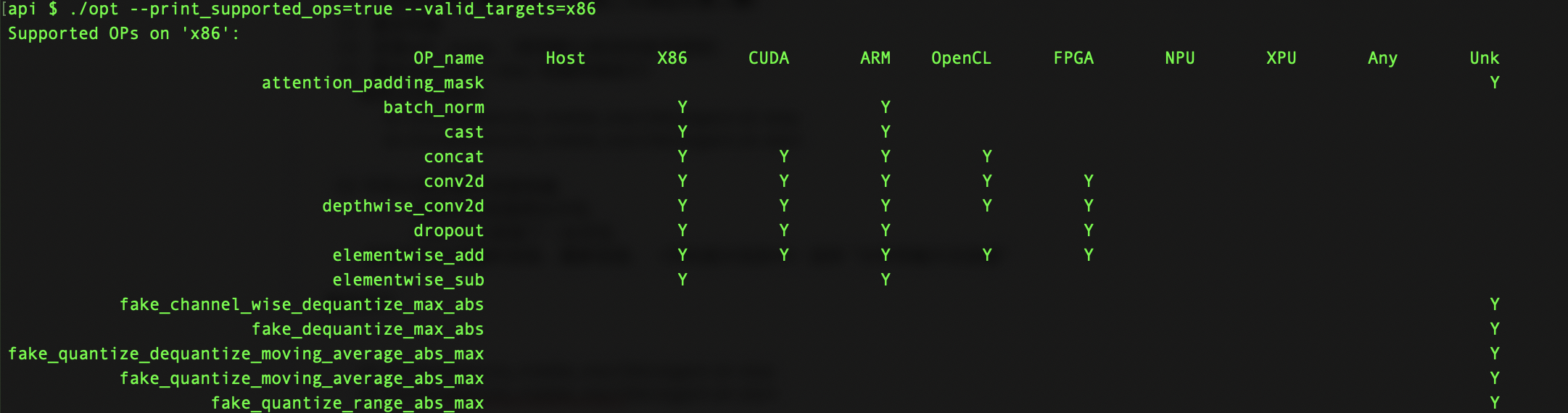
`./opt ----print_supported_ops=true --valid_targets=x86`
以上命令可以打印出当
`valid_targets=x86`
时Paddle-Lite支持的所有OP:
## 其他功能:合并x2paddle和opt的一键脚本
**背景**
:如果想用Paddle-Lite运行第三方来源(tensorflow、caffe、onnx)模型,一般需要经过两次转化。即使用x2paddle工具将第三方模型转化为PaddlePaddle格式,再使用opt将PaddlePaddle模型转化为Padde-Lite可支持格式。
**背景**
:如果想用Paddle-Lite运行第三方来源(tensorflow、caffe、onnx)模型,一般需要经过两次转化。即使用x2paddle工具将第三方模型转化为PaddlePaddle格式,再使用opt将PaddlePaddle模型转化为Padde-Lite可支持格式。
为了简化这一过程,我们提供一键脚本,将x2paddle转化和opt转化合并:
为了简化这一过程,我们提供了:
**一键转化脚本**
:
[
auto_transform.sh
](
https://github.com/PaddlePaddle/Paddle-Lite/blob/release/v2.3/lite/tools/auto_transform.sh
)
**环境要求**
:使用
`auto_transform.sh`
脚本转化第三方模型时,需要先安装x2paddle环境,请参考
[
x2paddle环境安装方法
](
https://github.com/PaddlePaddle/X2Paddle#环境依赖
)
安装x2paddle和x2paddle依赖项(tensorflow、caffe等)。
**使用方法**
:
[
合并x2paddle和opt的一键脚本
](
./opt/x2paddle&opt
)
(1)打印帮助帮助信息:
` sh ./auto_transform.sh`
(2)转化模型方法
```
bash
USAGE:
auto_transform.sh combines the
function
of x2paddle and opt, it can
tranform model from tensorflow/caffe/onnx form into paddle-lite naive-buffer form.
----------------------------------------
example:
sh ./auto_transform.sh
--framework
=
tensorflow
--model
=
tf_model.pb
--optimize_out
=
opt_model_result
----------------------------------------
Arguments about x2paddle:
--framework
=(
tensorflow|caffe|onnx
)
;
--model
=
'model file for tensorflow or onnx'
;
--prototxt
=
'proto file for caffe'
--weight
=
'weight file for caffe'
For TensorFlow:
--framework
=
tensorflow
--model
=
tf_model.pb
For Caffe:
--framework
=
caffe
--prototxt
=
deploy.prototxt
--weight
=
deploy.caffemodel
For ONNX
--framework
=
onnx
--model
=
onnx_model.onnx
Arguments about opt:
--valid_targets
=(
arm|opencl|x86|npu|xpu
)
;
valid targets on Paddle-Lite.
--fluid_save_dir
=
'path to outputed model after x2paddle'
--optimize_out
=
'path to outputed Paddle-Lite model'
----------------------------------------
```
docs/user_guides/opt/opt_bin.md
0 → 100644
浏览文件 @
8dc7b259
## 使用opt转化模型
opt是 x86 平台上的可执行文件,需要在PC端运行:支持Linux终端和Mac终端。
### 帮助信息
执行opt时不加入任何输入选项,会输出帮助信息,提示当前支持的选项:
```
bash
./opt
```

### 功能一:转化模型为Paddle-Lite格式
opt可以将PaddlePaddle的部署模型格式转化为Paddle-Lite 支持的模型格式,期间执行的操作包括:
-
将protobuf格式的模型文件转化为naive_buffer格式的模型文件,有效降低模型体积
-
执行“量化、子图融合、混合调度、Kernel优选”等图优化操作,提升其在Paddle-Lite上的运行速度、内存占用等效果
模型优化过程:
(1)准备待优化的PaddlePaddle模型
PaddlePaddle模型有两种保存格式:
Combined Param:所有参数信息保存在单个文件
`params`
中,模型的拓扑信息保存在
`__model__`
文件中。

Seperated Param:参数信息分开保存在多个参数文件中,模型的拓扑信息保存在
`__model__`
文件中。

(2) 终端中执行
`opt`
优化模型
**使用示例**
:转化
`mobilenet_v1`
模型
```
shell
paddle_lite_opt
--model_dir
=
./mobilenet_v1
\
--valid_targets
=
arm
\
--optimize_out_type
=
naive_buffer
\
--optimize_out
=
mobilenet_v1_opt
```
以上命令可以将
`mobilenet_v1`
模型转化为arm硬件平台、naive_buffer格式的Paddle_Lite支持模型,优化后的模型文件为
`mobilenet_v1_opt.nb`
,转化结果如下图所示:

(3)
**更详尽的转化命令**
总结:
```
shell
paddle_lite_opt
\
--model_dir
=
<model_param_dir>
\
--model_file
=
<model_path>
\
--param_file
=
<param_path>
\
--optimize_out_type
=(
protobuf|naive_buffer
)
\
--optimize_out
=
<output_optimize_model_dir>
\
--valid_targets
=(
arm|opencl|x86|npu|xpu
)
\
--record_tailoring_info
=(
true
|false
)
```
| 选项 | 说明 |
| ------------------- | ------------------------------------------------------------ |
| --model_dir | 待优化的PaddlePaddle模型(非combined形式)的路径 |
| --model_file | 待优化的PaddlePaddle模型(combined形式)的网络结构文件路径。 |
| --param_file | 待优化的PaddlePaddle模型(combined形式)的权重文件路径。 |
| --optimize_out_type | 输出模型类型,目前支持两种类型:protobuf和naive_buffer,其中naive_buffer是一种更轻量级的序列化/反序列化实现。若您需要在mobile端执行模型预测,请将此选项设置为naive_buffer。默认为protobuf。 |
| --optimize_out | 优化模型的输出路径。 |
| --valid_targets | 指定模型可执行的backend,默认为arm。目前可支持x86、arm、opencl、npu、xpu,可以同时指定多个backend(以空格分隔),Model Optimize Tool将会自动选择最佳方式。如果需要支持华为NPU(Kirin 810/990 Soc搭载的达芬奇架构NPU),应当设置为npu, arm。 |
| --record_tailoring_info | 当使用
[
根据模型裁剪库文件
](
./library_tailoring.html
)
功能时,则设置该选项为true,以记录优化后模型含有的kernel和OP信息,默认为false。 |
*
如果待优化的fluid模型是非combined形式,请设置
`--model_dir`
,忽略
`--model_file`
和
`--param_file`
。
*
如果待优化的fluid模型是combined形式,请设置
`--model_file`
和
`--param_file`
,忽略
`--model_dir`
。
*
优化后的模型为以
`.nb`
名称结尾的单个文件。
*
删除
`prefer_int8_kernel`
的输入参数,
`opt`
自动判别是否是量化模型,进行相应的优化操作。
### 功能二:统计模型算子信息、判断是否支持
opt可以统计并打印出model中的算子信息、判断Paddle-Lite是否支持该模型。并可以打印出当前Paddle-Lite的算子支持情况。
(1)使用opt统计模型中算子信息
下面命令可以打印出mobilenet_v1模型中包含的所有算子,并判断在硬件平台
`valid_targets`
下Paddle-Lite是否支持该模型
`./opt --print_model_ops=true --model_dir=mobilenet_v1 --valid_targets=arm`

(2)使用opt打印当前Paddle-Lite支持的算子信息
`./opt --print_all_ops=true`
以上命令可以打印出当前Paddle-Lite支持的所有算子信息,包括OP的数量和每个OP支持哪些硬件平台:

`./opt --print_supported_ops=true --valid_targets=x86`
以上命令可以打印出当
`valid_targets=x86`
时Paddle-Lite支持的所有OP:

docs/user_guides/opt/opt_python.md
0 → 100644
浏览文件 @
8dc7b259
## python调用opt转化模型
安装了paddle-lite 的python库后,可以通过python调用 opt 工具转化模型。(支持MAC&Ubuntu系统)
### 安装Paddle-Lite
```
pip install paddlelite
```
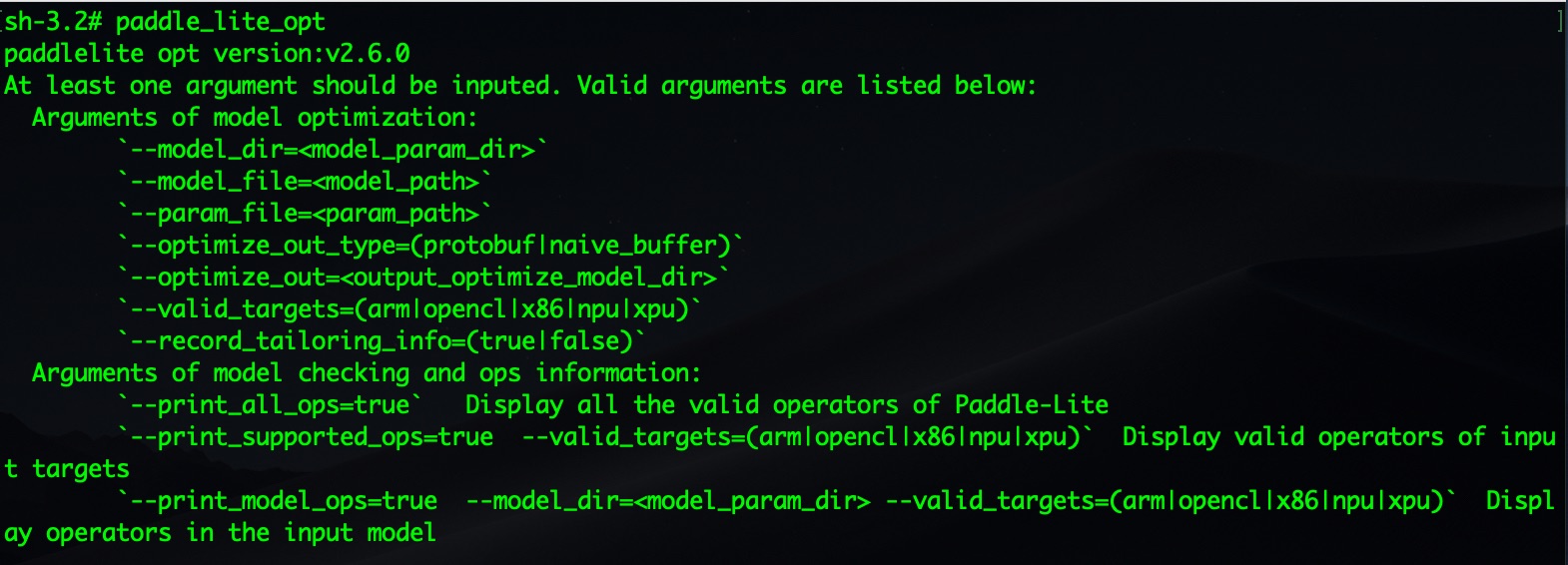
### 帮助信息
安装成功后可以查看帮助信息
```
bash
paddle_lite_opt
```
### 功能一:转化模型为Paddle-Lite格式
opt可以将PaddlePaddle的部署模型格式转化为Paddle-Lite 支持的模型格式,期间执行的操作包括:
-
将protobuf格式的模型文件转化为naive_buffer格式的模型文件,有效降低模型体积
-
执行“量化、子图融合、混合调度、Kernel优选”等图优化操作,提升其在Paddle-Lite上的运行速度、内存占用等效果
模型优化过程:
(1)准备待优化的PaddlePaddle模型
PaddlePaddle模型有两种保存格式:
Combined Param:所有参数信息保存在单个文件
`params`
中,模型的拓扑信息保存在
`__model__`
文件中。

Seperated Param:参数信息分开保存在多个参数文件中,模型的拓扑信息保存在
`__model__`
文件中。

(2) 终端中执行
`opt`
优化模型
**使用示例**
:转化
`mobilenet_v1`
模型
```
paddle_lite_opt --model_dir=./mobilenet_v1 \
--valid_targets=arm \
--optimize_out_type=naive_buffer \
--optimize_out=mobilenet_v1_opt
```
以上命令可以将
`mobilenet_v1`
模型转化为arm硬件平台、naive_buffer格式的Paddle_Lite支持模型,优化后的模型文件为
`mobilenet_v1_opt.nb`
,转化结果如下图所示:

(3)
**更详尽的转化命令**
总结:
```
shell
paddle_lite_opt
\
--model_dir
=
<model_param_dir>
\
--model_file
=
<model_path>
\
--param_file
=
<param_path>
\
--optimize_out_type
=(
protobuf|naive_buffer
)
\
--optimize_out
=
<output_optimize_model_dir>
\
--valid_targets
=(
arm|opencl|x86|npu|xpu
)
\
--record_tailoring_info
=(
true
|false
)
```
| 选项 | 说明 |
| ------------------- | ------------------------------------------------------------ |
| --model_dir | 待优化的PaddlePaddle模型(非combined形式)的路径 |
| --model_file | 待优化的PaddlePaddle模型(combined形式)的网络结构文件路径。 |
| --param_file | 待优化的PaddlePaddle模型(combined形式)的权重文件路径。 |
| --optimize_out_type | 输出模型类型,目前支持两种类型:protobuf和naive_buffer,其中naive_buffer是一种更轻量级的序列化/反序列化实现。若您需要在mobile端执行模型预测,请将此选项设置为naive_buffer。默认为protobuf。 |
| --optimize_out | 优化模型的输出路径。 |
| --valid_targets | 指定模型可执行的backend,默认为arm。目前可支持x86、arm、opencl、npu、xpu,可以同时指定多个backend(以空格分隔),Model Optimize Tool将会自动选择最佳方式。如果需要支持华为NPU(Kirin 810/990 Soc搭载的达芬奇架构NPU),应当设置为npu, arm。 |
| --record_tailoring_info | 当使用
[
根据模型裁剪库文件
](
./library_tailoring.html
)
功能时,则设置该选项为true,以记录优化后模型含有的kernel和OP信息,默认为false。 |
*
如果待优化的fluid模型是非combined形式,请设置
`--model_dir`
,忽略
`--model_file`
和
`--param_file`
。
*
如果待优化的fluid模型是combined形式,请设置
`--model_file`
和
`--param_file`
,忽略
`--model_dir`
。
*
优化后的模型为以
`.nb`
名称结尾的单个文件。
*
删除
`prefer_int8_kernel`
的输入参数,
`opt`
自动判别是否是量化模型,进行相应的优化操作。
### 功能二:统计模型算子信息、判断是否支持
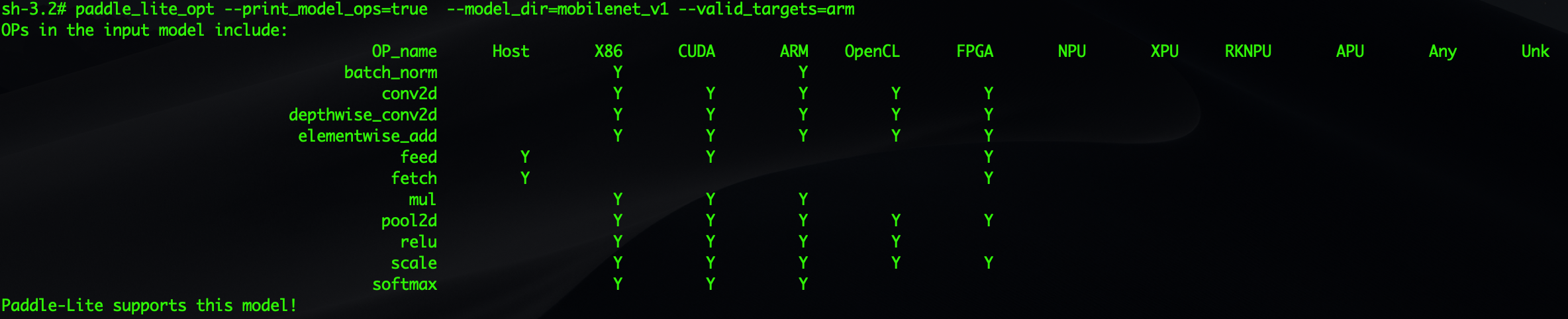
opt可以统计并打印出model中的算子信息、判断Paddle-Lite是否支持该模型。并可以打印出当前Paddle-Lite的算子支持情况。
(1)使用opt统计模型中算子信息
下面命令可以打印出mobilenet_v1模型中包含的所有算子,并判断在硬件平台
`valid_targets`
下Paddle-Lite是否支持该模型
`paddle_lite_opt --print_model_ops=true --model_dir=mobilenet_v1 --valid_targets=arm`
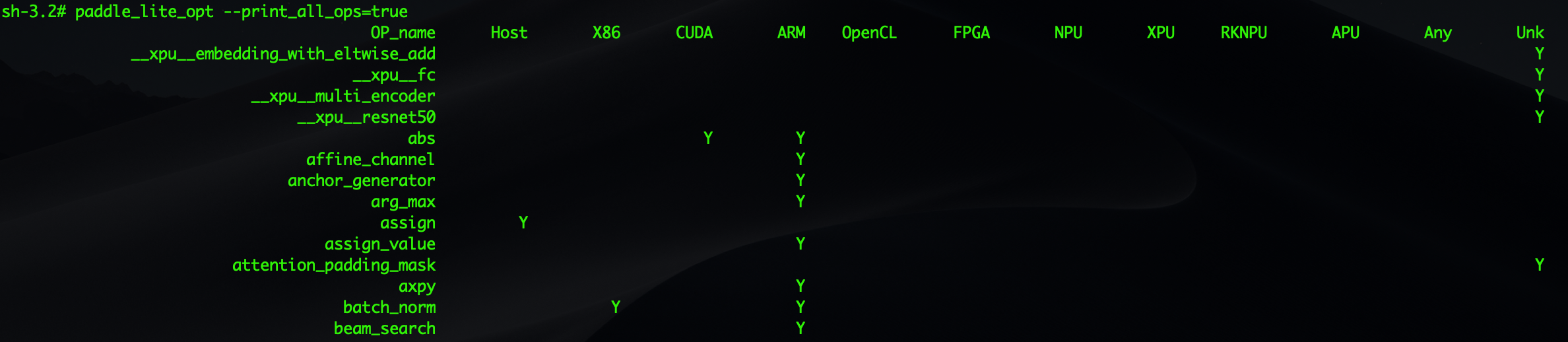
(2)使用opt打印当前Paddle-Lite支持的算子信息
`paddle_lite_opt --print_all_ops=true`
以上命令可以打印出当前Paddle-Lite支持的所有算子信息,包括OP的数量和每个OP支持哪些硬件平台:

`paddle_lite_opt --print_supported_ops=true --valid_targets=x86`
以上命令可以打印出当
`valid_targets=x86`
时Paddle-Lite支持的所有OP:
docs/user_guides/opt/x2paddle&opt.md
0 → 100644
浏览文件 @
8dc7b259
## 合并x2paddle和opt的一键脚本
**背景**
:如果想用Paddle-Lite运行第三方来源(tensorflow、caffe、onnx)模型,一般需要经过两次转化。即使用x2paddle工具将第三方模型转化为PaddlePaddle格式,再使用opt将PaddlePaddle模型转化为Padde-Lite可支持格式。
为了简化这一过程,我们提供一键脚本,将x2paddle转化和opt转化合并:
**一键转化脚本**
:
[
auto_transform.sh
](
https://github.com/PaddlePaddle/Paddle-Lite/blob/release/v2.3/lite/tools/auto_transform.sh
)
**环境要求**
:使用
`auto_transform.sh`
脚本转化第三方模型时,需要先安装x2paddle环境,请参考
[
x2paddle环境安装方法
](
https://github.com/PaddlePaddle/X2Paddle#环境依赖
)
安装x2paddle和x2paddle依赖项(tensorflow、caffe等)。
**使用方法**
:
(1)打印帮助帮助信息:
` sh ./auto_transform.sh`
(2)转化模型方法
```
bash
USAGE:
auto_transform.sh combines the
function
of x2paddle and opt, it can
tranform model from tensorflow/caffe/onnx form into paddle-lite naive-buffer form.
----------------------------------------
example:
sh ./auto_transform.sh
--framework
=
tensorflow
--model
=
tf_model.pb
--optimize_out
=
opt_model_result
----------------------------------------
Arguments about x2paddle:
--framework
=(
tensorflow|caffe|onnx
)
;
--model
=
'model file for tensorflow or onnx'
;
--prototxt
=
'proto file for caffe'
--weight
=
'weight file for caffe'
For TensorFlow:
--framework
=
tensorflow
--model
=
tf_model.pb
For Caffe:
--framework
=
caffe
--prototxt
=
deploy.prototxt
--weight
=
deploy.caffemodel
For ONNX
--framework
=
onnx
--model
=
onnx_model.onnx
Arguments about opt:
--valid_targets
=(
arm|opencl|x86|npu|xpu
)
;
valid targets on Paddle-Lite.
--fluid_save_dir
=
'path to outputed model after x2paddle'
--optimize_out
=
'path to outputed Paddle-Lite model'
----------------------------------------
```
docs/user_guides/tutorial.md
浏览文件 @
8dc7b259
...
@@ -13,11 +13,9 @@ Lite框架拥有强大的加速、优化策略及实现,其中包含诸如量
...
@@ -13,11 +13,9 @@ Lite框架拥有强大的加速、优化策略及实现,其中包含诸如量
opt的详细介绍,请您参考
[
模型优化方法
](
model_optimize_tool
)
。
opt的详细介绍,请您参考
[
模型优化方法
](
model_optimize_tool
)
。
使用opt,您只需编译后在开发机上
执行以下代码:
下载opt工具后
执行以下代码:
```
shell
```
shell
$
cd
<PaddleLite_base_path>
$
cd
build.opt/lite/api/
$
./opt
\
$
./opt
\
--model_dir
=
<model_param_dir>
\
--model_dir
=
<model_param_dir>
\
--model_file
=
<model_path>
\
--model_file
=
<model_path>
\
...
...
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录