Merge pull request #497 from Eclipsess/develop
fix #496 fix result error
Showing
doc/images/devices.png
0 → 100644
{kind=link}
116.0 KB
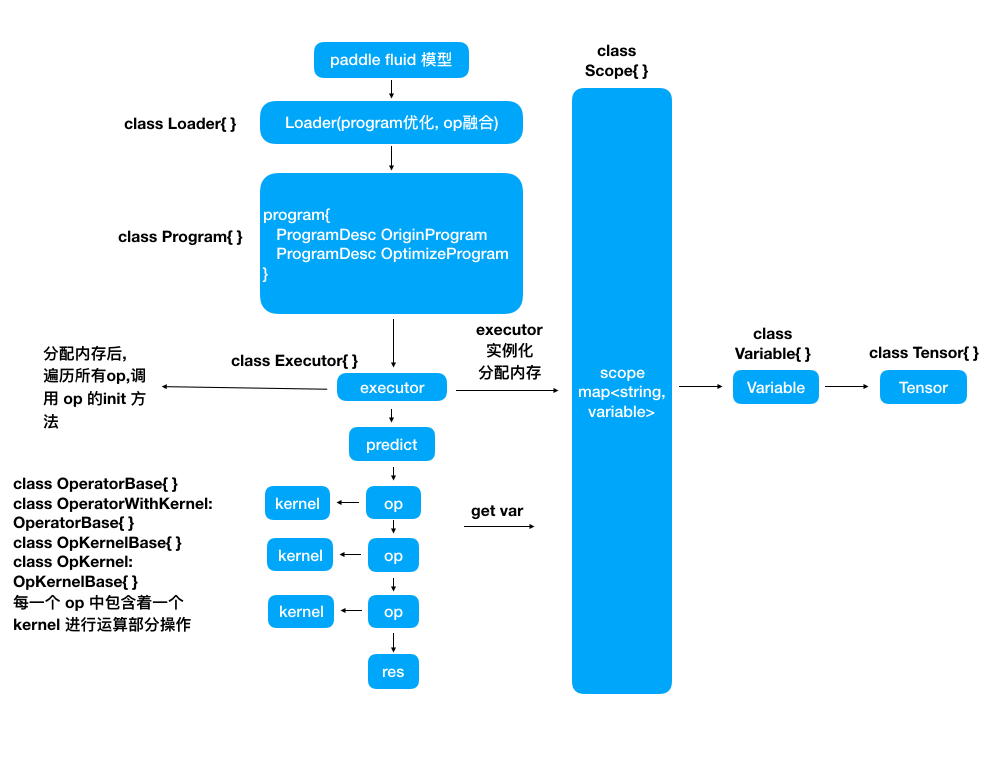
doc/images/flow_chart.png
0 → 100644
{kind=link}
110.3 KB
doc/images/model_desc.png
0 → 100644
{kind=link}
162.1 KB
{kind=link}

10.1 KB