update documents (#22)
* update README.md and move other documents into README.md
Showing
docs/api_intro.md
已删除
100644 → 0
docs/base64_preprocessor.md
已删除
100644 → 0
docs/custom_models.md
已删除
100644 → 0
docs/distributed_params.md
已删除
100644 → 0
docs/export_for_infer.md
已删除
100644 → 0
docs/installation.md
已删除
100644 → 0
docs/serving.md
已删除
100644 → 0
docs/usage.md
已删除
100644 → 0
images/fc_computing.gif
0 → 100644
{kind=link}
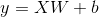
417 字节
images/fc_computing.png
已删除
100644 → 0
{kind=link}
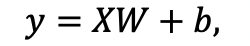
11.8 KB
images/fc_computing_block.gif
0 → 100644
{kind=link}
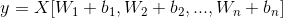
986 字节
images/fc_computing_block.png
已删除
100644 → 0
{kind=link}
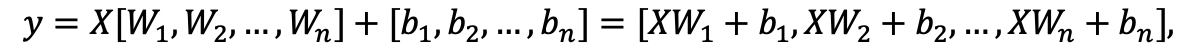
39.4 KB
{kind=link}
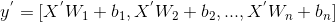
1.1 KB
{kind=link}
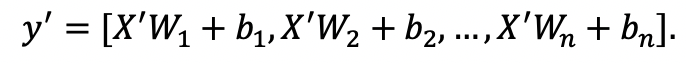
26.4 KB
images/softmax_computing.gif
0 → 100644
{kind=link}
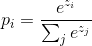
505 字节
images/softmax_computing.png
已删除
100644 → 0
{kind=link}
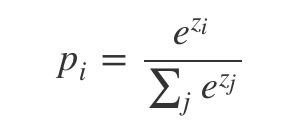
9.7 KB
| numpy>=1.12, <=1.16.4 ; python_version<"3.5" | numpy>=1.12, <=1.16.4 ; python_version<"3.5" | ||
| numpy>=1.12 ; python_version>="3.5" | numpy>=1.12 ; python_version>="3.5" | ||
| scikit-learn<=0.20 ; python_version<"3.5" | |||
| scikit-learn ; python_version>="3.5" | |||
| scipy>=0.19.0, <=1.2.1 ; python_version<"3.5" | scipy>=0.19.0, <=1.2.1 ; python_version<"3.5" | ||
| scipy ; python_version>="3.5" | scipy ; python_version>="3.5" | ||
| Pillow | Pillow | ||
| sklearn | sklearn | ||
| easydict | easydict | ||
| six | six | ||
| paddlepaddle-gpu | paddlepaddle-gpu>=1.6.2 |