Merge pull request #2 from PaddlePaddle/master
merge
Showing
README.zh.md
0 → 100644
{kind=link}

105.3 KB
{kind=link}
{kind=link}

| W: | H:
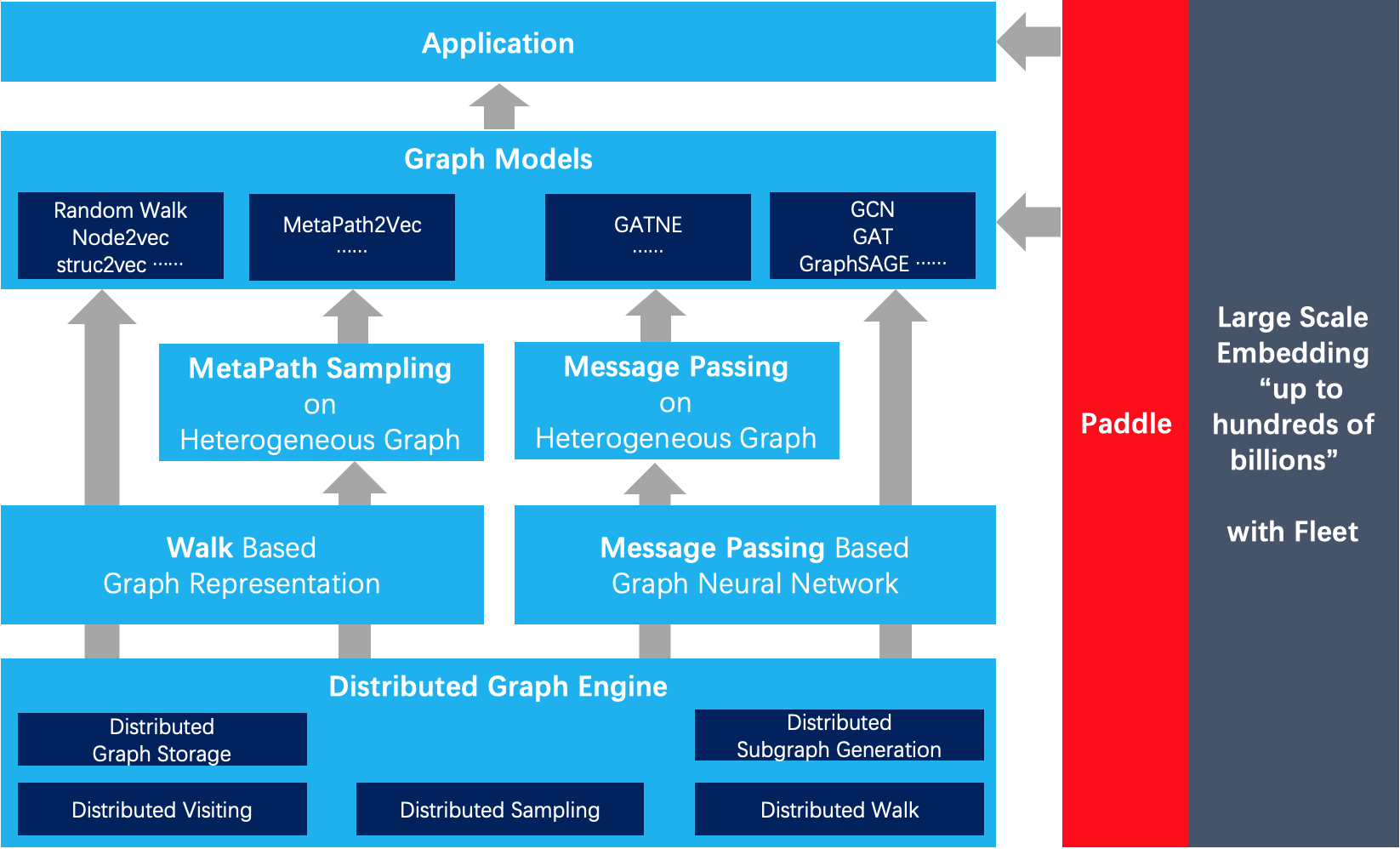
| W: | H:
{kind=link}

156.6 KB
docs/source/_static/logo.png
0 → 100644
{kind=link}
45.2 KB
{kind=link}
{kind=link}

| W: | H:

| W: | H:
{kind=link}

85.0 KB
{kind=link}

282.8 KB
{kind=link}
{kind=link}

| W: | H:

| W: | H:
{kind=link}

141.6 KB
{kind=link}

456.4 KB
examples/GATNE/Dataset.py
0 → 100644
examples/GATNE/README.md
0 → 100644
examples/GATNE/config.yaml
0 → 100644
examples/GATNE/data_process.py
0 → 100644
examples/GATNE/main.py
0 → 100644
examples/GATNE/model.py
0 → 100644
examples/GATNE/utils.py
0 → 100644
examples/dgi/README.md
0 → 100644
examples/dgi/dgi.py
0 → 100644
examples/dgi/train.py
0 → 100644
文件已添加
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
examples/ges/README.md
0 → 100644
此差异已折叠。
examples/ges/gpu_run.sh
0 → 100755
此差异已折叠。
examples/ges/gpu_train.py
0 → 100644
此差异已折叠。
examples/ges/model.py
0 → 100644
此差异已折叠。
examples/ges/mp_reader.py
0 → 100644
此差异已折叠。
examples/ges/reader.py
0 → 100644
此差异已折叠。
examples/gin/Dataset.py
0 → 100644
此差异已折叠。
examples/gin/README.md
0 → 100644
此差异已折叠。
examples/gin/dataloader.py
0 → 100644
此差异已折叠。
examples/gin/main.py
0 → 100644
此差异已折叠。
examples/gin/model.py
0 → 100644
此差异已折叠。
examples/graphsage/train_multi.py
0 → 100644
此差异已折叠。
examples/graphsage/train_scale.py
0 → 100644
此差异已折叠。
examples/line/README.md
0 → 100644
此差异已折叠。
examples/line/data_loader.py
0 → 100644
此差异已折叠。
examples/line/data_process.py
0 → 100644
此差异已折叠。
examples/line/line.py
0 → 100644
此差异已折叠。
examples/line/multi_class.py
0 → 100644
此差异已折叠。
examples/metapath2vec/Dataset.py
0 → 100644
此差异已折叠。
examples/metapath2vec/README.md
0 → 100644
此差异已折叠。
examples/metapath2vec/config.yaml
0 → 100644
此差异已折叠。
examples/metapath2vec/main.py
0 → 100644
此差异已折叠。
examples/metapath2vec/model.py
0 → 100644
此差异已折叠。
此差异已折叠。
examples/metapath2vec/sample.py
0 → 100644
此差异已折叠。
examples/metapath2vec/utils.py
0 → 100644
此差异已折叠。
examples/pgl-ke/README.md
0 → 100644
此差异已折叠。
examples/pgl-ke/data_loader.py
0 → 100644
此差异已折叠。
examples/pgl-ke/evalutate.py
0 → 100644
此差异已折叠。
examples/pgl-ke/main.py
0 → 100644
此差异已折叠。
examples/pgl-ke/model/Model.py
0 → 100644
此差异已折叠。
examples/pgl-ke/model/RotatE.py
0 → 100644
此差异已折叠。
examples/pgl-ke/model/TransE.py
0 → 100644
此差异已折叠。
examples/pgl-ke/model/TransR.py
0 → 100644
此差异已折叠。
examples/pgl-ke/model/__init__.py
0 → 100644
此差异已折叠。
examples/pgl-ke/model/utils.py
0 → 100644
此差异已折叠。
examples/pgl-ke/mp_mapper.py
0 → 100644
此差异已折叠。
examples/pgl-ke/run.sh
0 → 100644
此差异已折叠。
examples/sgc/README.md
0 → 100644
此差异已折叠。
examples/sgc/sgc.py
0 → 100644
此差异已折叠。
examples/stgcn/README.md
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
examples/stgcn/main.py
0 → 100644
此差异已折叠。
examples/stgcn/models/model.py
0 → 100644
此差异已折叠。
examples/stgcn/models/tester.py
0 → 100644
此差异已折叠。
此差异已折叠。
examples/strucvec/README.md
0 → 100644
此差异已折叠。
examples/strucvec/classify.py
0 → 100644
此差异已折叠。
examples/strucvec/data_loader.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
examples/strucvec/struc2vec.py
0 → 100644
此差异已折叠。
此差异已折叠。
examples/unsup_graphsage/model.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
examples/unsup_graphsage/train.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
pgl/contrib/__init__.py
0 → 100644
此差异已折叠。
pgl/contrib/ogb/__init__.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
pgl/contrib/ogb/io/__init__.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
pgl/heter_graph.py
0 → 100644
此差异已折叠。
pgl/heter_graph_wrapper.py
0 → 100644
此差异已折叠。
此差异已折叠。
pgl/layers/graph_pool.py
0 → 100644
此差异已折叠。
pgl/layers/set2set.py
0 → 100644
此差异已折叠。
pgl/redis_graph.py
0 → 100644
此差异已折叠。
pgl/redis_hetergraph.py
0 → 100644
此差异已折叠。
pgl/sample.py
0 → 100644
此差异已折叠。
此差异已折叠。
pgl/tests/test_gin.py
0 → 100644
此差异已折叠。
pgl/tests/test_hetergraph.py
0 → 100644
此差异已折叠。
此差异已折叠。
pgl/tests/test_redis_graph.py
0 → 100644
此差异已折叠。
此差异已折叠。
pgl/tests/test_sample.py
0 → 100644
此差异已折叠。
pgl/tests/test_set2set.py
0 → 100644
此差异已折叠。
pgl/utils/mp_reader.py
0 → 100644
此差异已折叠。
pgl/utils/mt_reader.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
tests/scatter_add_test.py
0 → 100644
此差异已折叠。
tests/unique_with_counts_test.py
0 → 100644
此差异已折叠。