add new readme
Showing
{kind=link}
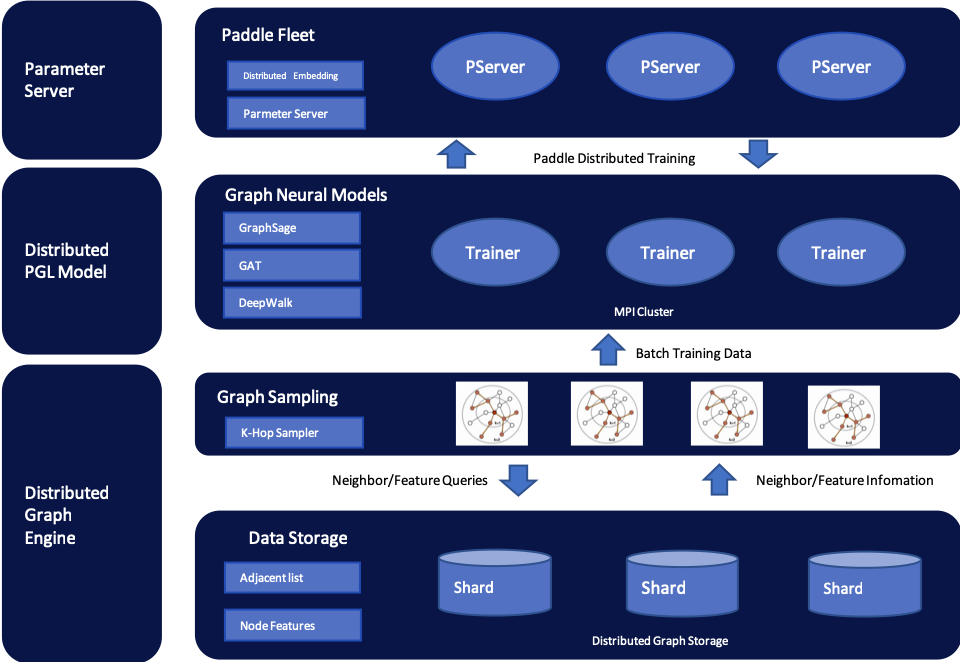
105.3 KB
{kind=link}
{kind=link}
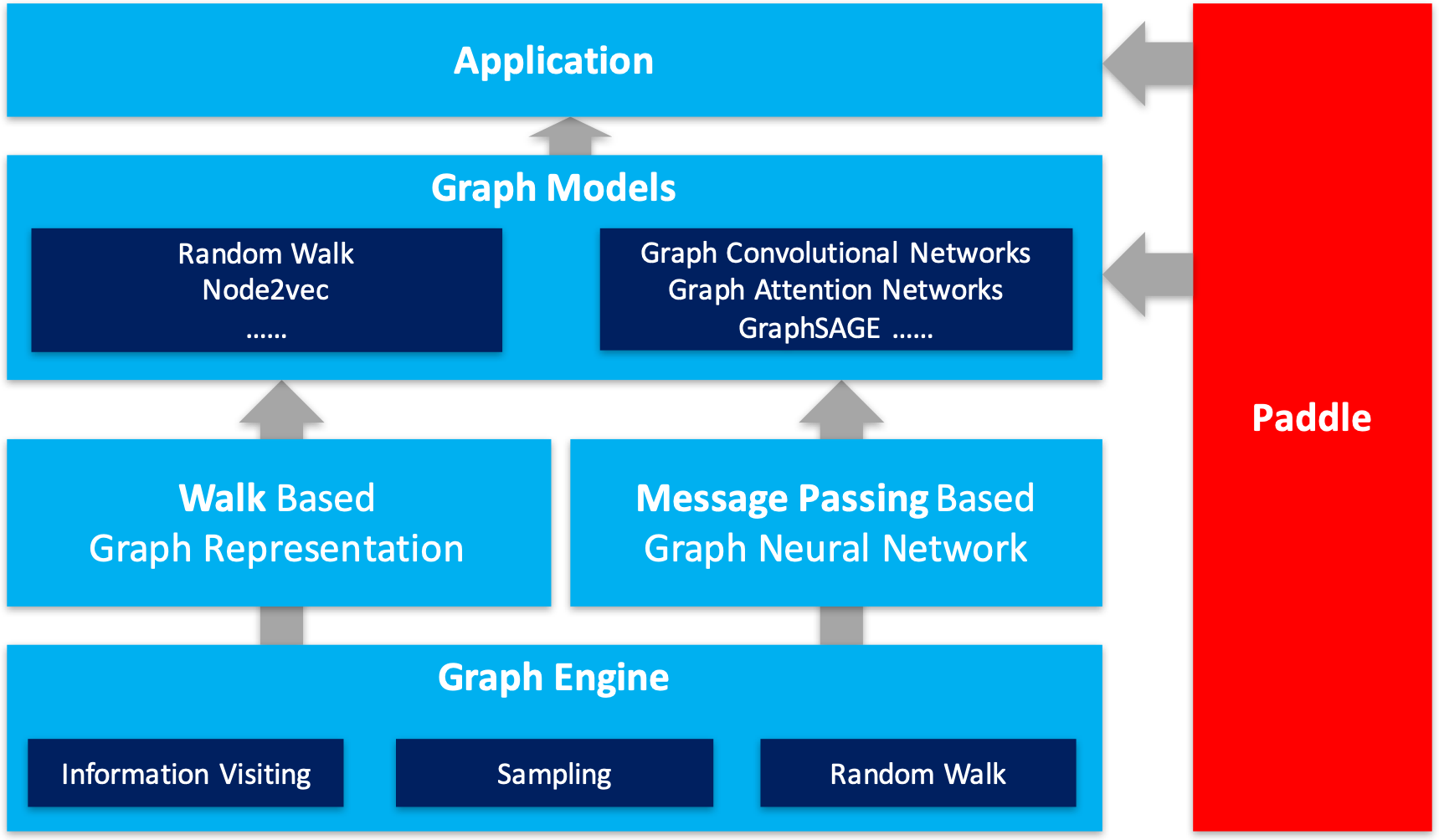
| W: | H:
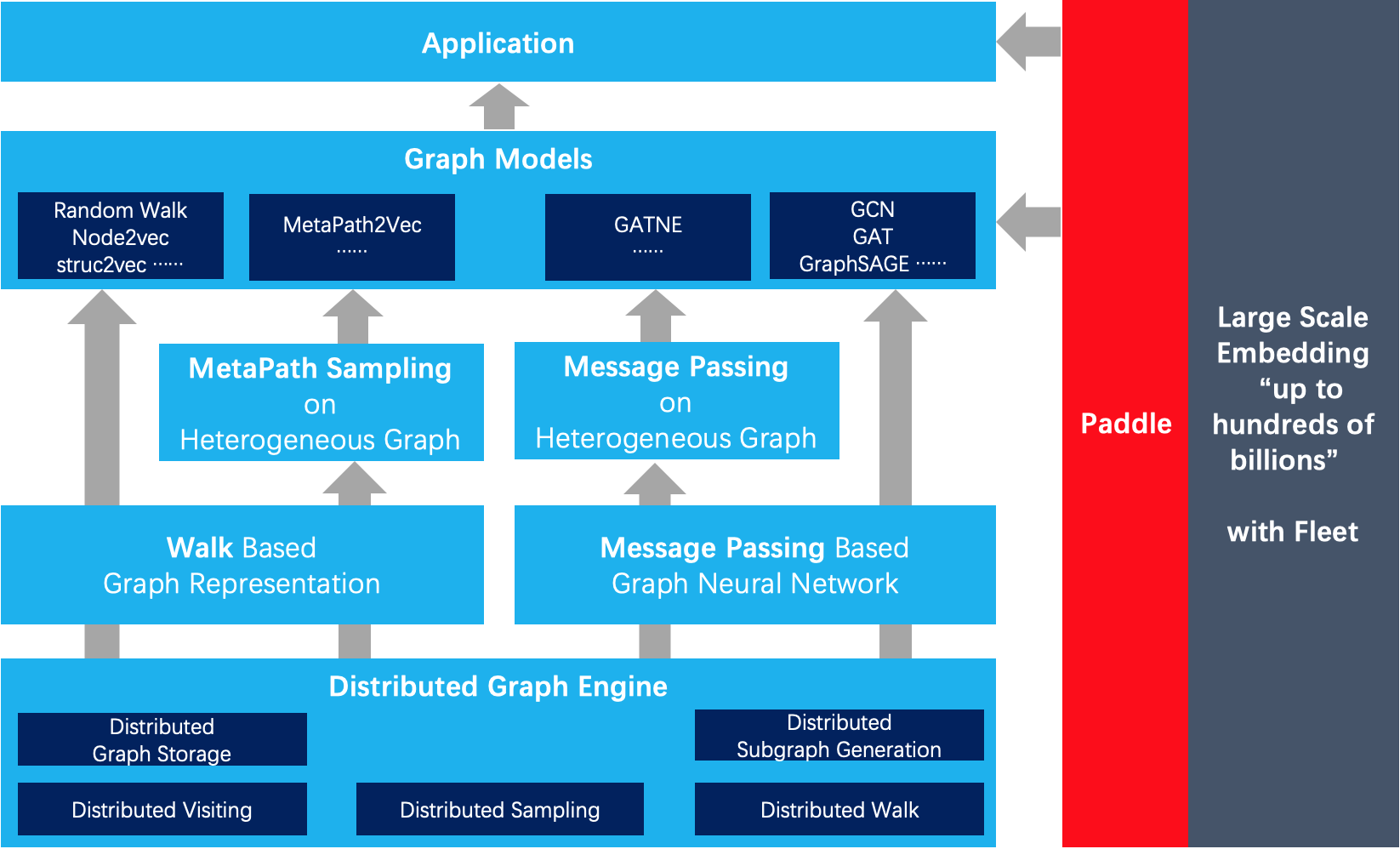
| W: | H:
{kind=link}
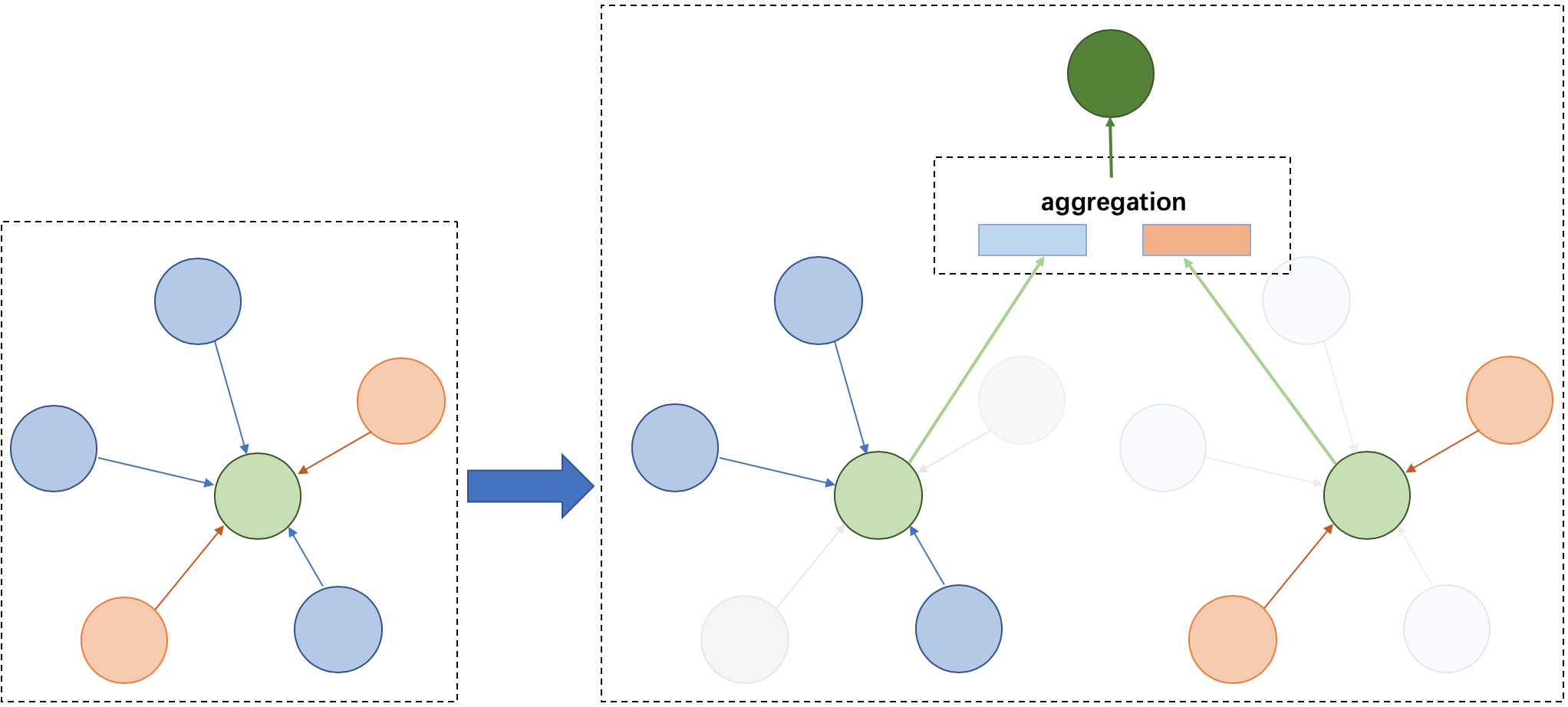
156.6 KB
docs/source/_static/logo.png
0 → 100644
{kind=link}
49.1 KB
{kind=link}
{kind=link}
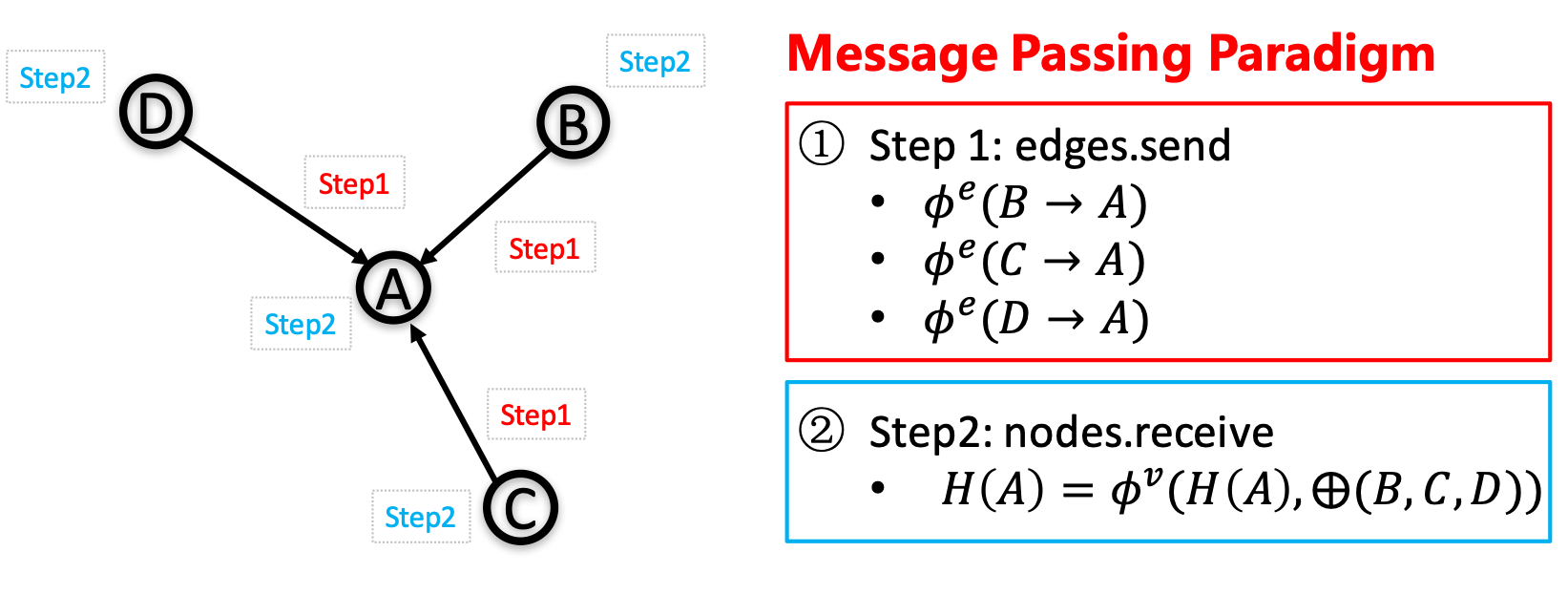
| W: | H:
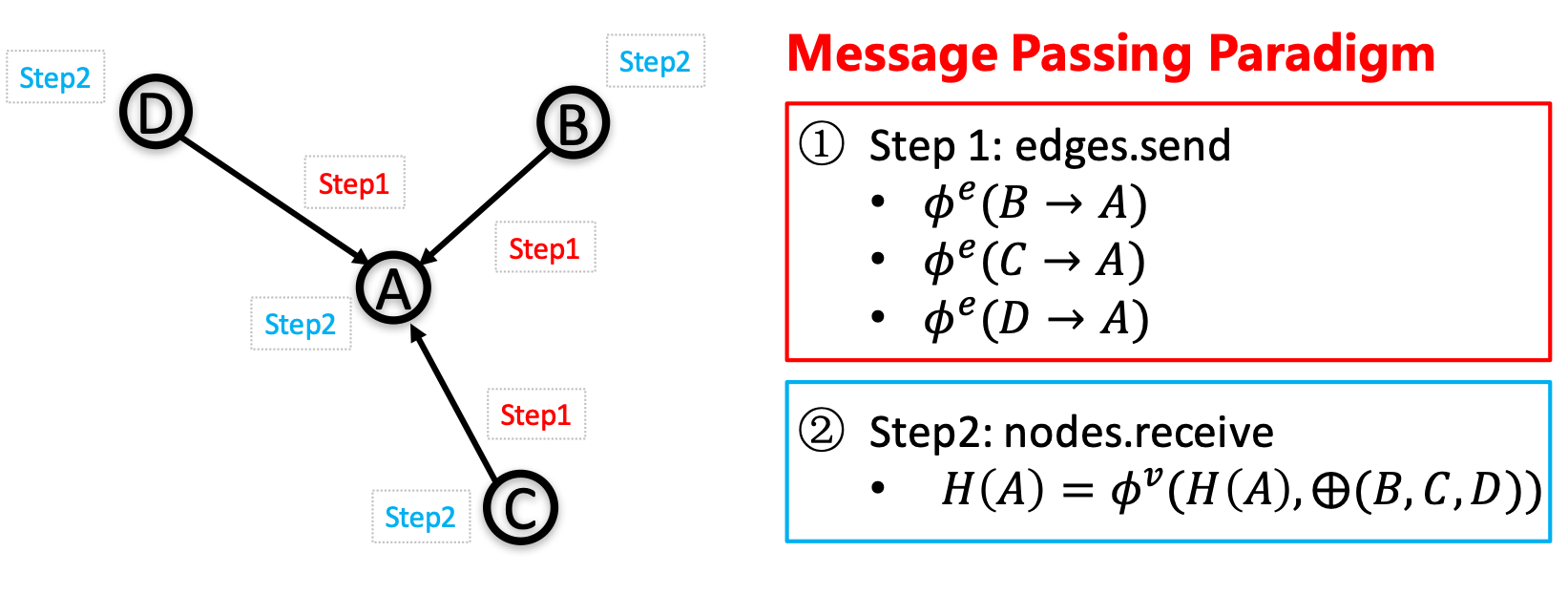
| W: | H:
{kind=link}

85.0 KB
{kind=link}
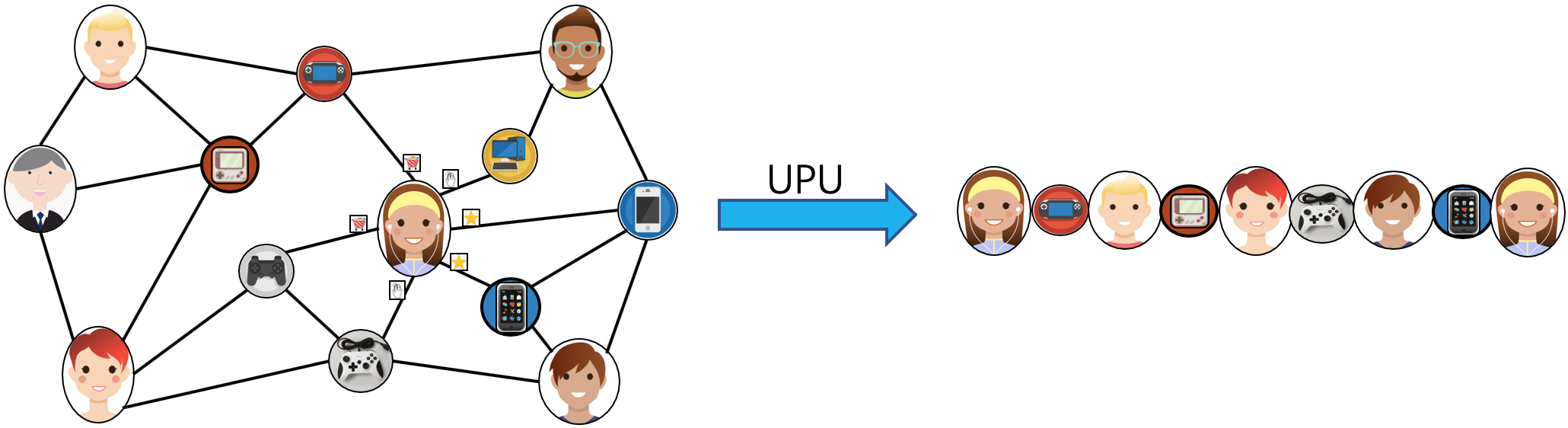
282.8 KB
{kind=link}
{kind=link}
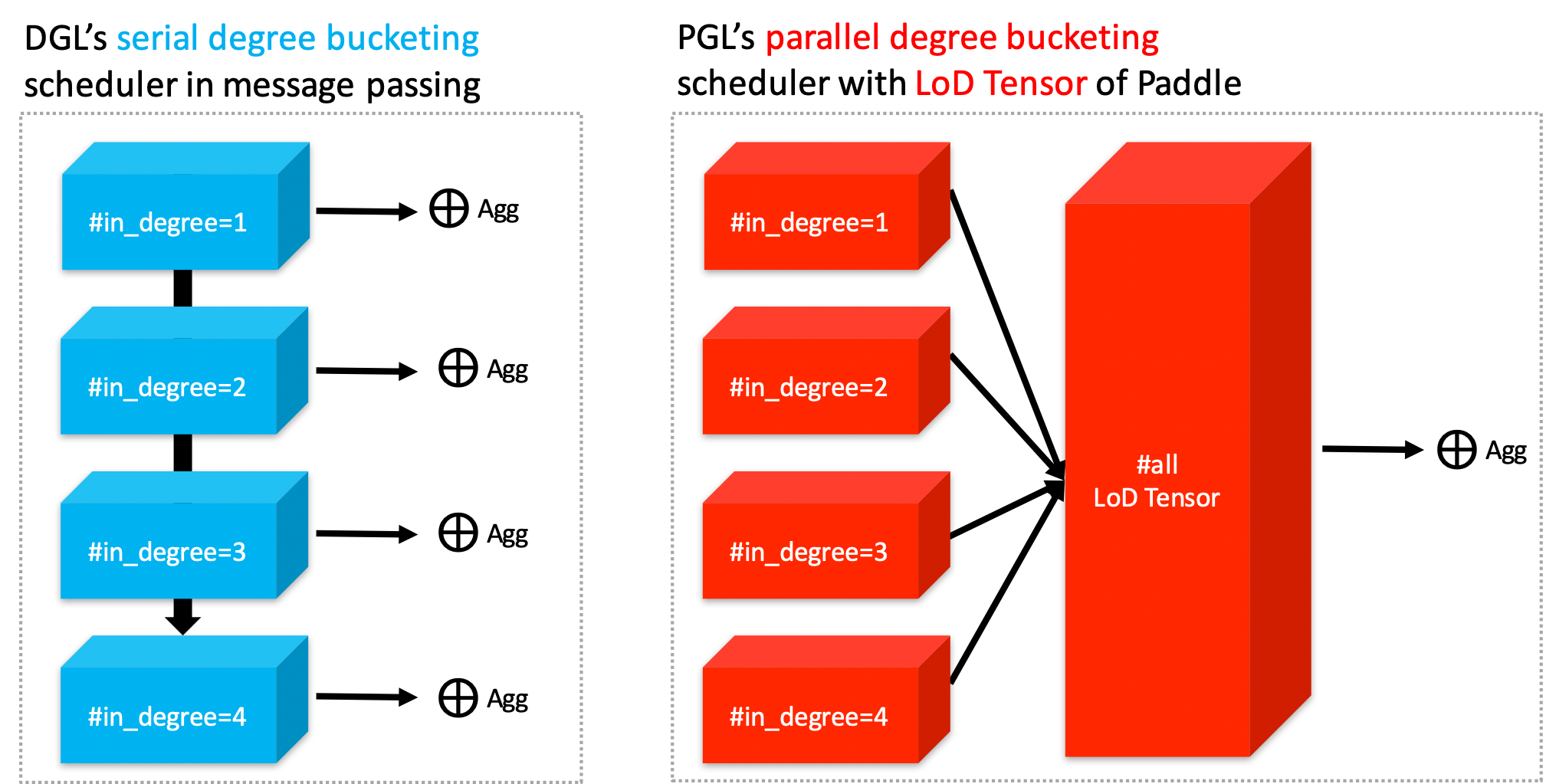
| W: | H:
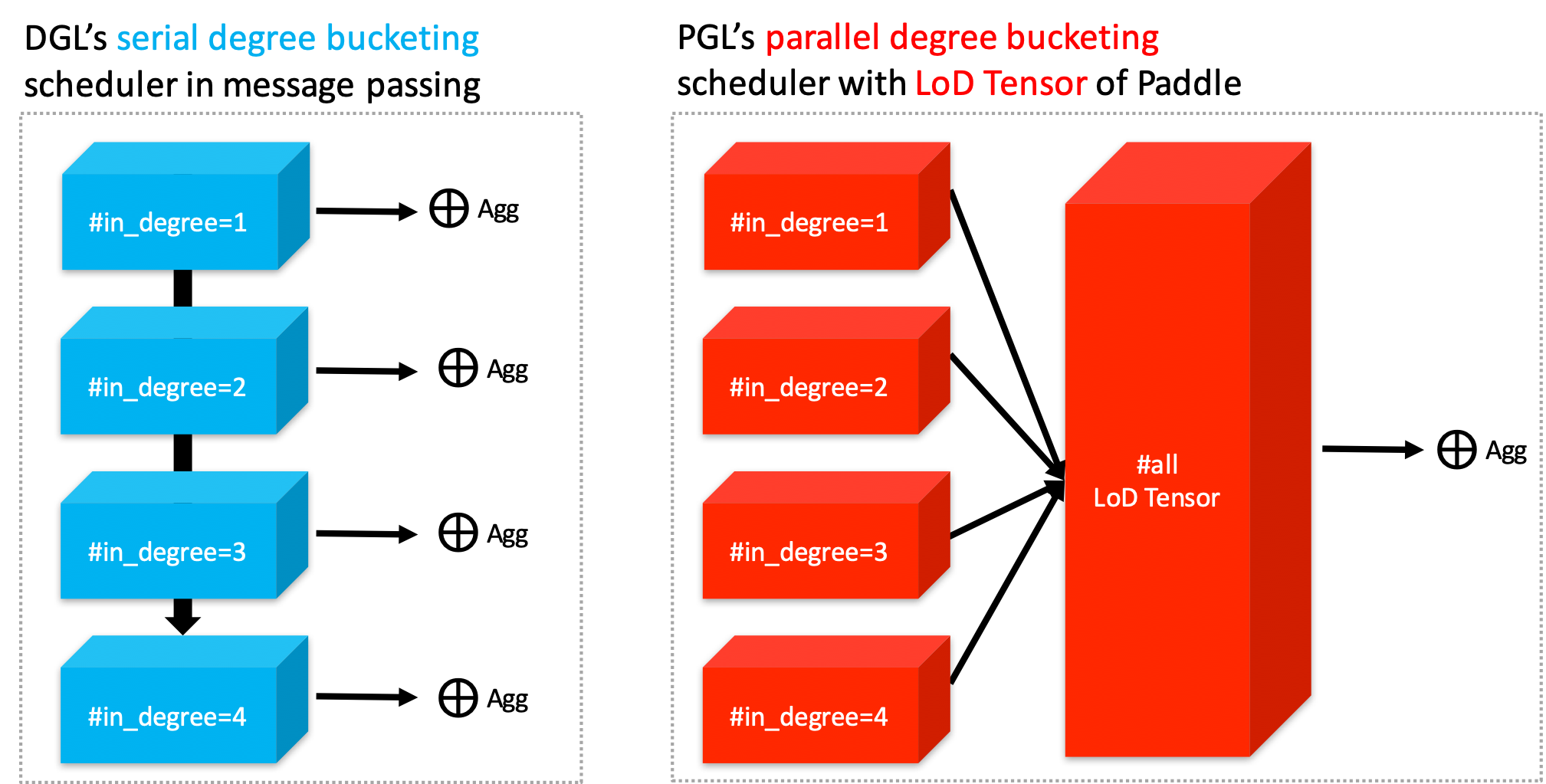
| W: | H:
{kind=link}
456.4 KB
105.3 KB
| W: | H:
| W: | H:
156.6 KB
49.1 KB
| W: | H:
| W: | H:
85.0 KB
282.8 KB
| W: | H:
| W: | H:
456.4 KB