add PPO example (#39)
* add PPO example * Update Readme * Update Readme * fix codestyle * Update Readme * refine action mapping * add more unitest case * remove unnecessary params initialize, add more comments, add benchmark result * rename * remove PARL dependence in readme of examples
Showing
{kind=link}
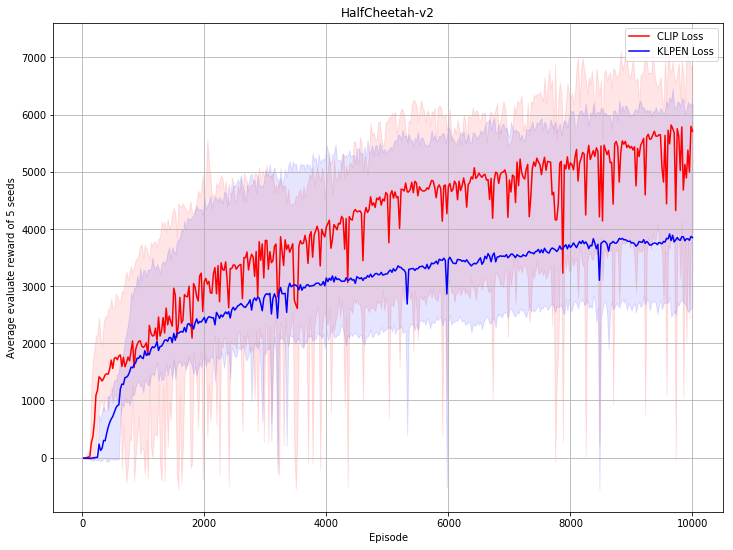
115.0 KB
examples/PPO/README.md
0 → 100644
examples/PPO/mujoco_agent.py
0 → 100644
examples/PPO/mujoco_model.py
0 → 100644
examples/PPO/train.py
0 → 100755
examples/PPO/utils.py
0 → 100644
parl/algorithms/ppo.py
0 → 100644
parl/utils/tests/utils_test.py
0 → 100644