add liftsim baseline (#120)
* add liftsim baseline * yapf * yapf... * modify acc. comments * yapf * yapf.......... * yapf! why is yapf on paddle different from that on my mac!!!!!
Showing
examples/LiftSim_demo/README.md
0 → 100644
examples/LiftSim_demo/__init__.py
0 → 100644
examples/LiftSim_demo/demo.py
0 → 100644
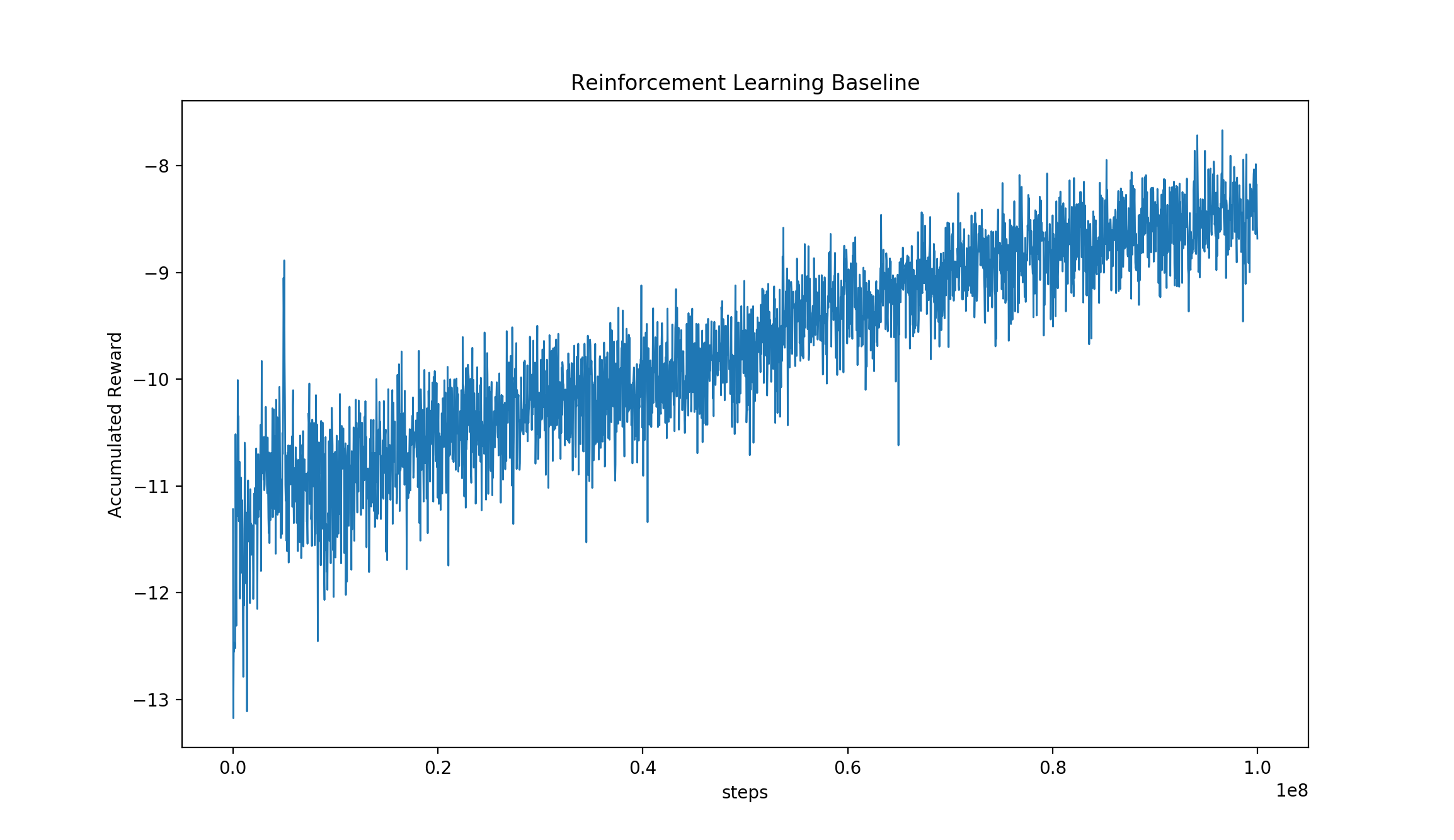
examples/LiftSim_demo/rl_10.png
0 → 100644
{kind=link}
181.6 KB
examples/LiftSim_demo/wrapper.py
0 → 100644