implement of IMPALA with the newest parallel design (#60)
* add IMPALA algorithm and some common utils * update README.md * refactor files structure of impala algorithm; seperate numpy utils from utils * add hyper parameter scheduler module; add entropy and lr scheduler in impala * clip reward in atari wrapper instead of learner side; fix codestyle * add benchmark result of impala; refine code of impala example; add obs_format in atari_wrappers * Update README.md
Showing
{kind=link}
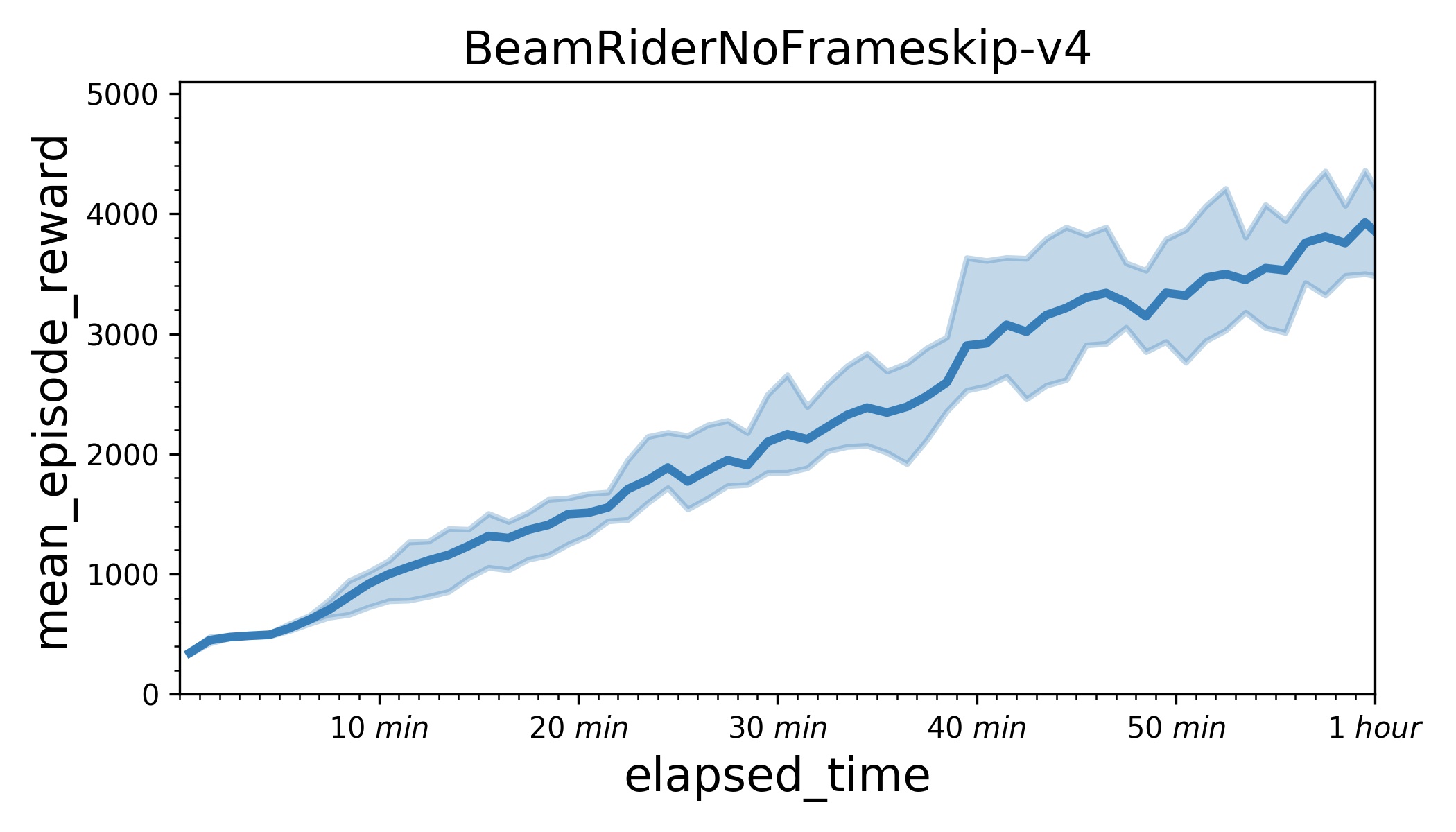
213.1 KB
{kind=link}
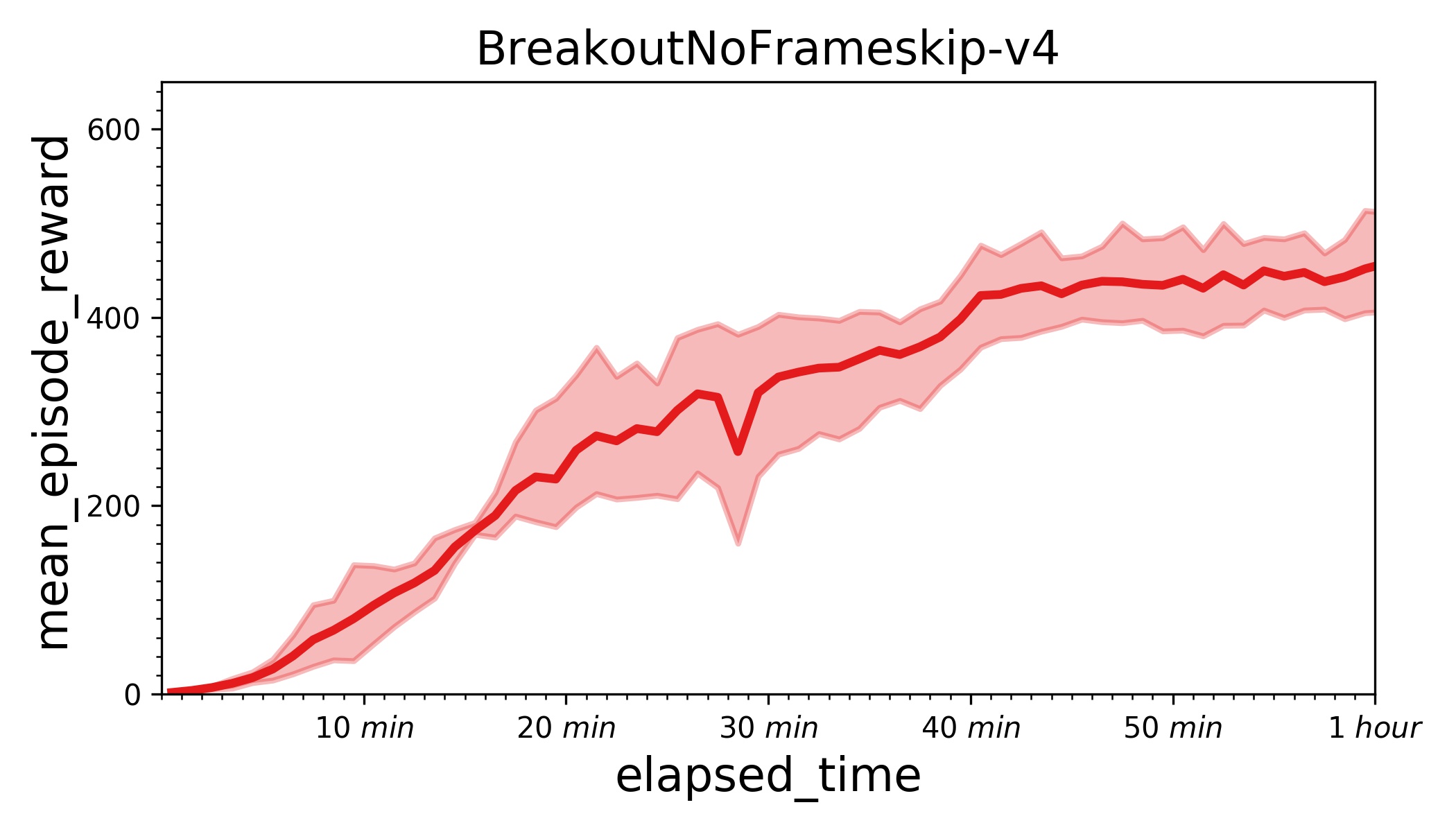
215.1 KB
{kind=link}
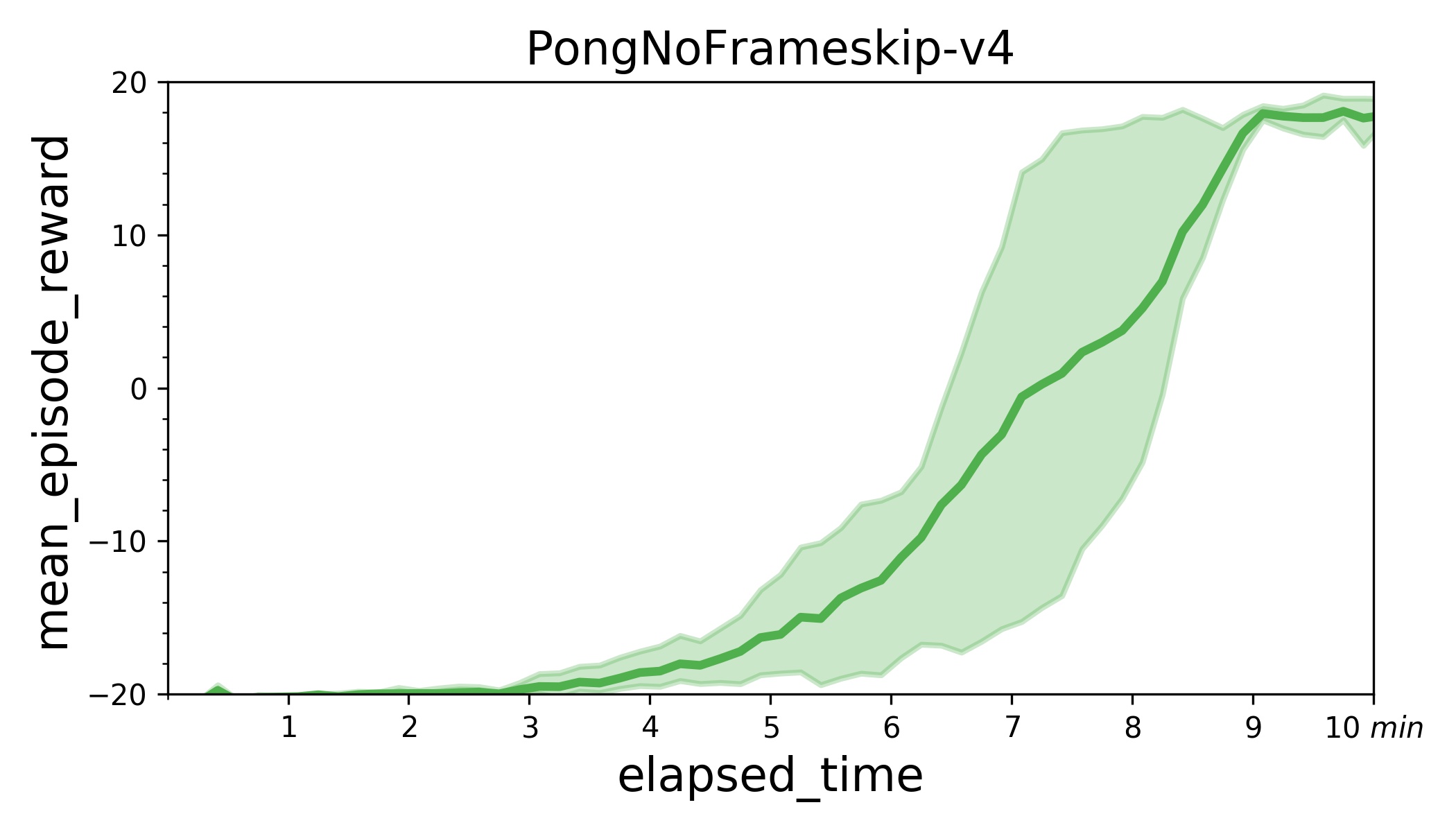
171.1 KB
{kind=link}
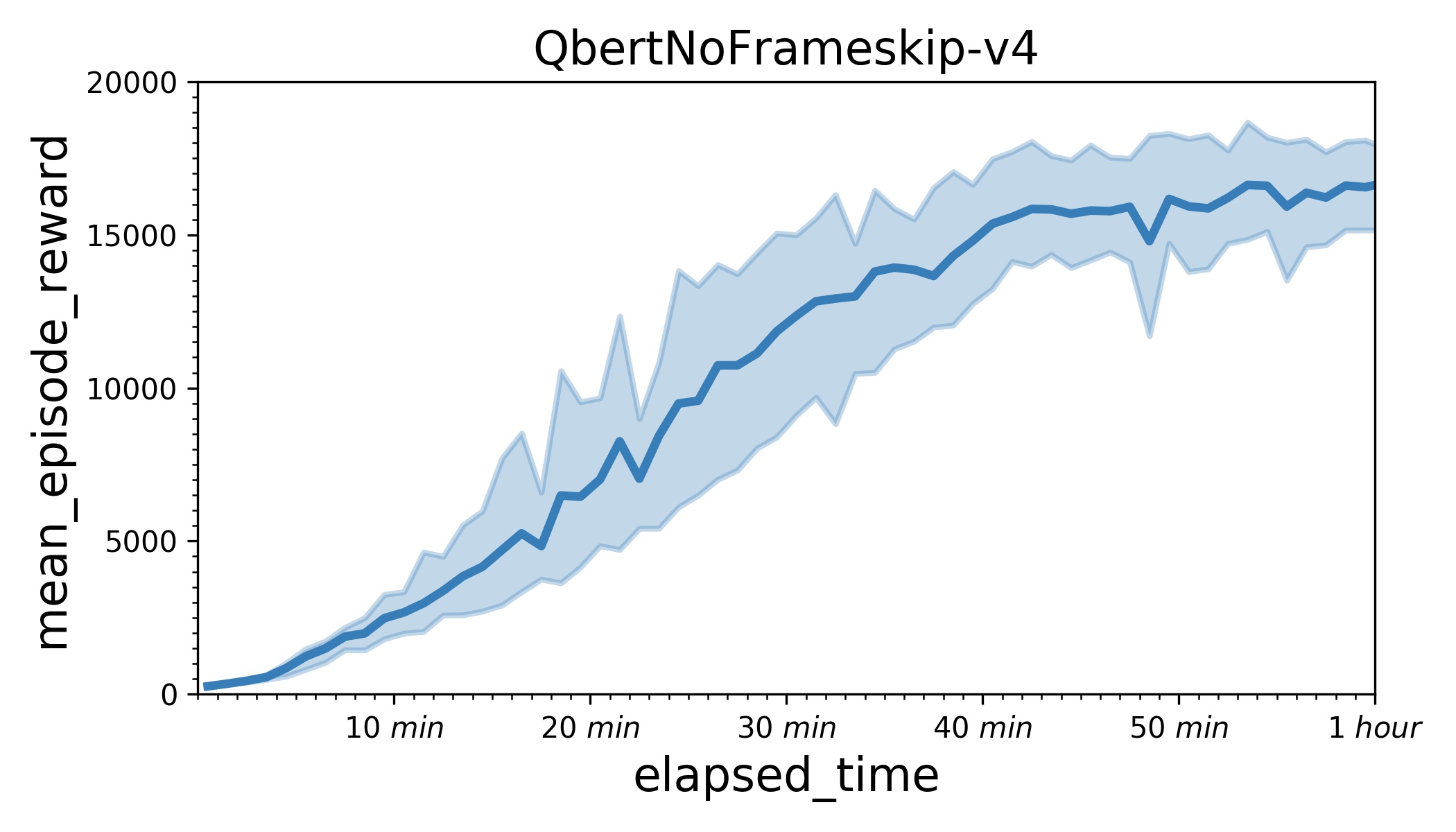
217.1 KB
{kind=link}
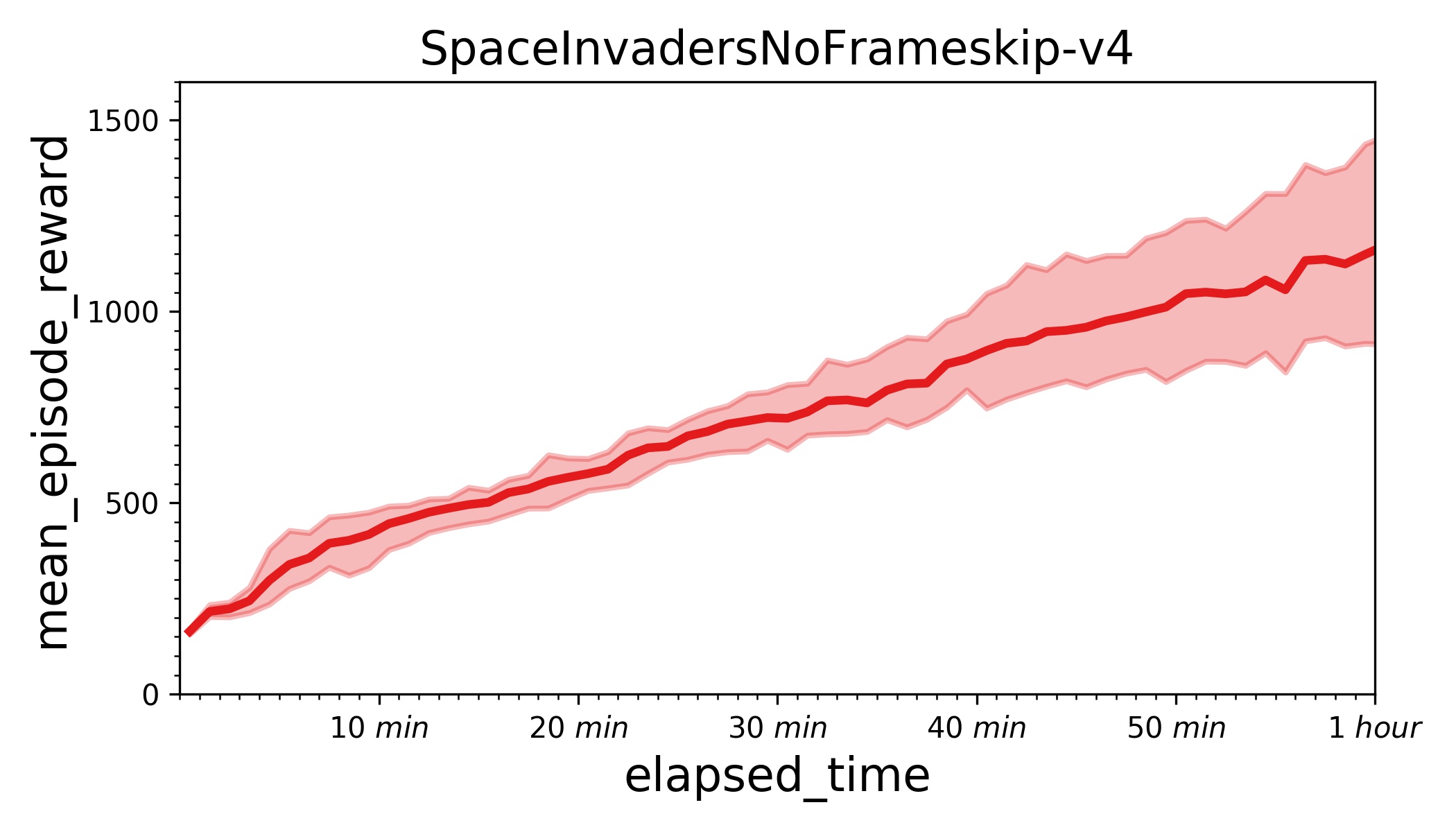
209.8 KB
examples/IMPALA/README.md
0 → 100644
examples/IMPALA/actor.py
0 → 100644
examples/IMPALA/atari_agent.py
0 → 100644
examples/IMPALA/atari_model.py
0 → 100644
examples/IMPALA/impala_config.py
0 → 100644
examples/IMPALA/learner.py
0 → 100644
examples/IMPALA/run_actors.sh
0 → 100644
examples/IMPALA/train.py
0 → 100644
parl/algorithms/impala/impala.py
0 → 100644
parl/algorithms/impala/vtrace.py
0 → 100644
parl/env/__init__.py
0 → 100644
parl/env/atari_wrappers.py
0 → 100644
parl/env/vector_env.py
0 → 100644
parl/utils/csv_logger.py
0 → 100644
parl/utils/np_utils.py
0 → 100644
parl/utils/scheduler.py
0 → 100644
parl/utils/time_stat.py
0 → 100644
parl/utils/window_stat.py
0 → 100644