Add Chinese docs (#301)
* add docs * add docs * typo * Update Overview.md * update docs * yapf * yapf
Showing
docs/.DS_Store
0 → 100644
文件已添加
docs/images/bar.png
0 → 100644
{kind=link}

4.2 KB
docs/zh_CN/Overview.md
0 → 100644
docs/zh_CN/tutorial/module.md
0 → 100644
docs/zh_CN/tutorial/param.md
0 → 100644
docs/zh_CN/tutorial/summary.md
0 → 100644
docs/zh_CN/xparl/debug.md
0 → 100644
docs/zh_CN/xparl/example.md
0 → 100644
docs/zh_CN/xparl/introduction.md
0 → 100644
docs/zh_CN/xparl/log_server.png
0 → 100644
{kind=link}
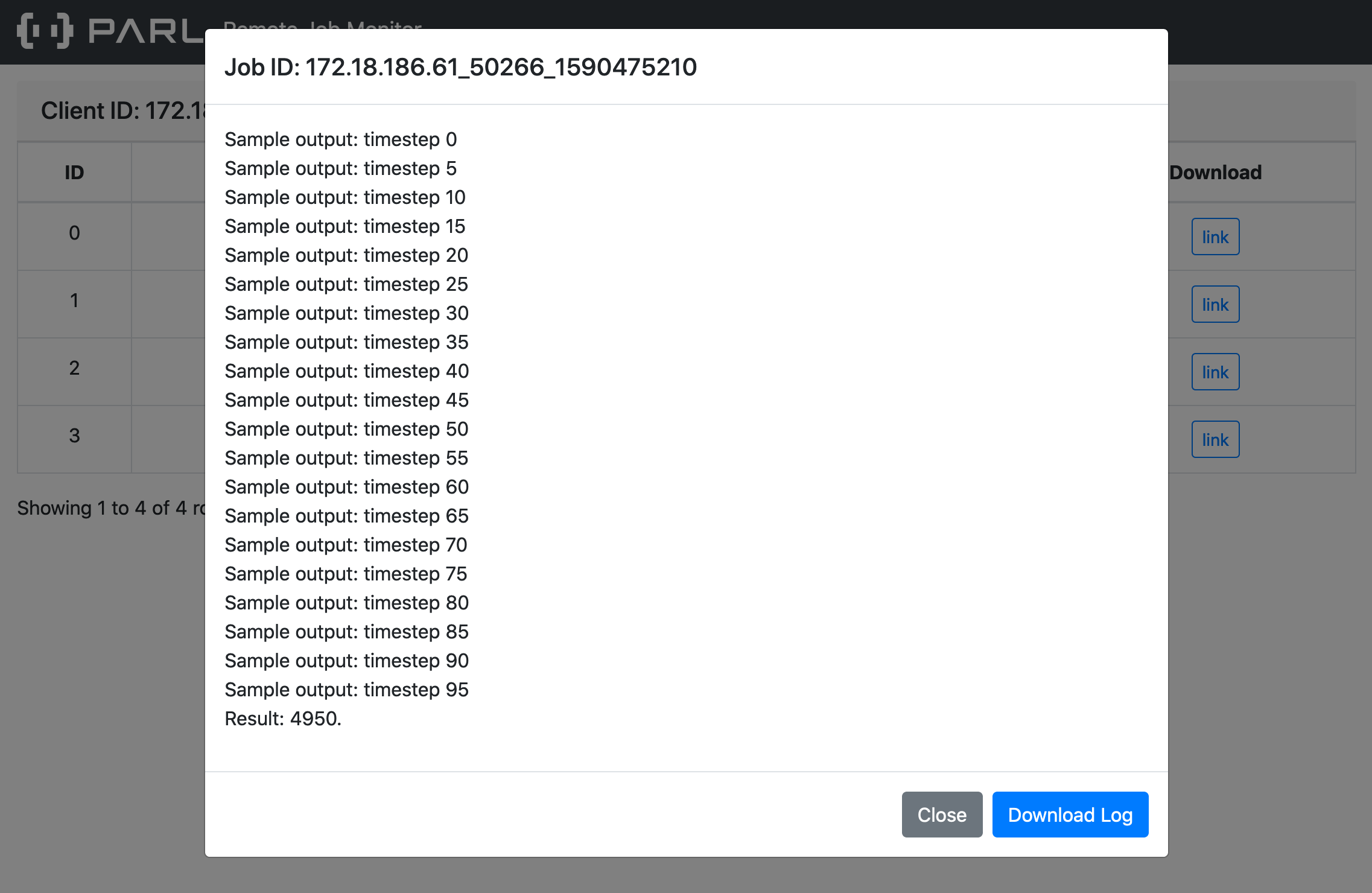
294.6 KB
docs/zh_CN/xparl/tutorial.md
0 → 100644