A2C example (#62)
* add IMPALA algorithm and some common utils * update README.md * refactor files structure of impala algorithm; seperate numpy utils from utils * add hyper parameter scheduler module; add entropy and lr scheduler in impala * clip reward in atari wrapper instead of learner side; fix codestyle * add benchmark result of impala; refine code of impala example; add obs_format in atari_wrappers * Update README.md * add a3c algorithm, A2C example and rl_utils * require training in single gpu/cpu * only check cpu/gpu num in learner * refine Readme * update impala benchmark picture; update Readme * add benchmark result of A2C * move get_params/set_params in agent_base * fix shell script cannot run in ubuntu * refine comment and document * Update README.md * Update README.md
Showing
{kind=link}
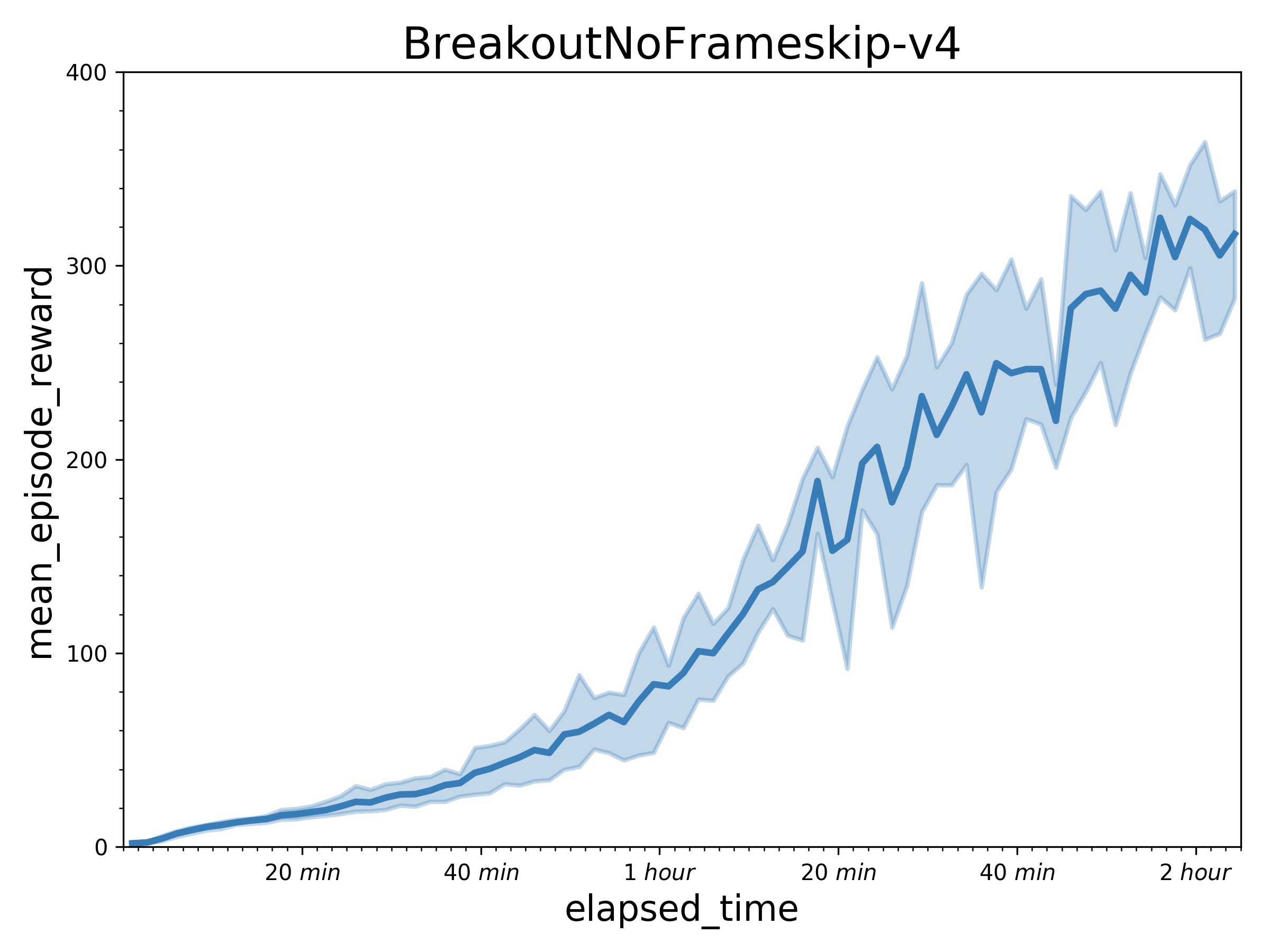
298.5 KB
{kind=link}
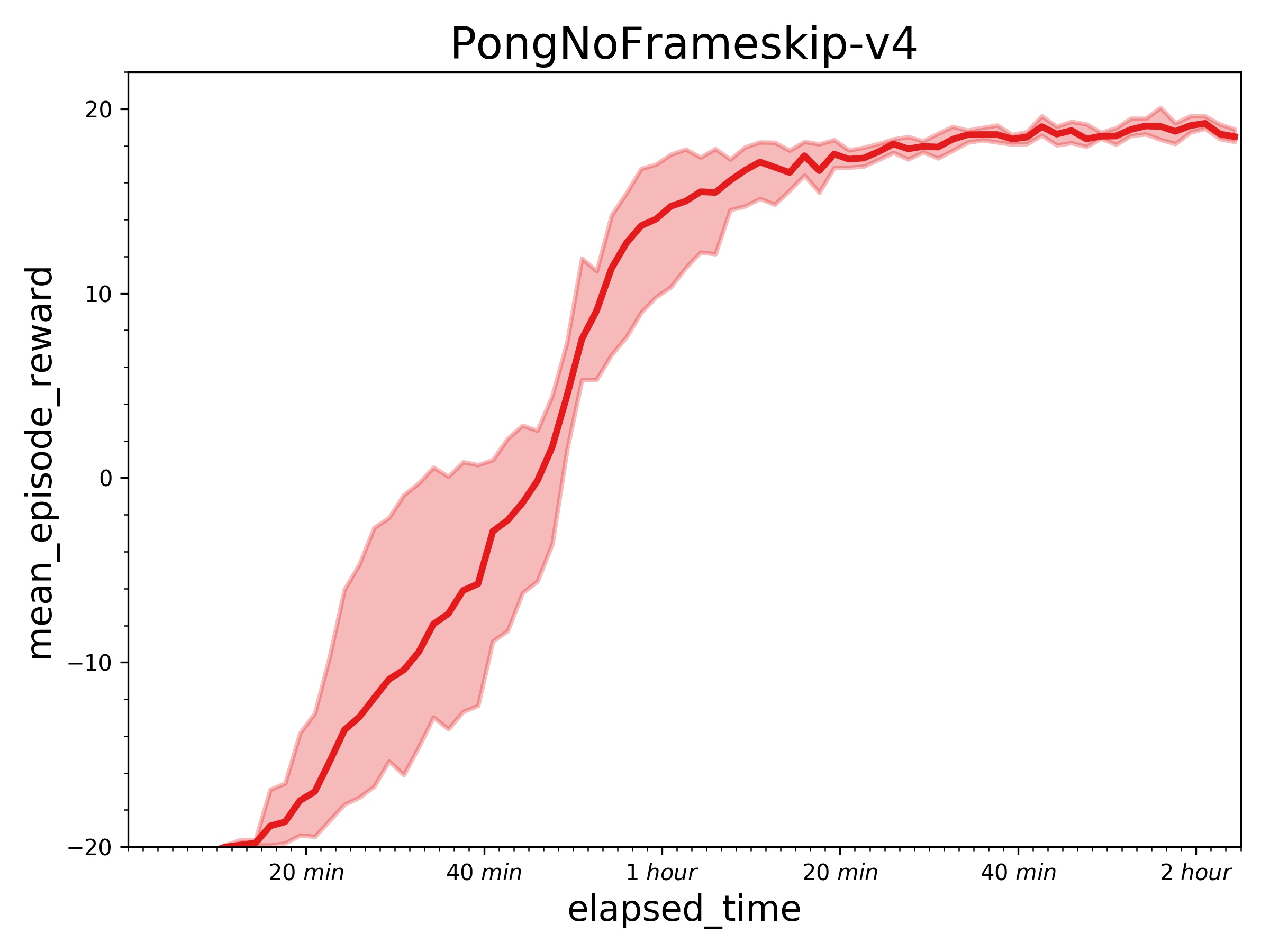
271.9 KB
examples/A2C/README.md
0 → 100644
examples/A2C/a2c_config.py
0 → 100644
examples/A2C/actor.py
0 → 100644
examples/A2C/atari_agent.py
0 → 100644
examples/A2C/atari_model.py
0 → 100644
examples/A2C/learner.py
0 → 100644
examples/A2C/run_actors.sh
0 → 100644
examples/A2C/train.py
0 → 100644
{kind=link}
{kind=link}
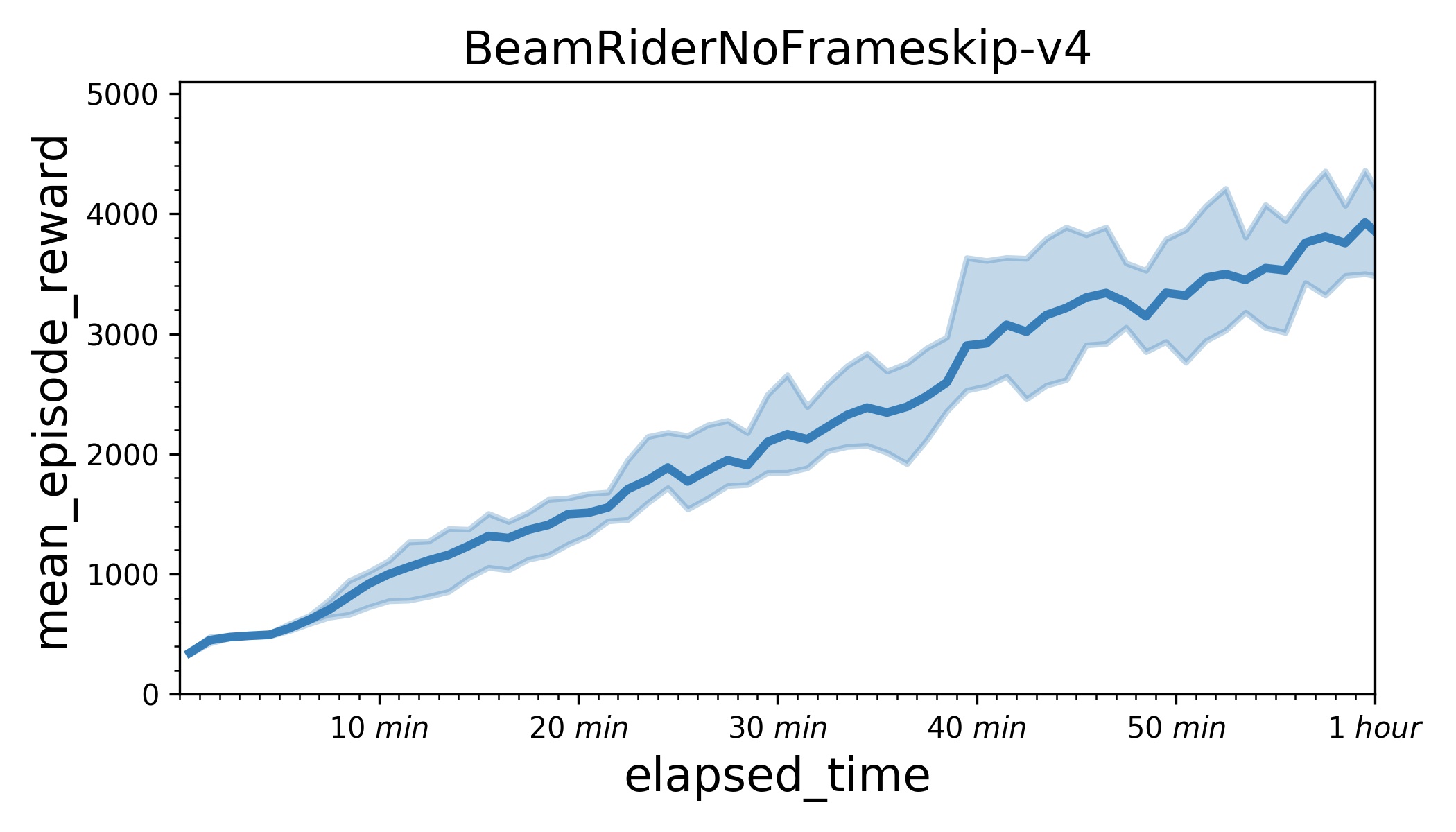
| W: | H:
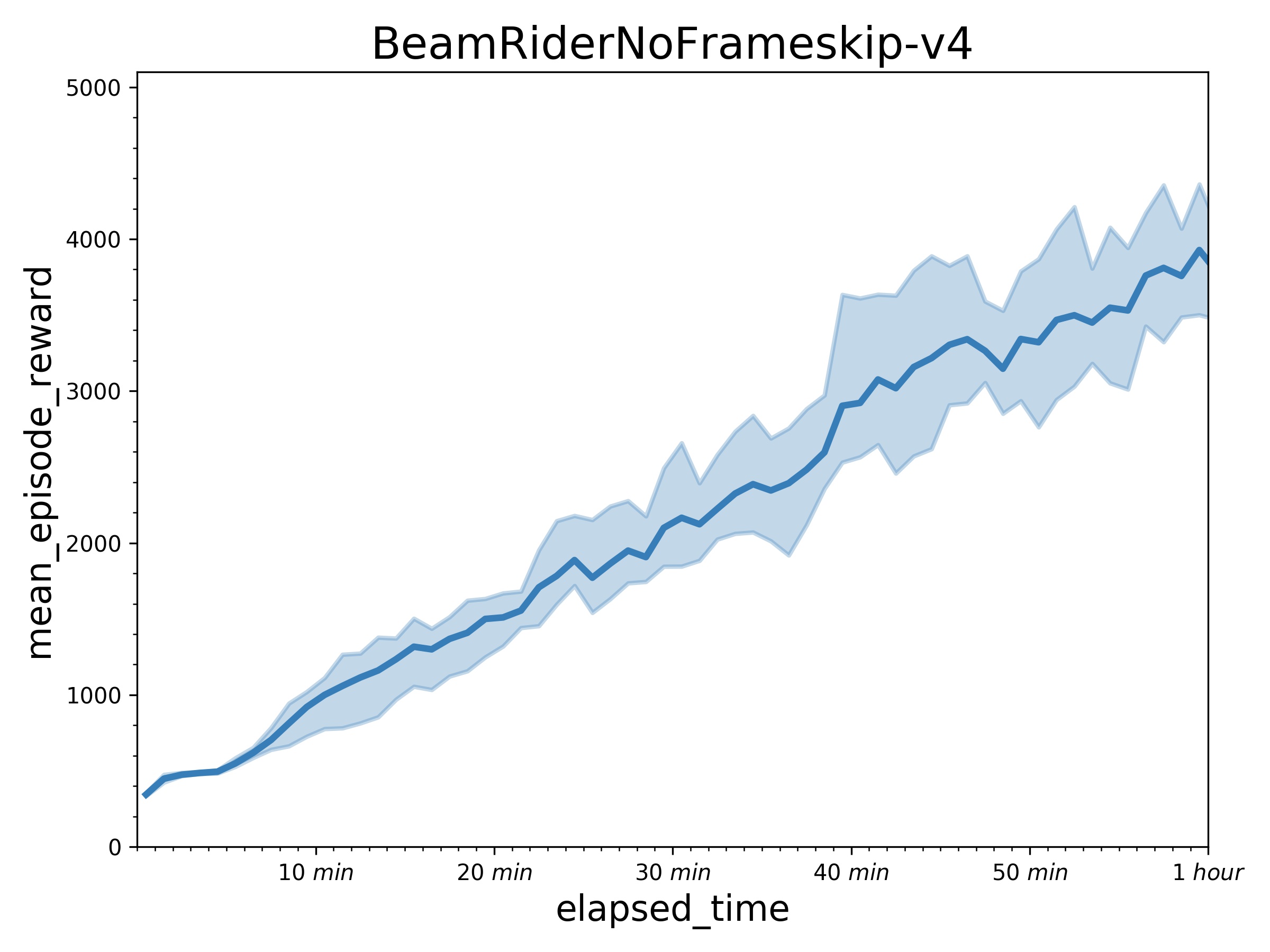
| W: | H:
{kind=link}
{kind=link}
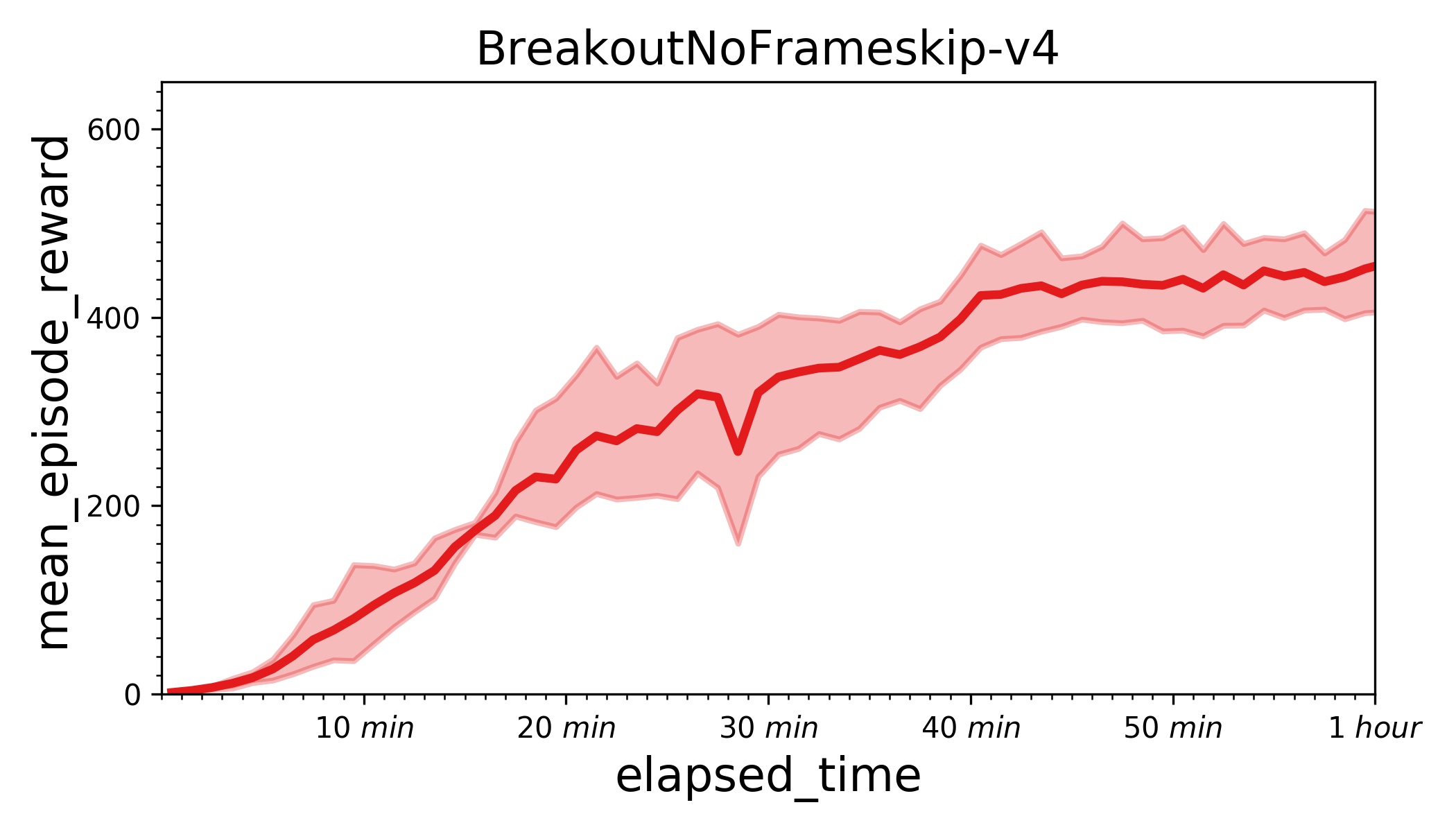
| W: | H:
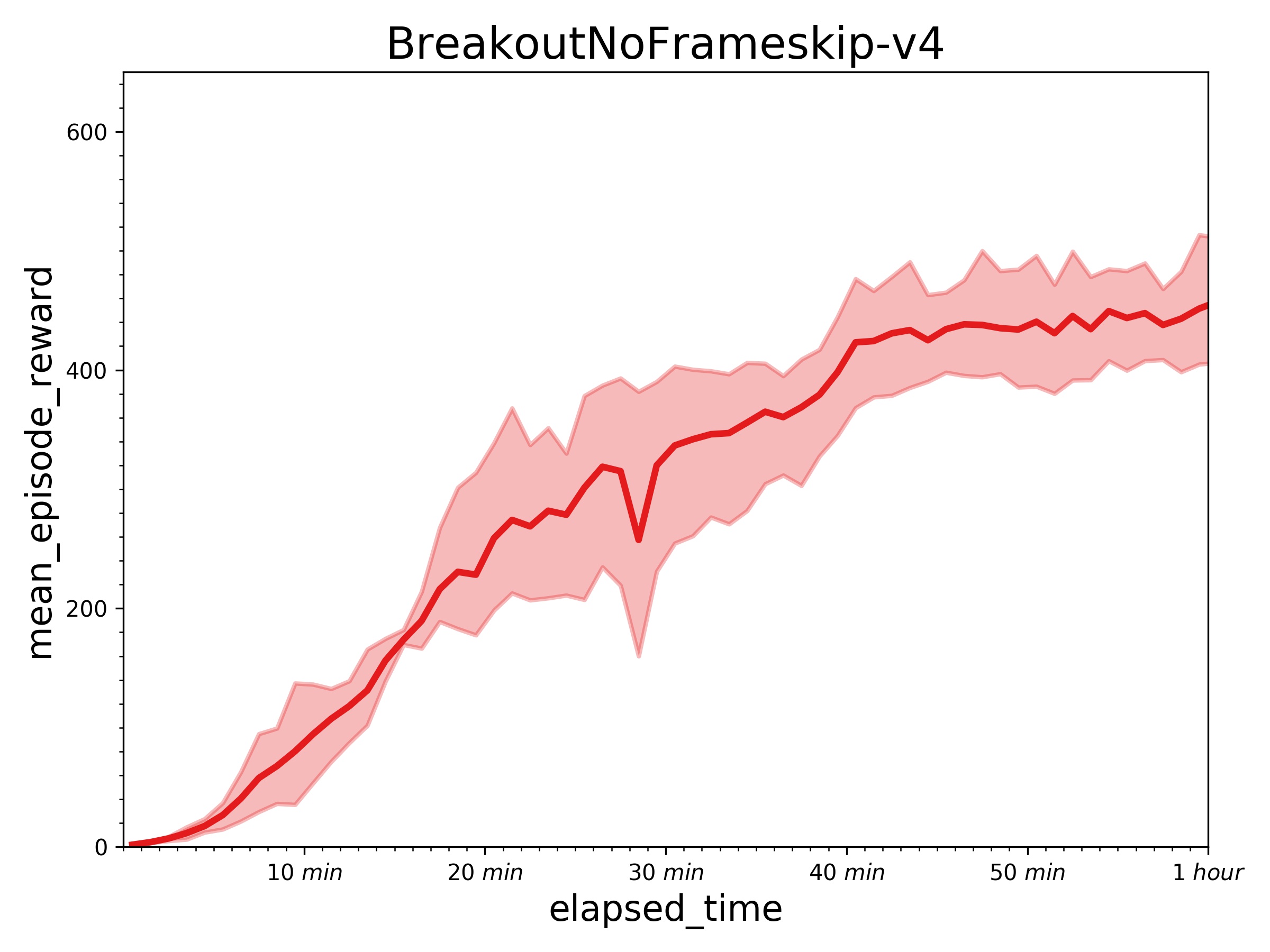
| W: | H:
{kind=link}
{kind=link}
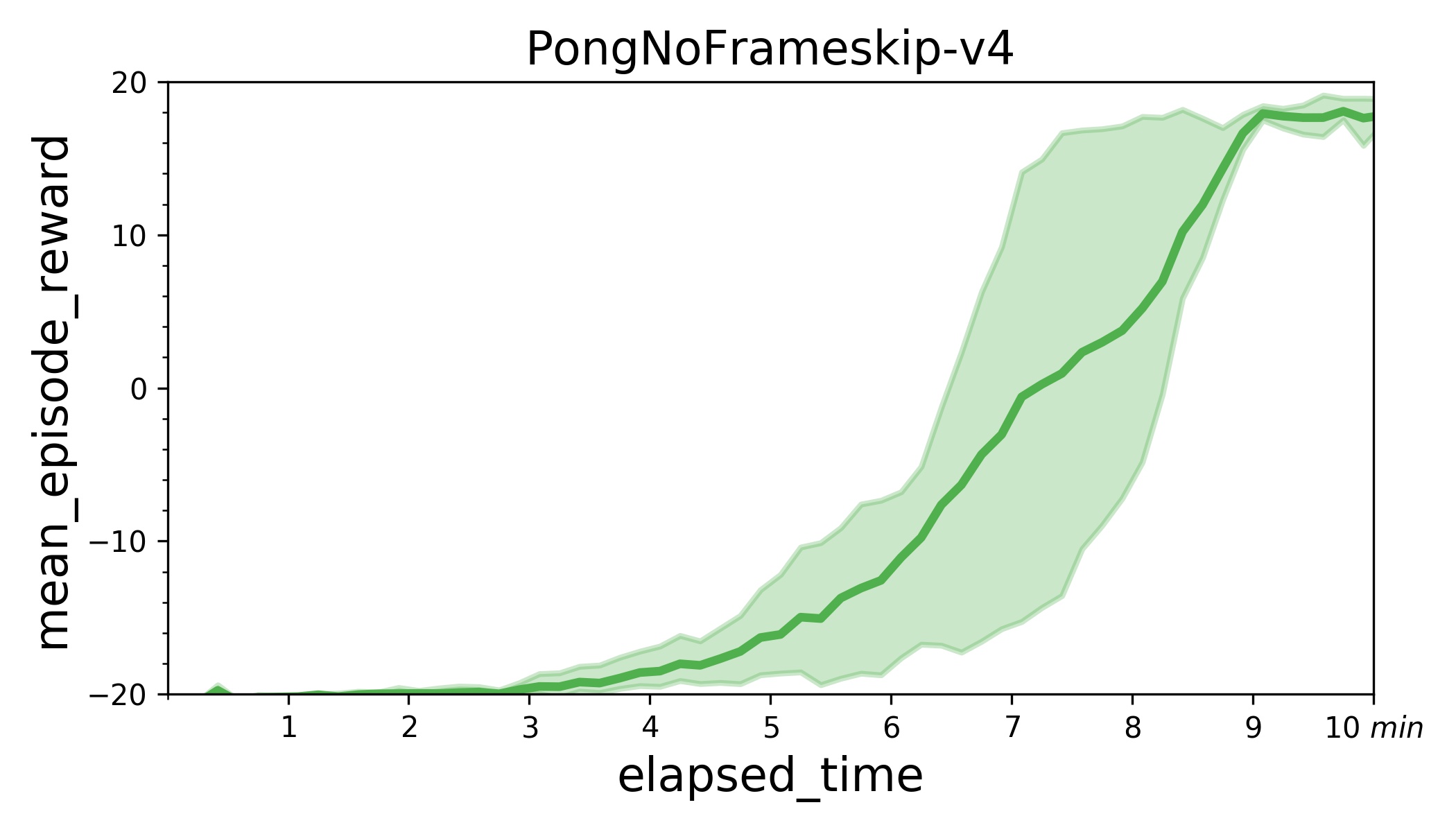
| W: | H:
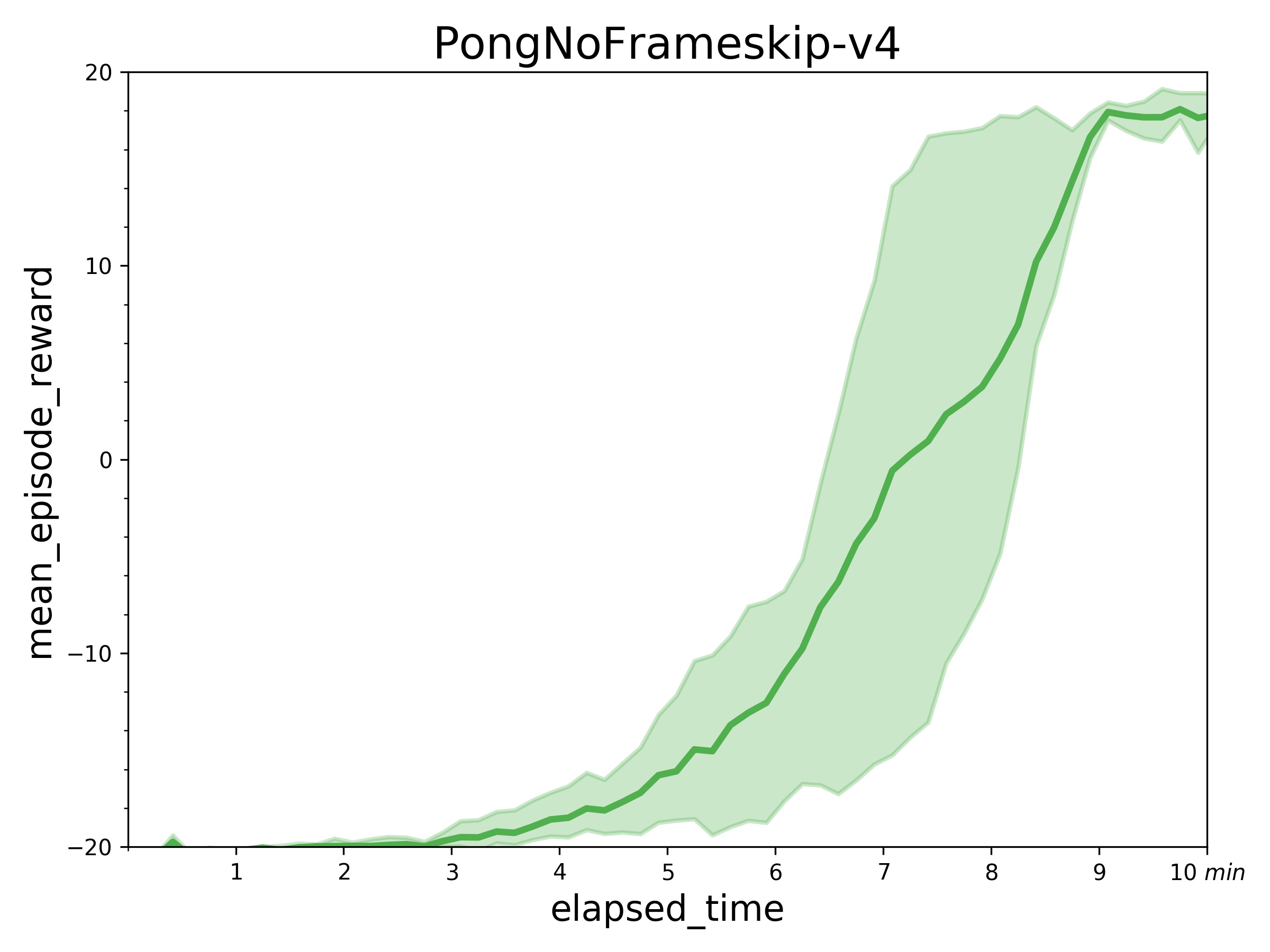
| W: | H:
{kind=link}
{kind=link}
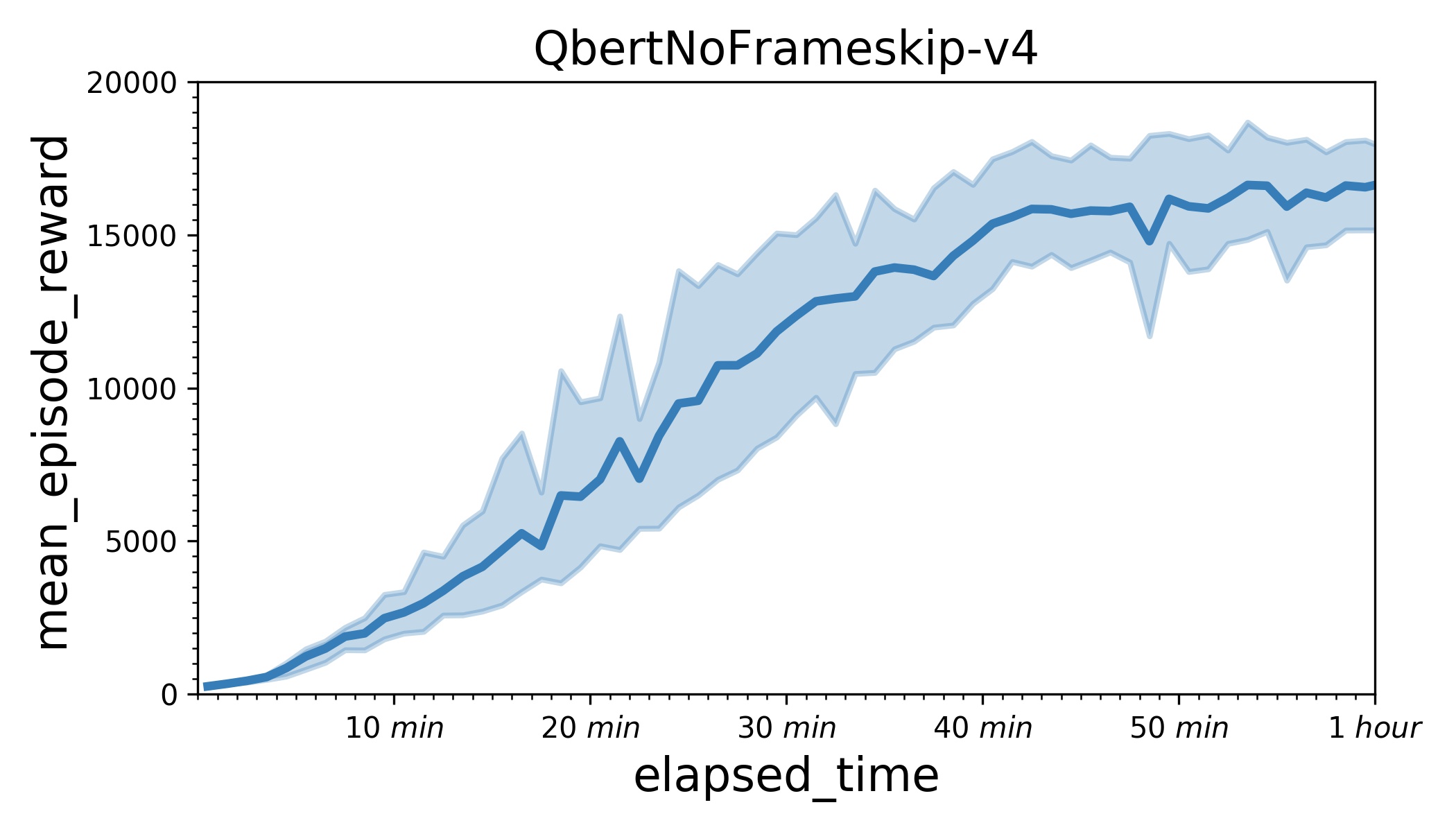
| W: | H:
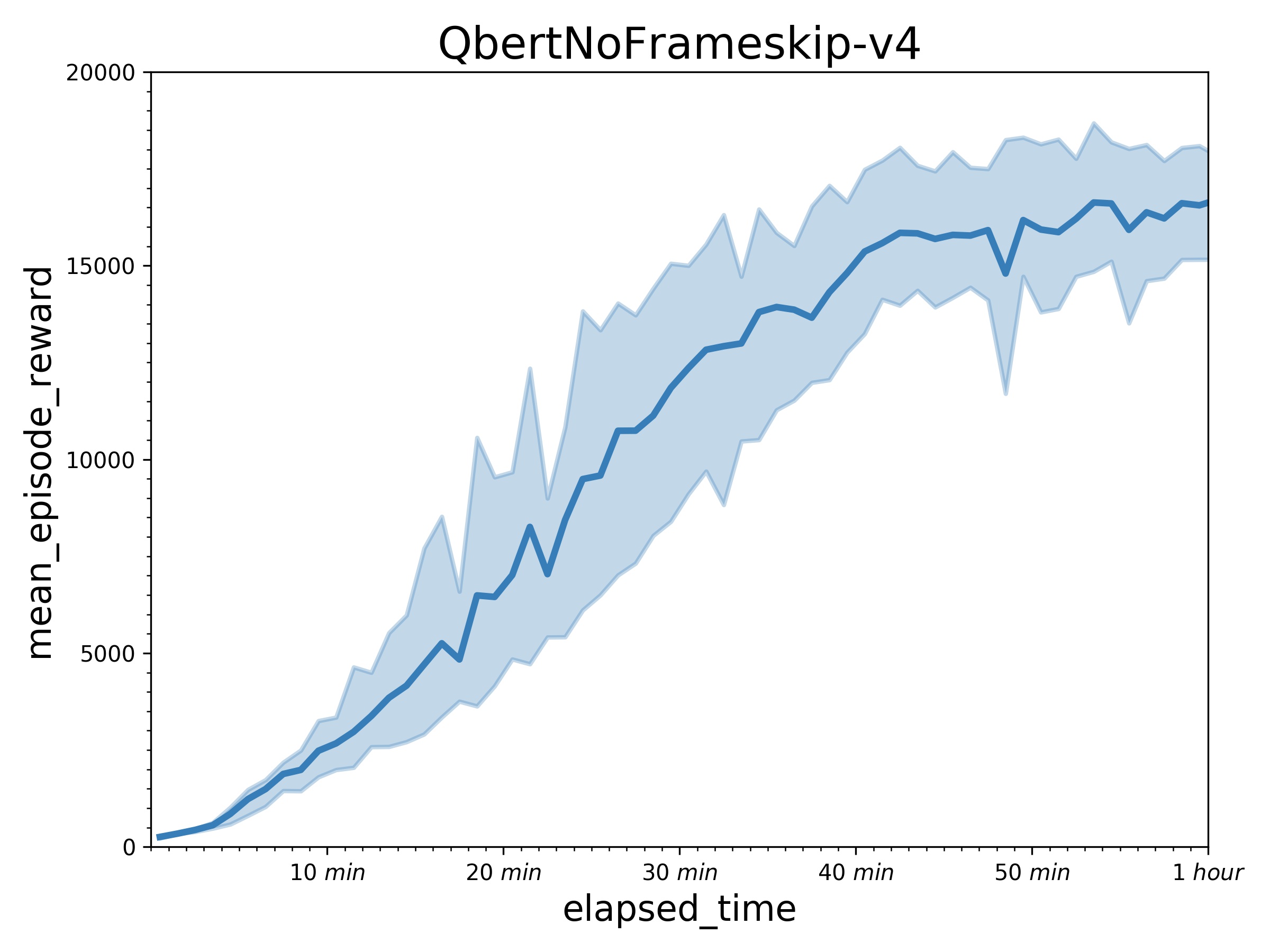
| W: | H:
{kind=link}
{kind=link}
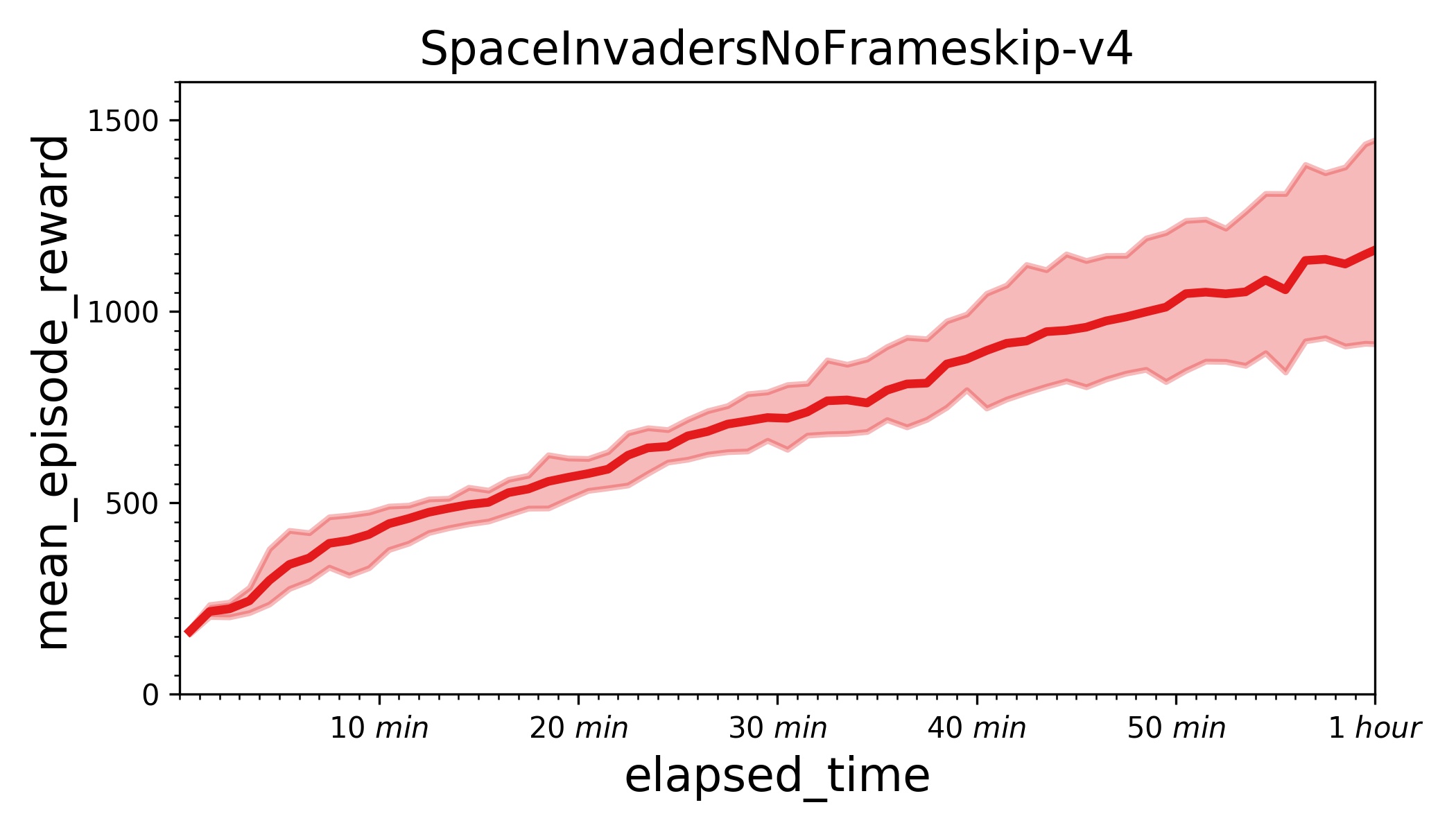
| W: | H:
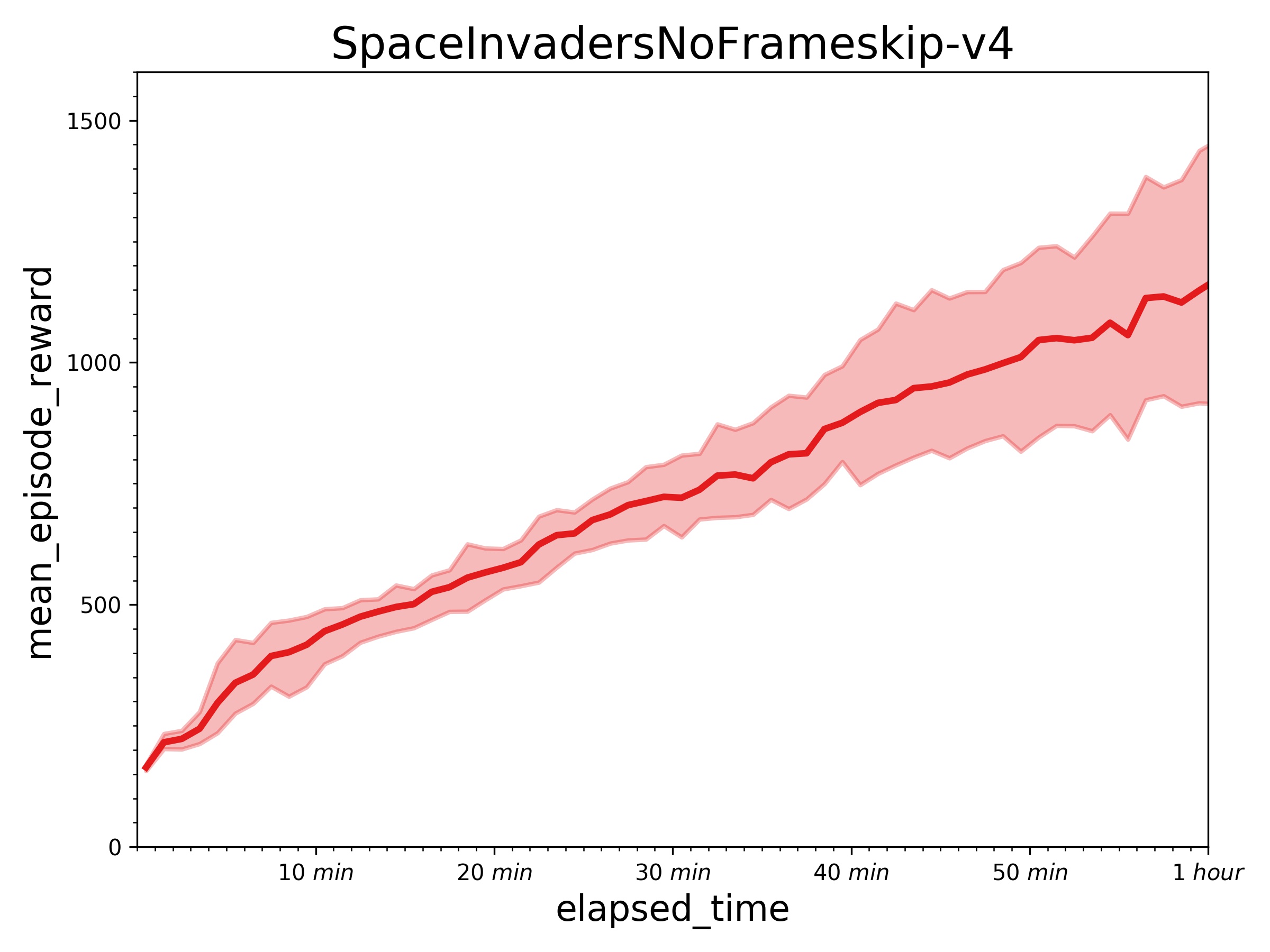
| W: | H:
parl/algorithms/a3c.py
0 → 100644
parl/utils/rl_utils.py
0 → 100644