add design doc (#13)
add design doc
Showing
docs/ct.png
0 → 100644
{kind=link}
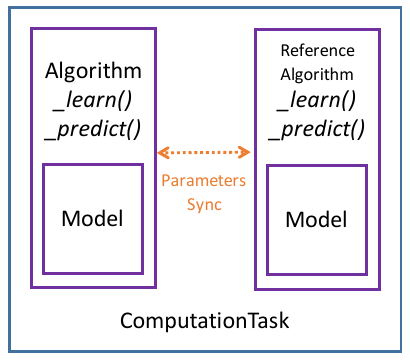
19.0 KB
docs/design_doc.md
0 → 100644
docs/framework.png
0 → 100644
{kind=link}
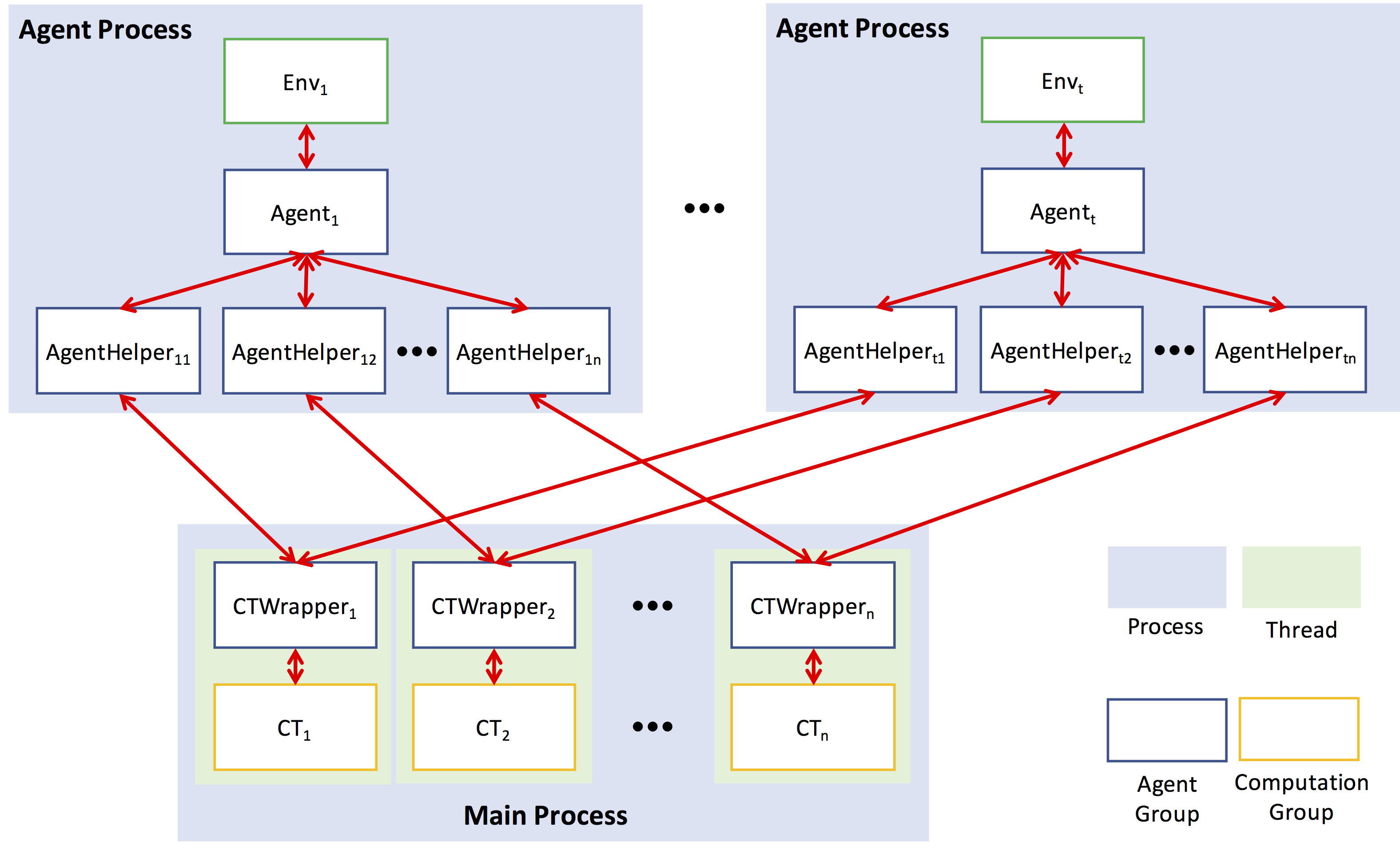
328.6 KB
docs/model.png
0 → 100644
{kind=link}

10.5 KB
docs/relation.png
0 → 100644
{kind=link}
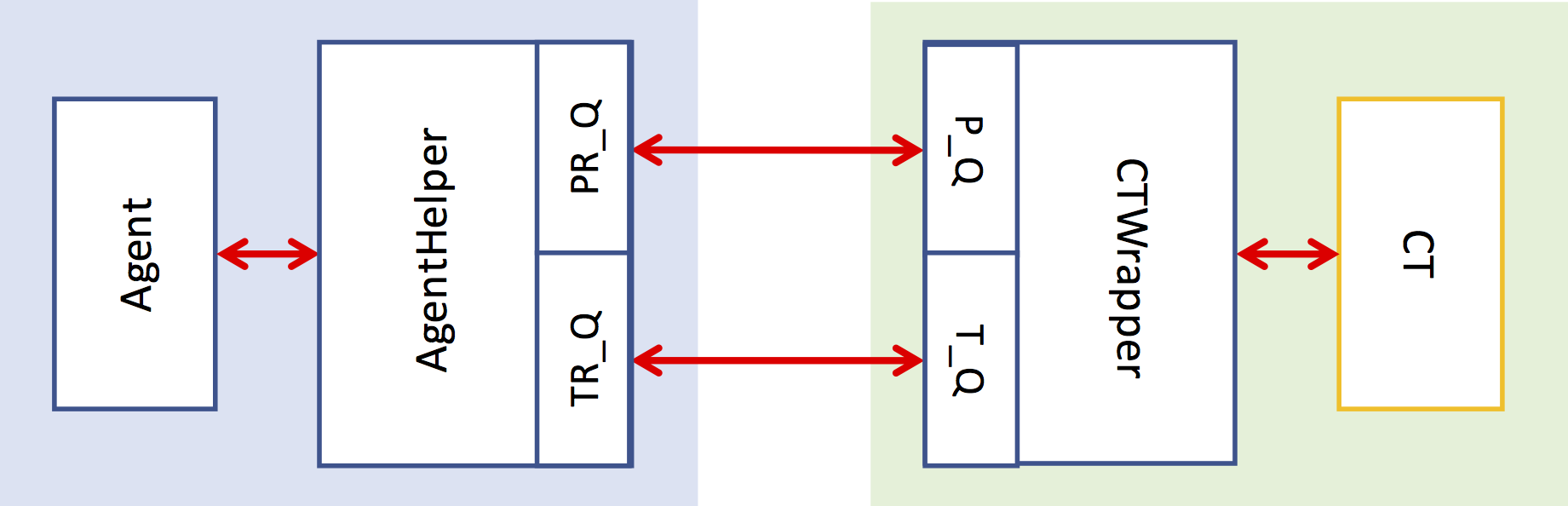
61.6 KB
docs/step.png
0 → 100644
{kind=link}
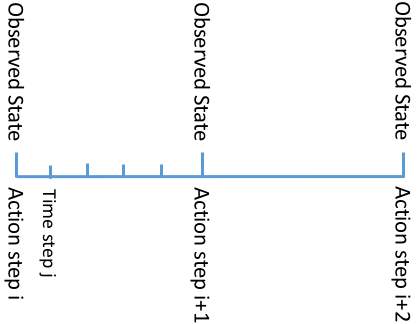
16.9 KB