refine A2C example (#80)
* refine A2C example * fix unittest in python2; fix codestyle * fix codestyle * refine comment
Showing
{kind=link}
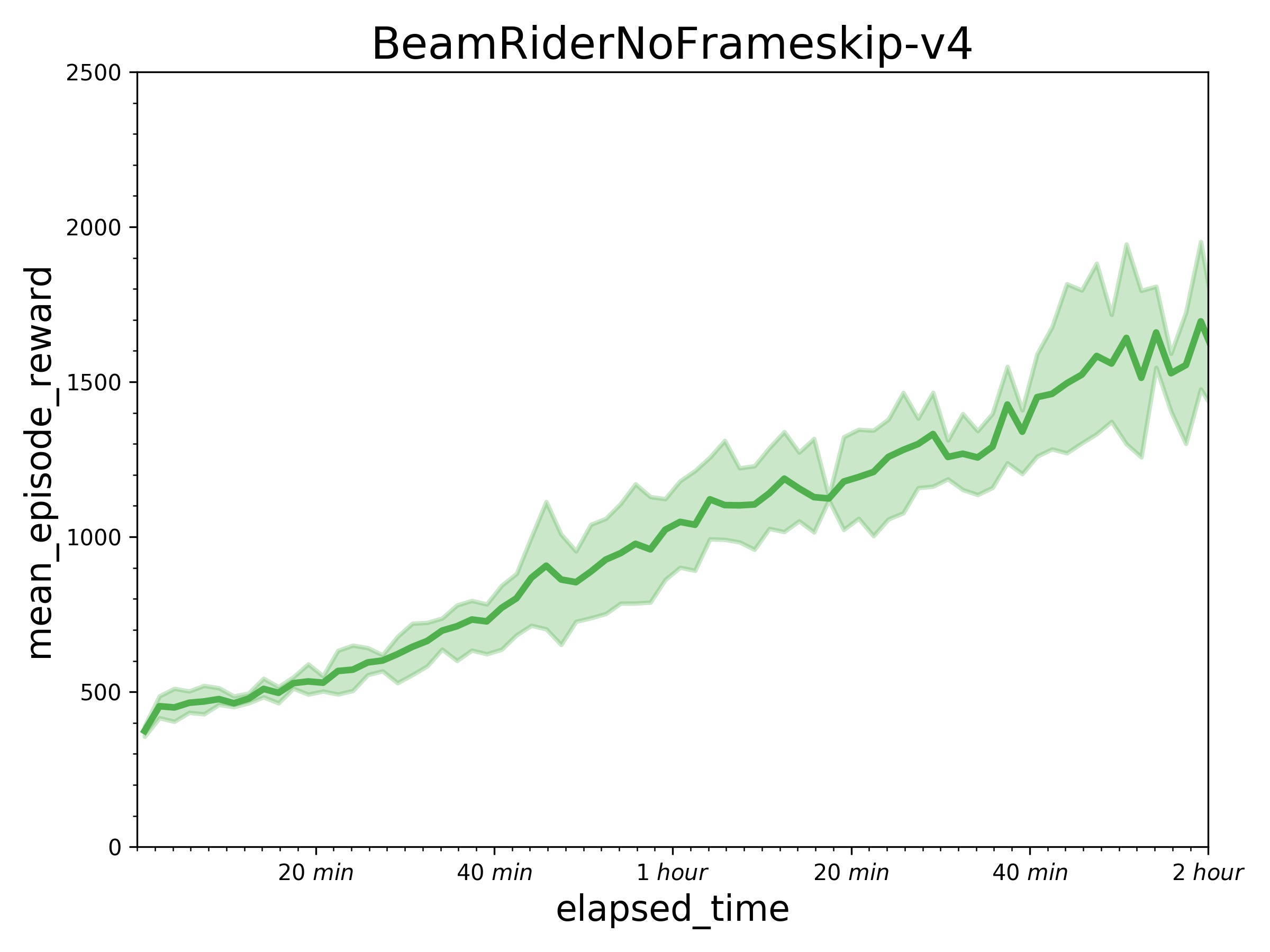
271.6 KB
{kind=link}
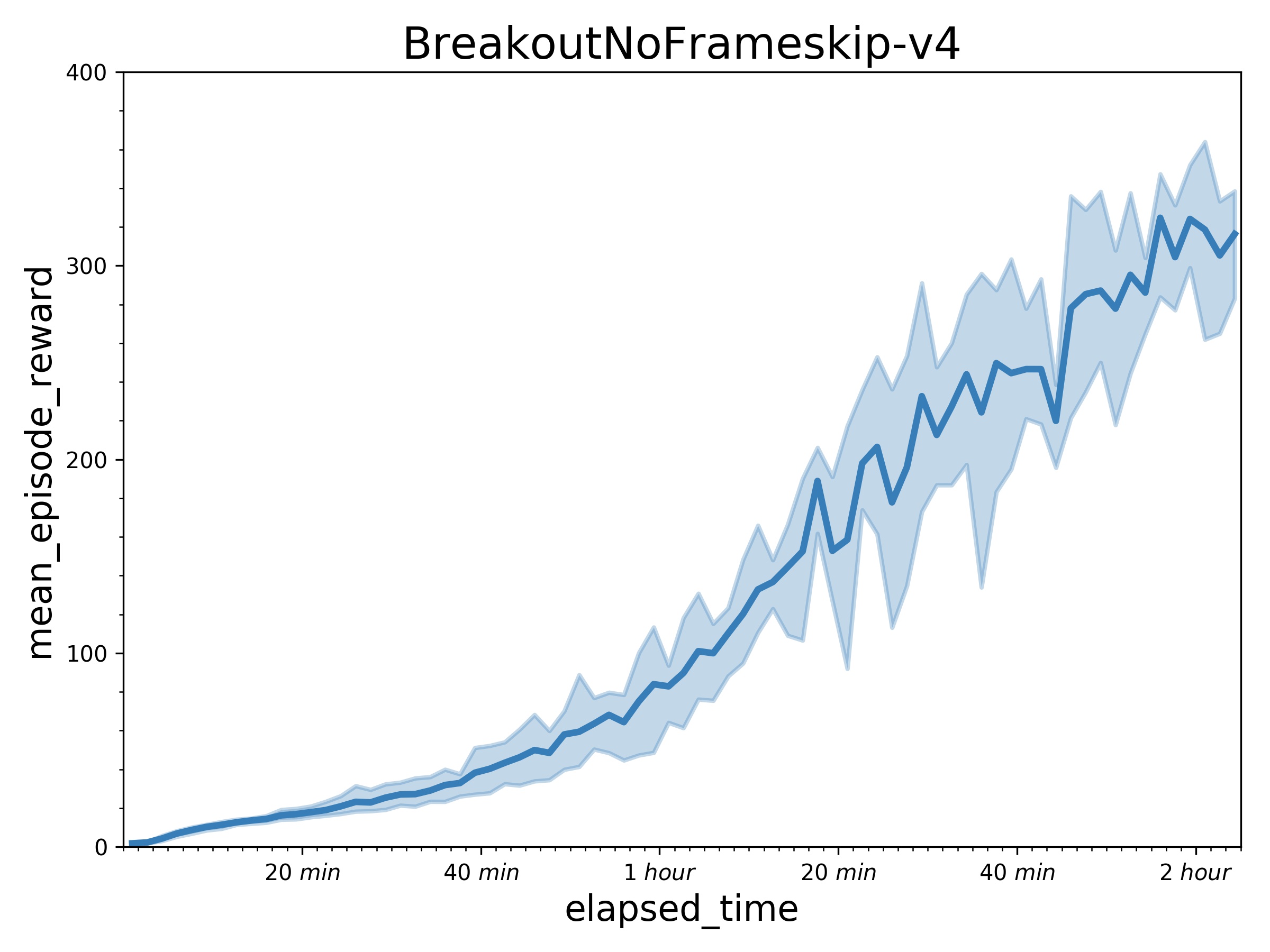
298.5 KB
{kind=link}
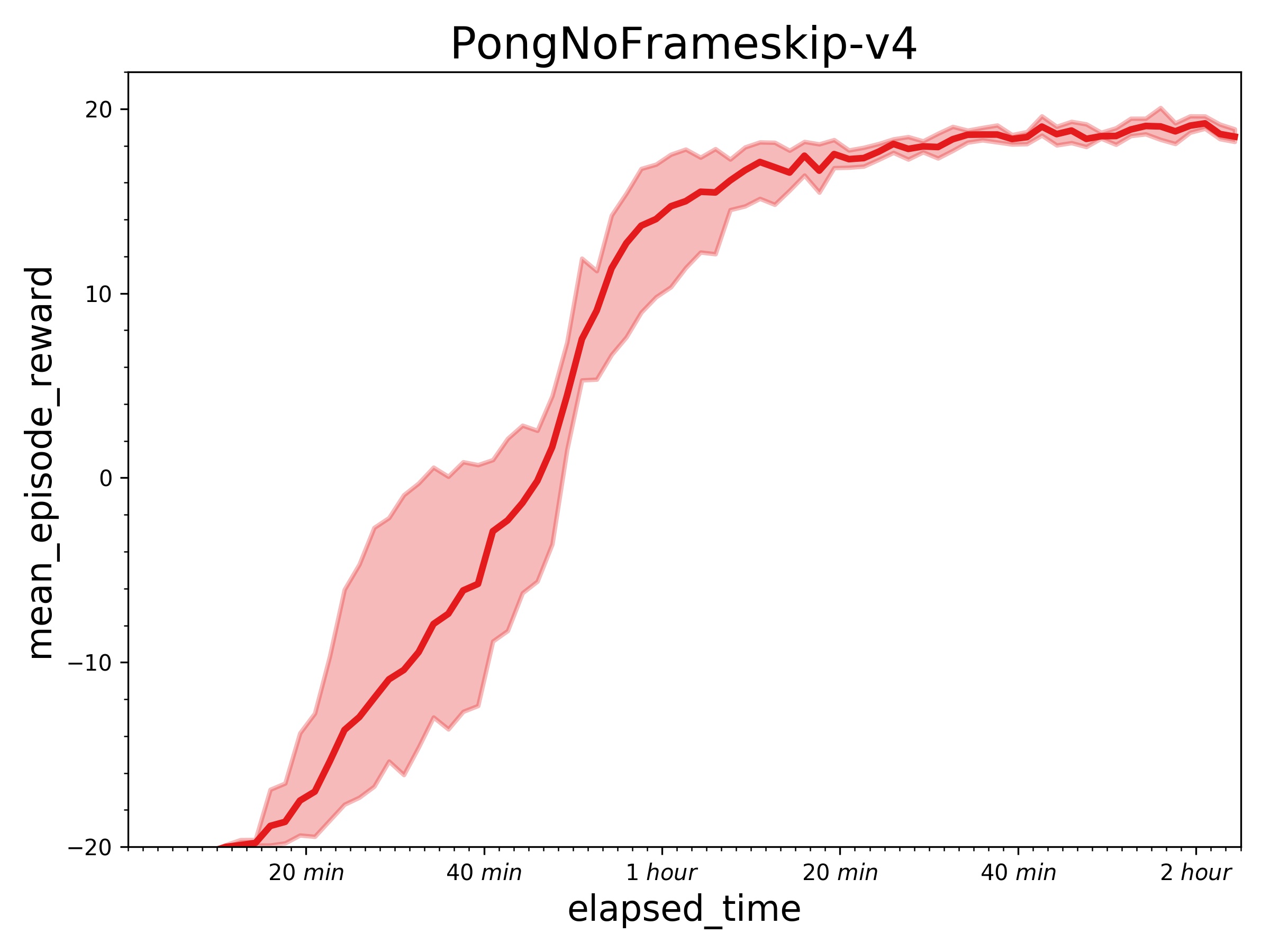
271.9 KB
{kind=link}
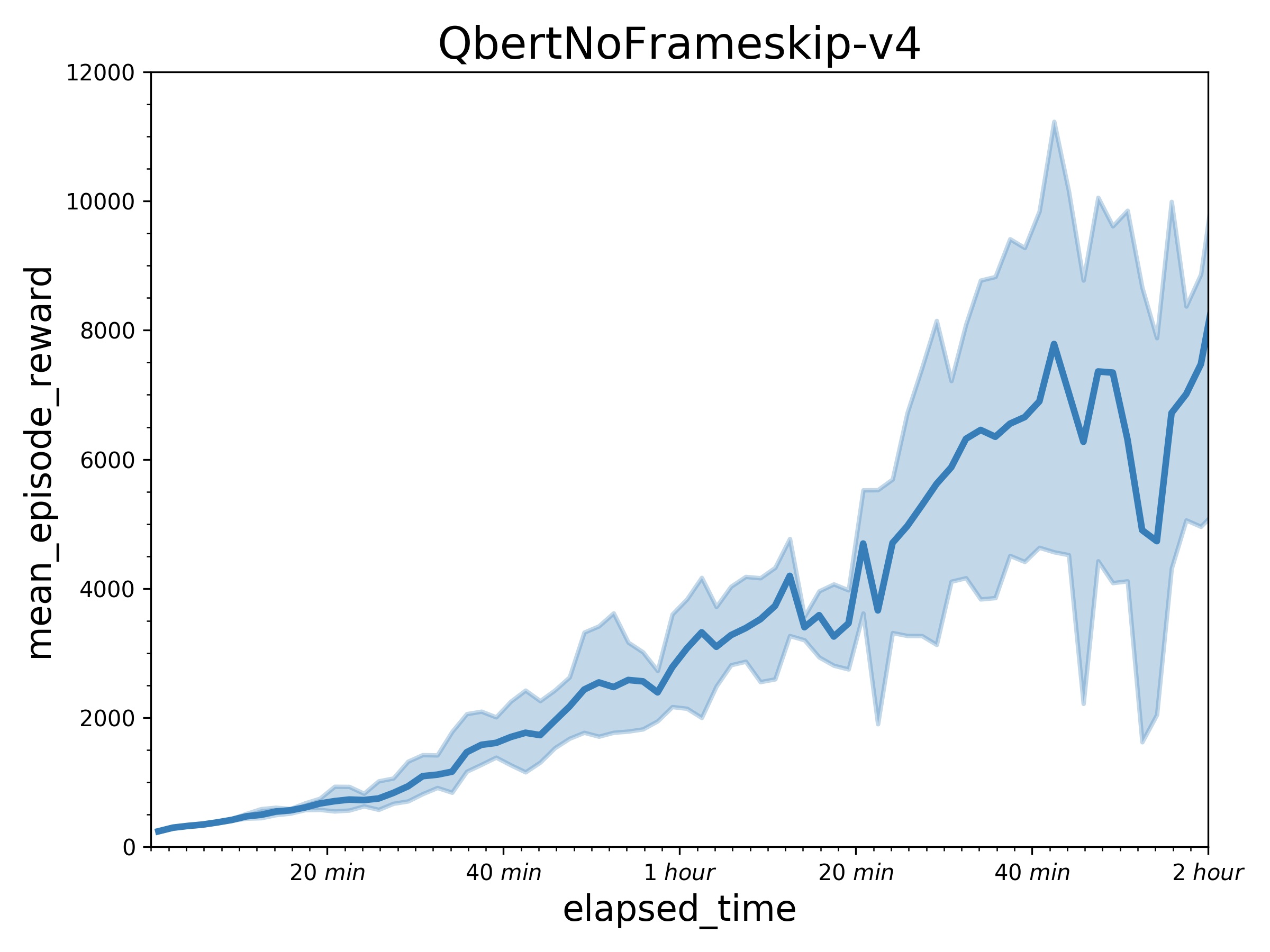
294.2 KB
{kind=link}
276.0 KB
* refine A2C example * fix unittest in python2; fix codestyle * fix codestyle * refine comment
271.6 KB
298.5 KB
271.9 KB
294.2 KB
276.0 KB