fix guides index
Showing
文件已移动
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
{kind=link}
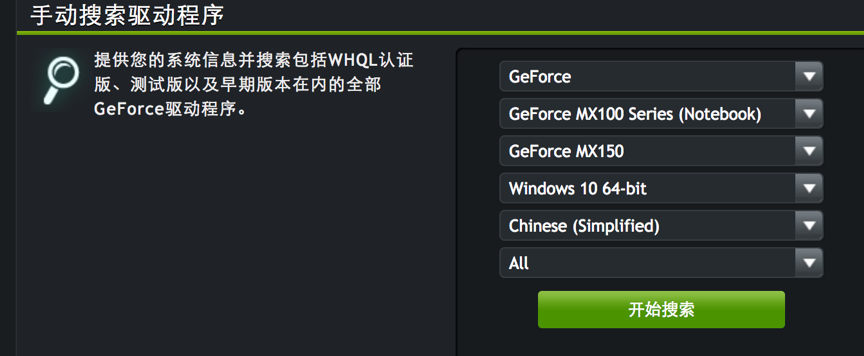
111.7 KB
{kind=link}
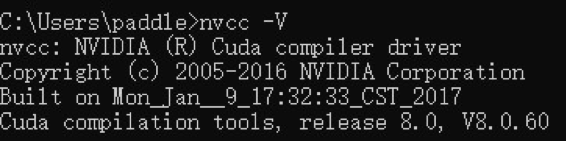
56.7 KB
{kind=link}
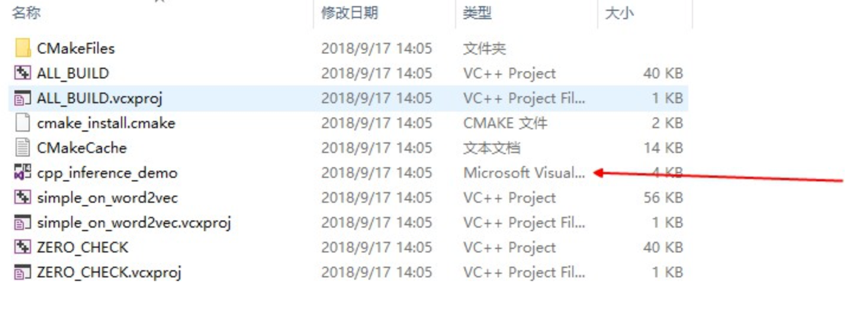
245.1 KB
{kind=link}
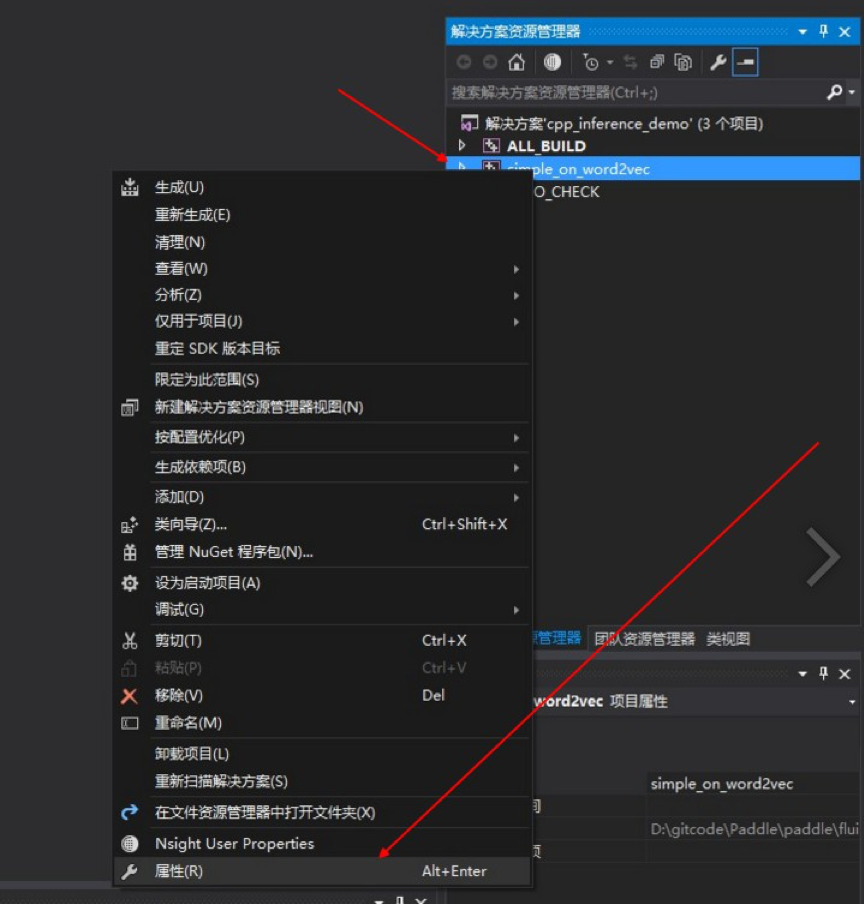
492.8 KB
{kind=link}
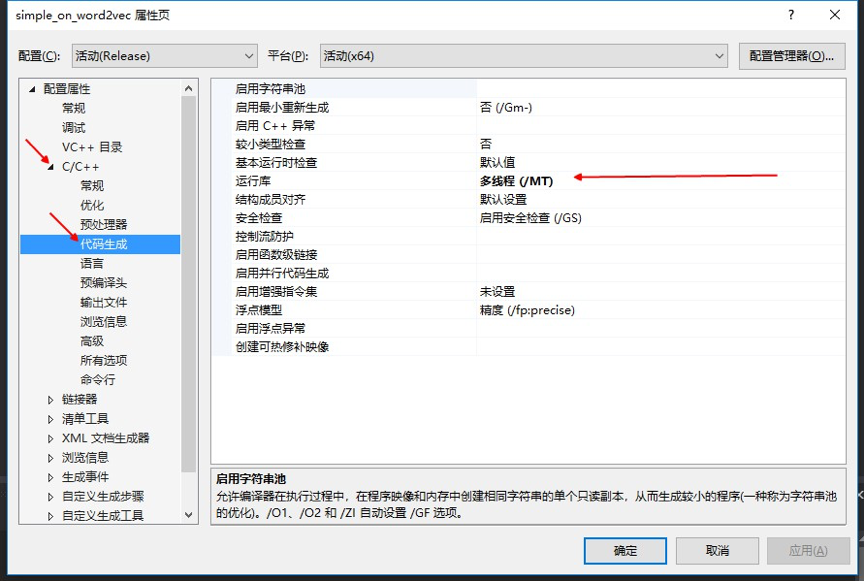
324.8 KB
{kind=link}
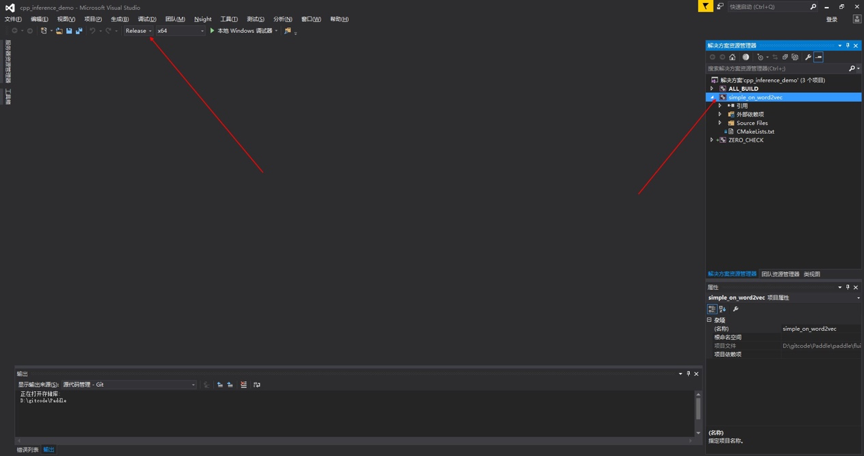
121.6 KB
{kind=link}
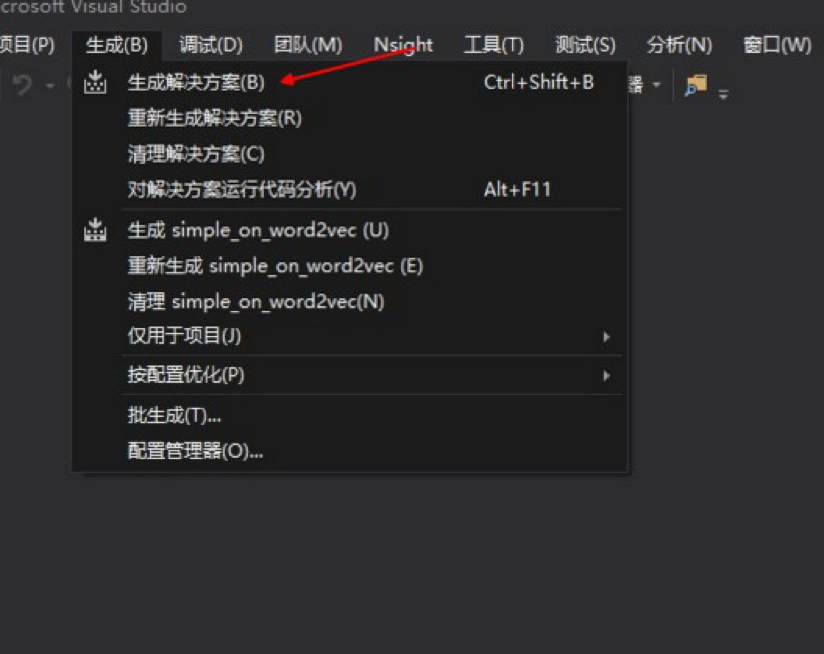
278.1 KB
{kind=link}

86.5 KB
{kind=link}
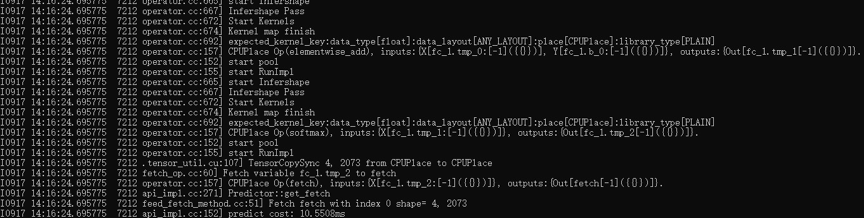
126.1 KB
{kind=link}

87.8 KB
{kind=link}

46.2 KB
{kind=link}

238.6 KB
{kind=link}

318.8 KB
{kind=link}

78.4 KB
{kind=link}
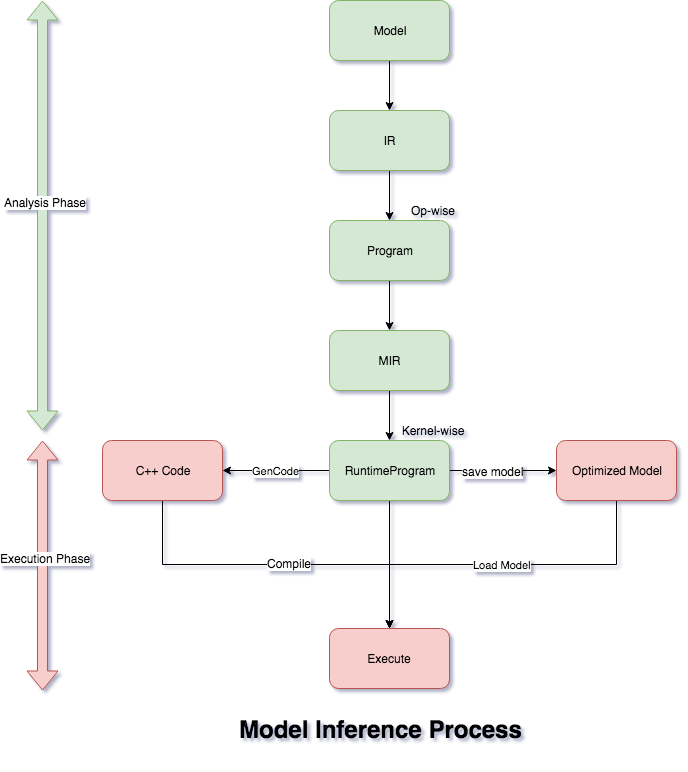
68.6 KB
{kind=link}

39.4 KB
{kind=link}
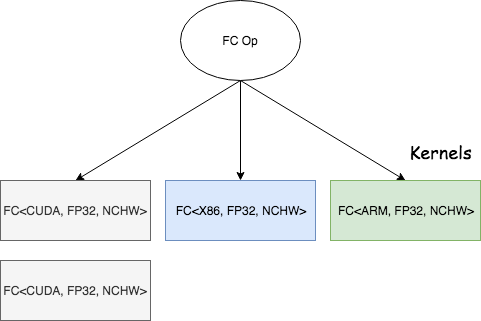
24.7 KB
{kind=link}

44.3 KB
{kind=link}

45.3 KB
{kind=link}

98.2 KB
{kind=link}

109.7 KB
{kind=link}

70.9 KB
{kind=link}

320.5 KB
{kind=link}

42.5 KB
{kind=link}

75.6 KB
{kind=link}

39.1 KB
{kind=link}

13.9 KB
{kind=link}

24.7 KB
{kind=link}

45.3 KB
{kind=link}

22.6 KB
{kind=link}

23.7 KB
{kind=link}

163.6 KB
{kind=link}

138.9 KB
{kind=link}

33.9 KB
{kind=link}

39.3 KB
{kind=link}

125.1 KB
{kind=link}

182.4 KB
{kind=link}
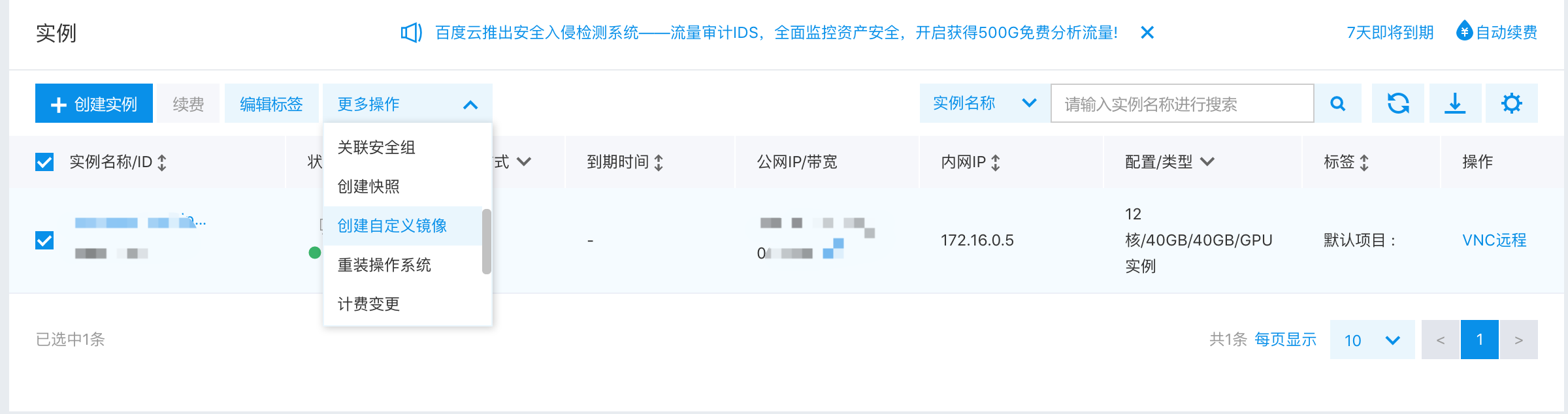
164.0 KB
{kind=link}

146.2 KB
{kind=link}
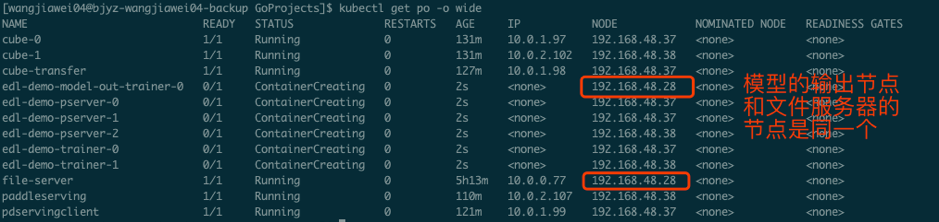
164.3 KB
{kind=link}

114.9 KB
{kind=link}
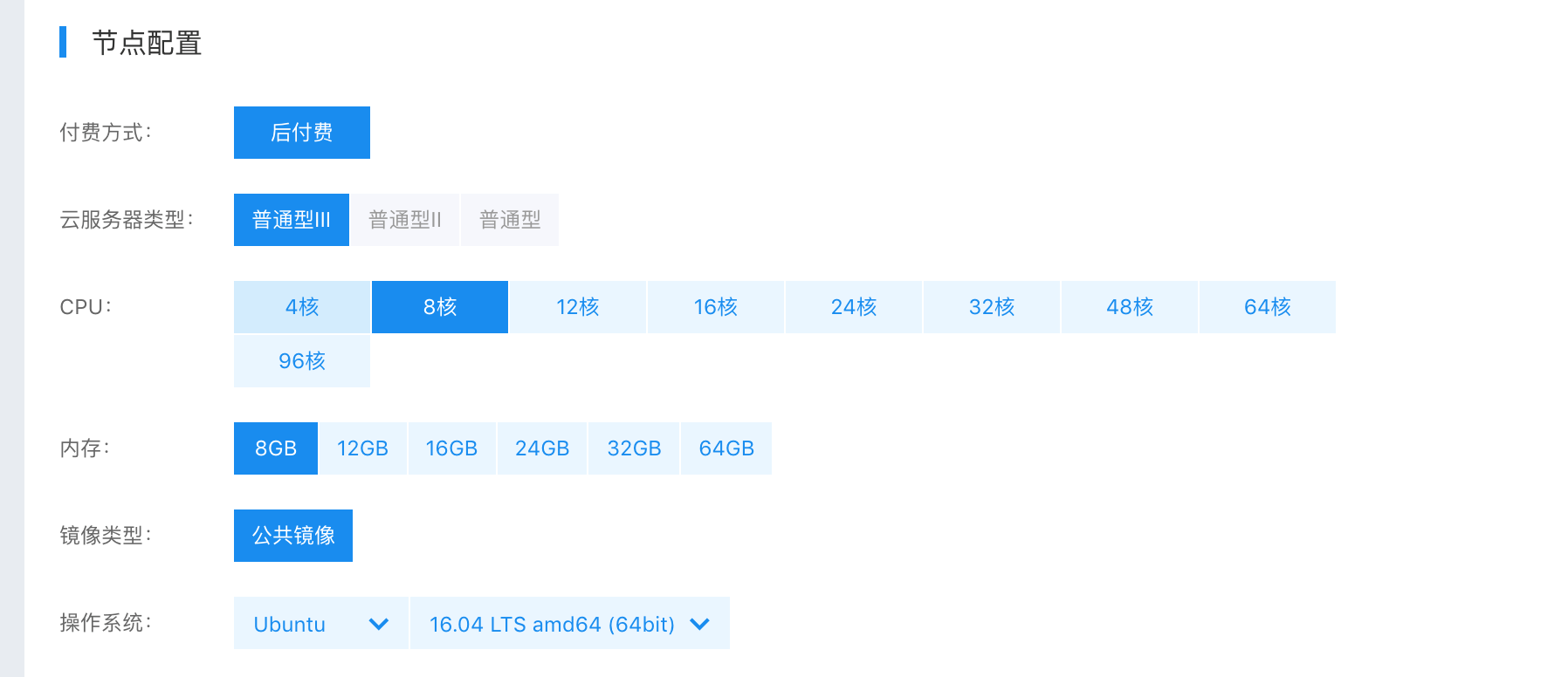
74.6 KB
{kind=link}
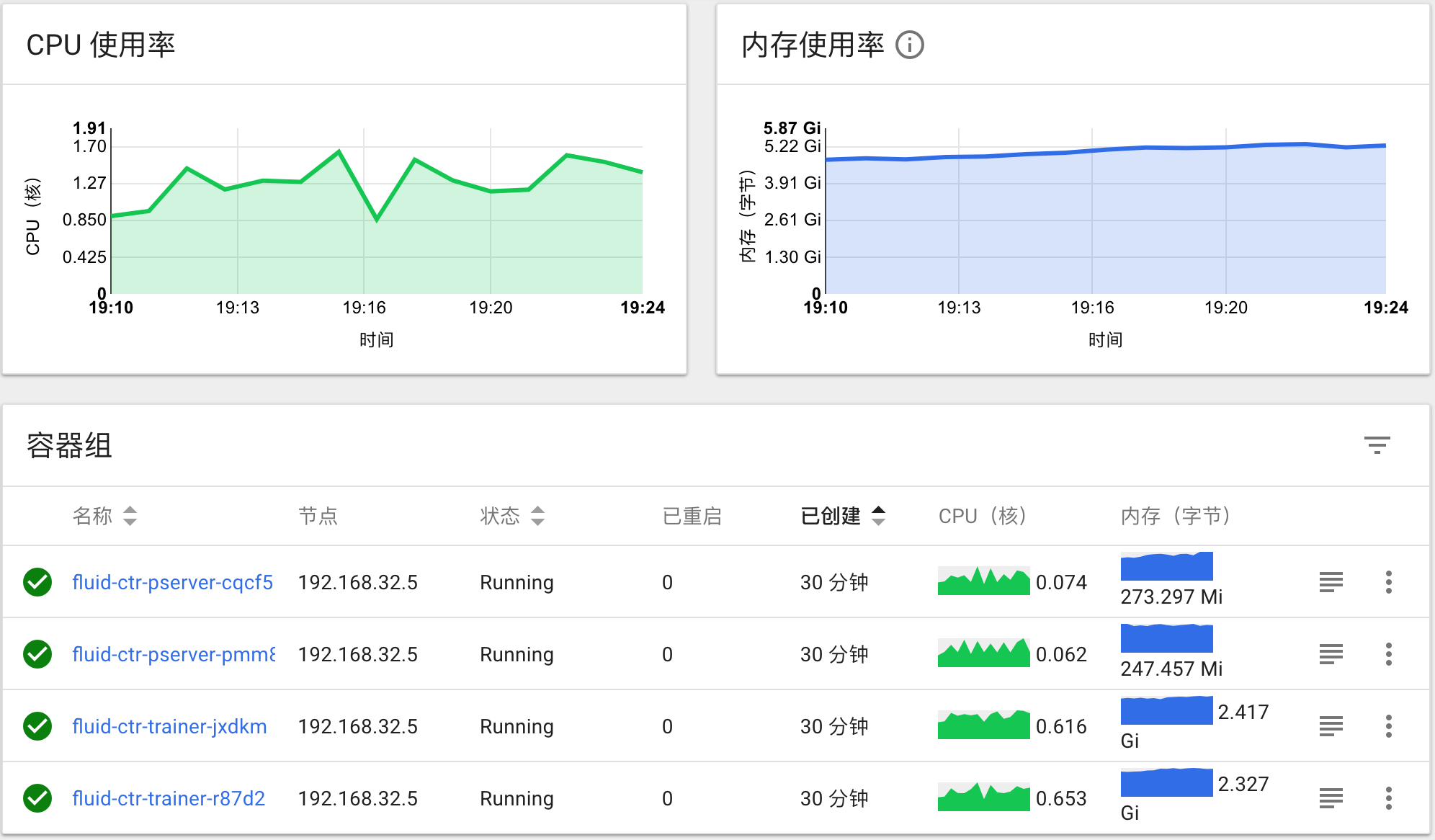
186.9 KB
{kind=link}

341.8 KB
{kind=link}

777.4 KB
{kind=link}

155.7 KB
{kind=link}
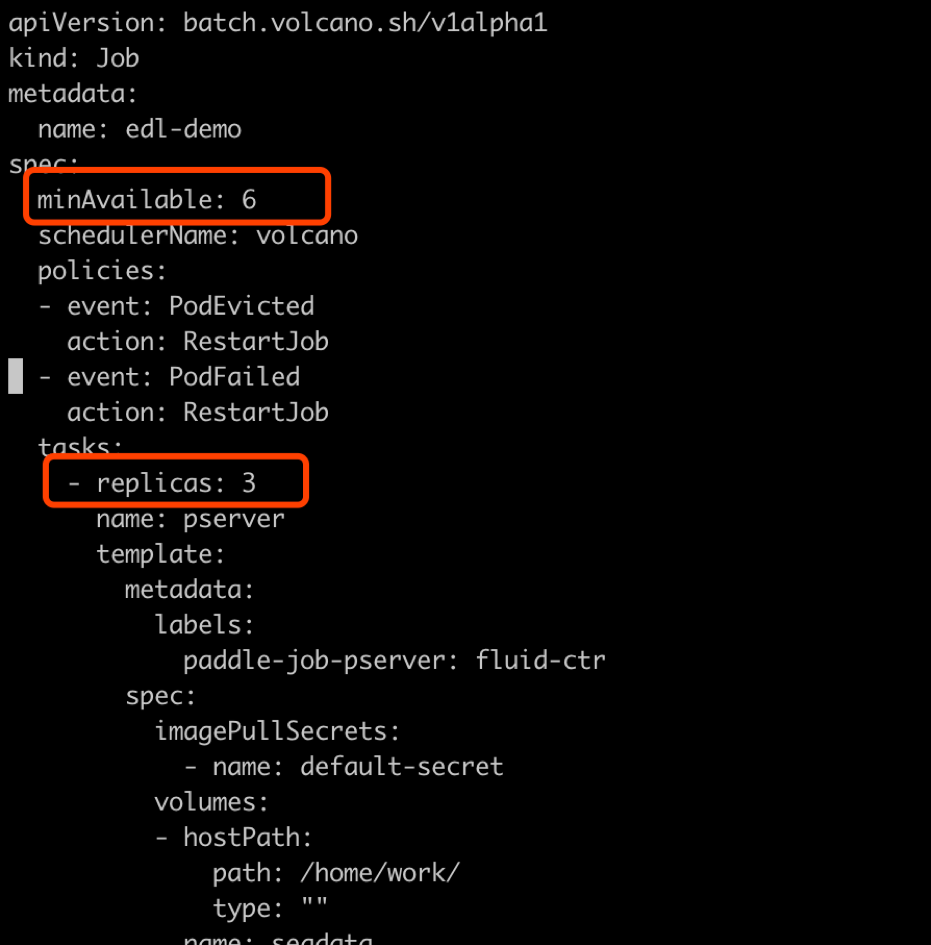
131.0 KB
{kind=link}
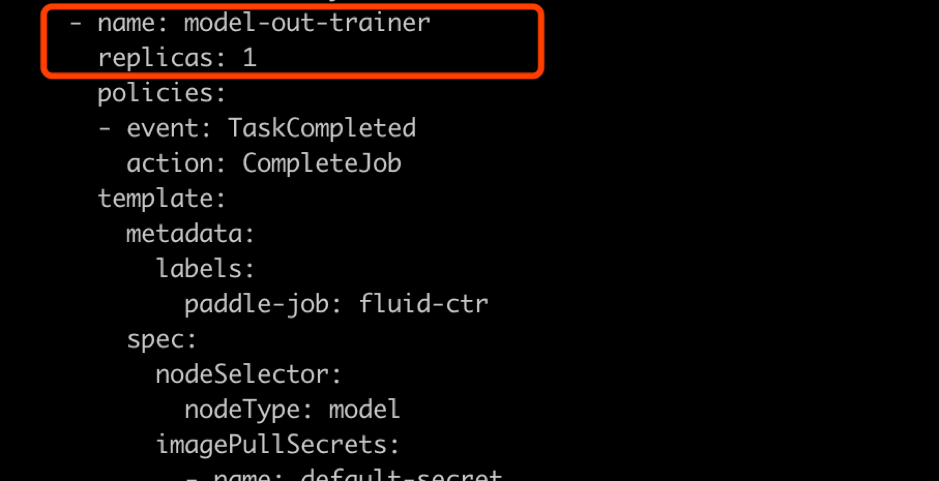
65.6 KB
{kind=link}
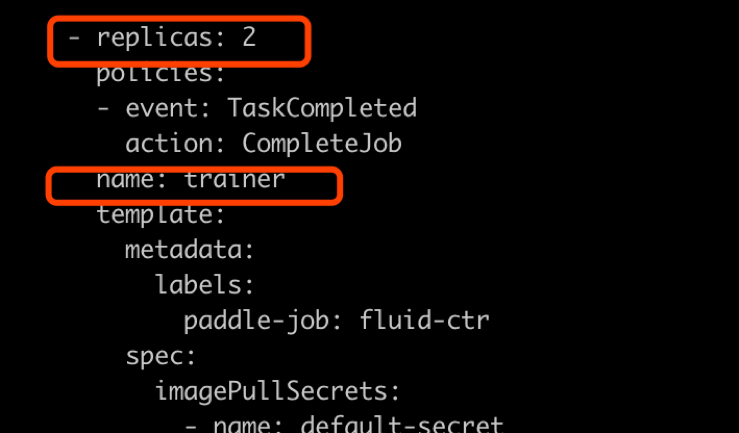
56.3 KB
{kind=link}

104.4 KB
{kind=link}
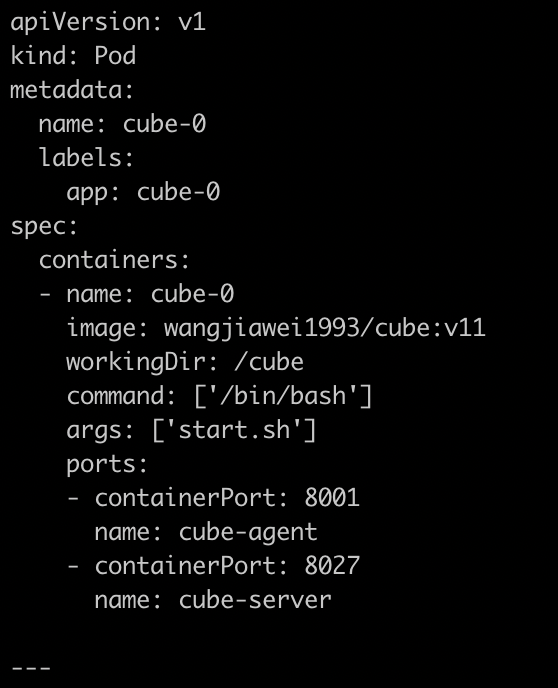
178.2 KB
{kind=link}
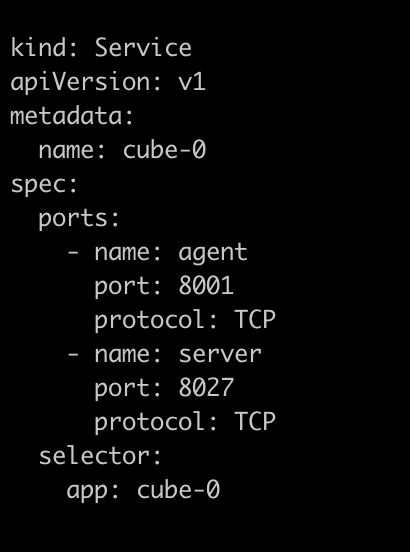
107.1 KB
文件已添加
{kind=link}

19.5 KB
文件已添加
{kind=link}

31.8 KB
{kind=link}

150.9 KB
{kind=link}

98.0 KB
{kind=link}
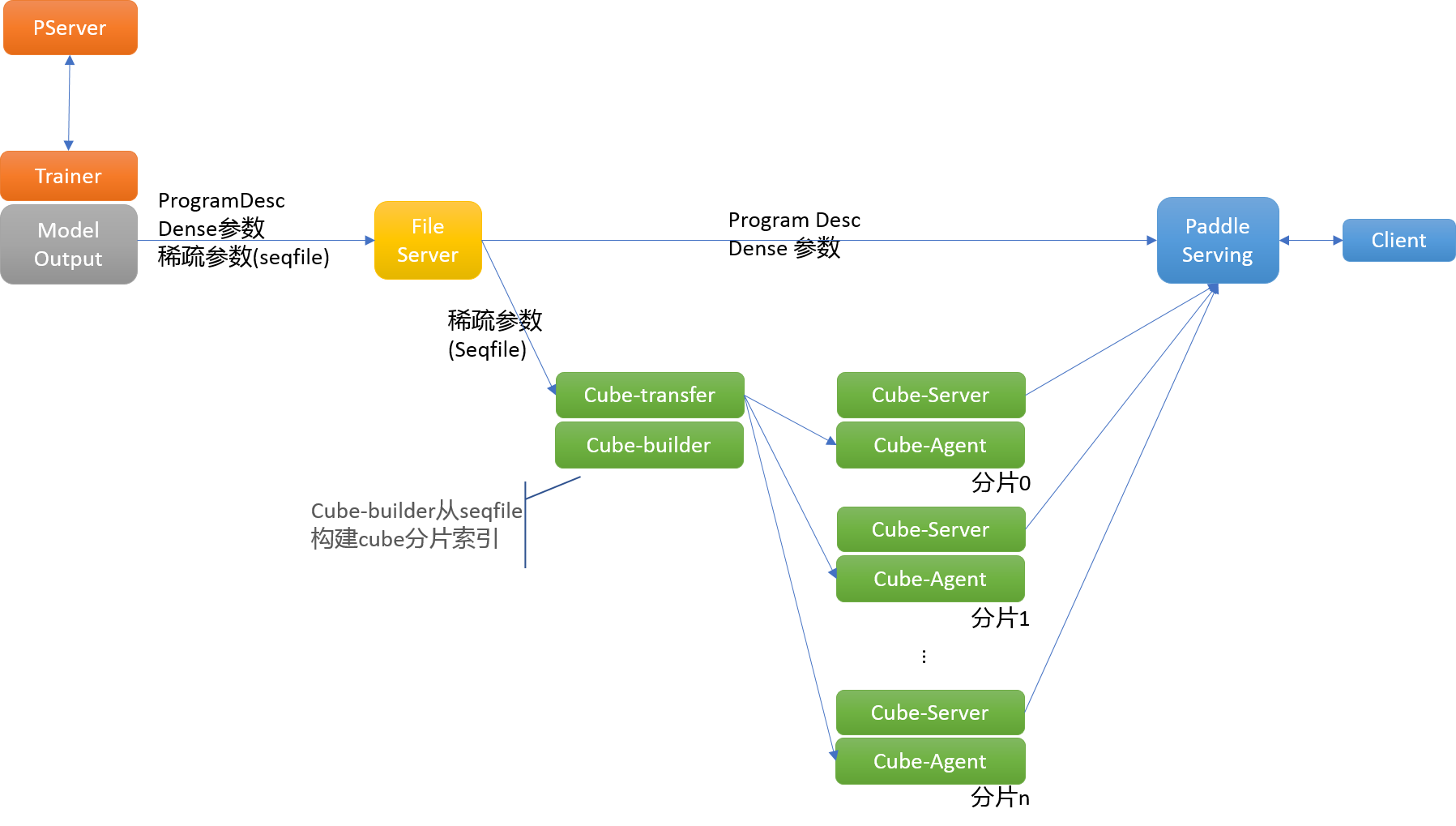
107.3 KB
{kind=link}
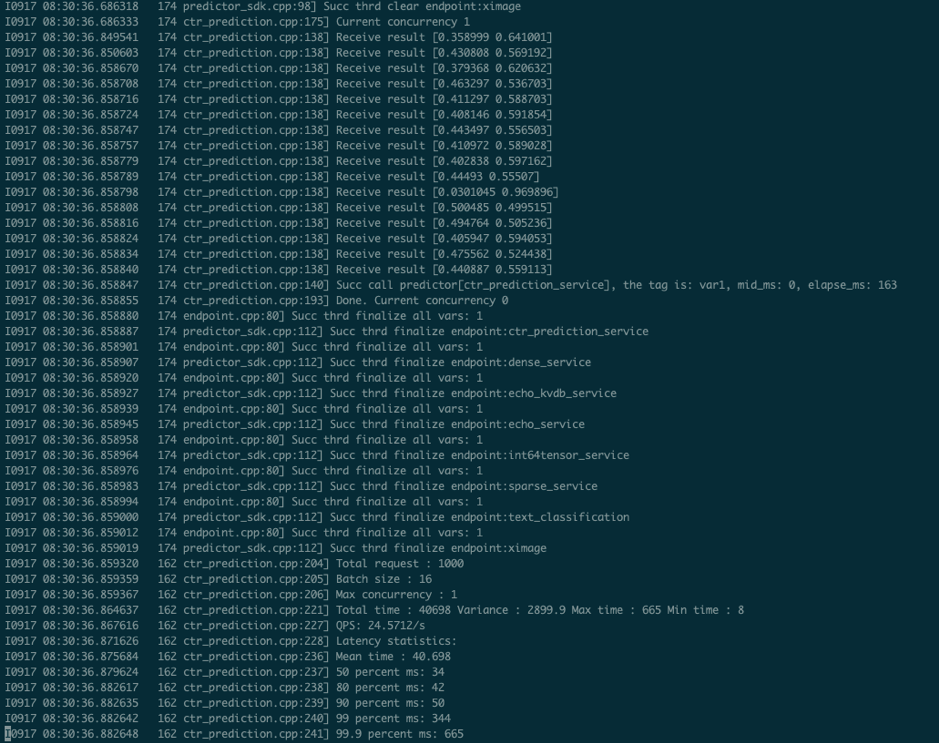
547.4 KB
{kind=link}
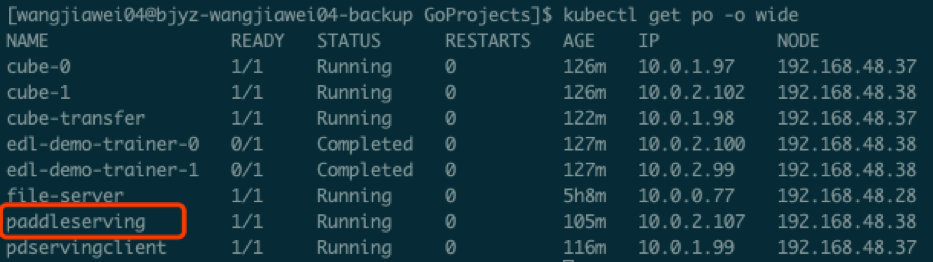
145.4 KB
{kind=link}

104.8 KB
{kind=link}
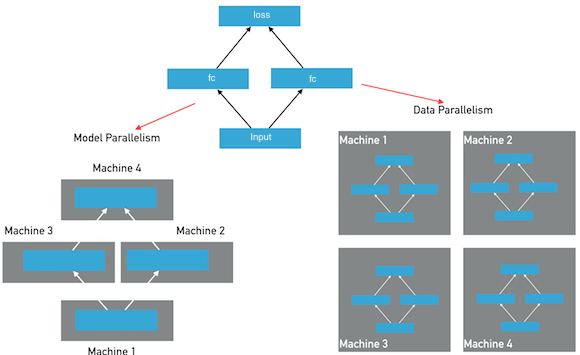
61.2 KB
{kind=link}
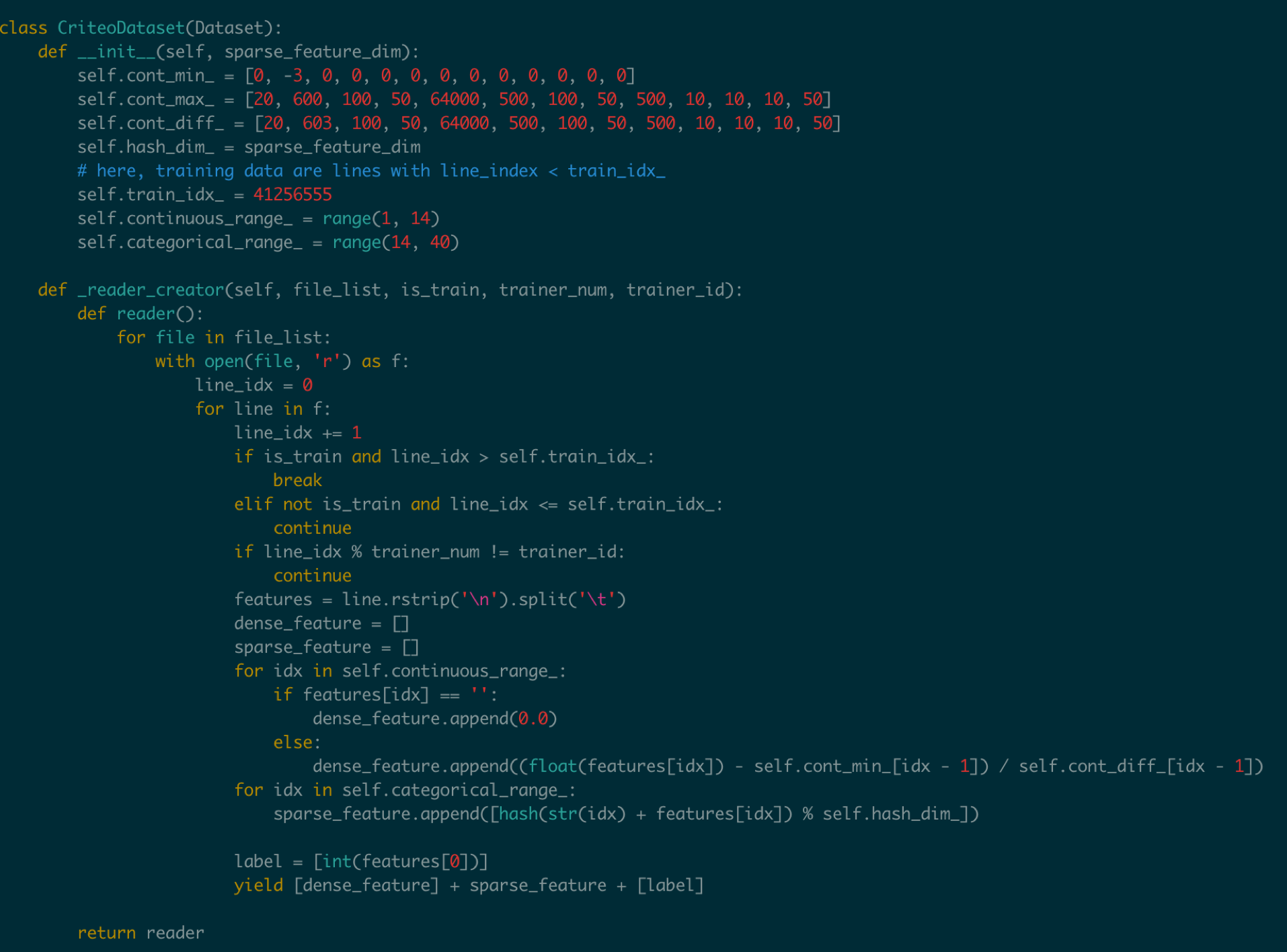
456.1 KB
{kind=link}
209.0 KB
{kind=link}
603.7 KB
{kind=link}

416.1 KB
{kind=link}

483.5 KB
{kind=link}

247.8 KB
{kind=link}

276.6 KB
{kind=link}

344.4 KB
{kind=link}

189.5 KB
{kind=link}
69.0 KB
{kind=link}

36.6 KB
{kind=link}

90.5 KB
{kind=link}

93.2 KB
{kind=link}

139.4 KB
{kind=link}

88.4 KB
{kind=link}

55.6 KB
{kind=link}

1.2 MB