fix guides index
Showing
文件已移动
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
此差异已折叠。
此差异已折叠。
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
{kind=link}
111.7 KB
{kind=link}
56.7 KB
{kind=link}
245.1 KB
{kind=link}
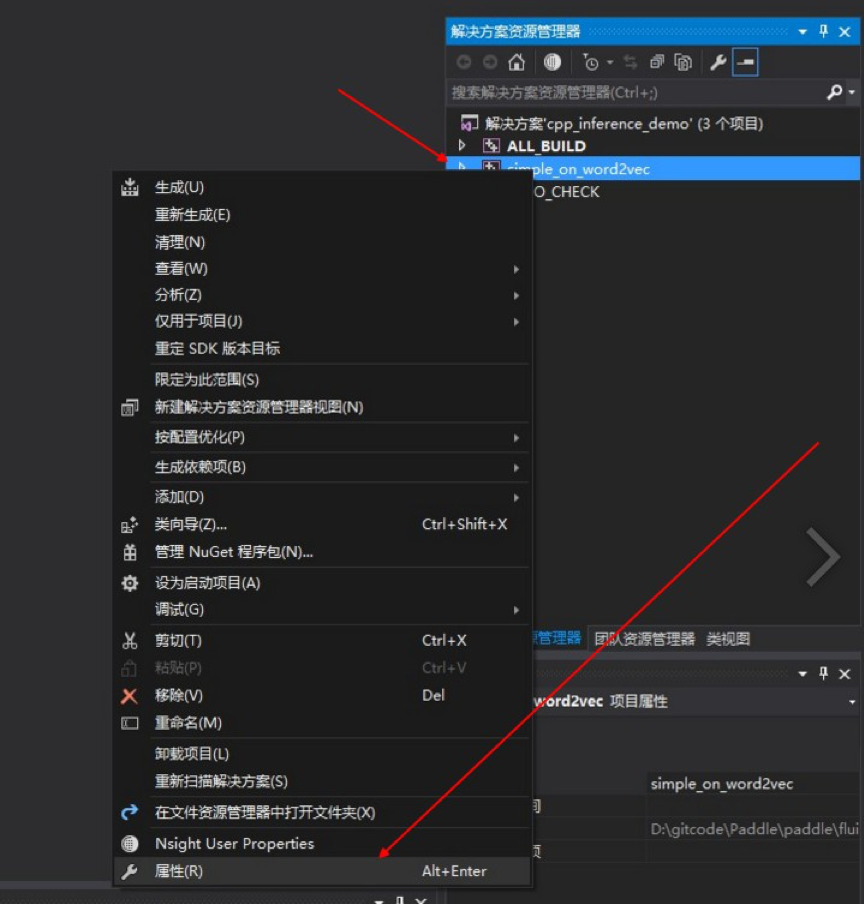
492.8 KB
{kind=link}
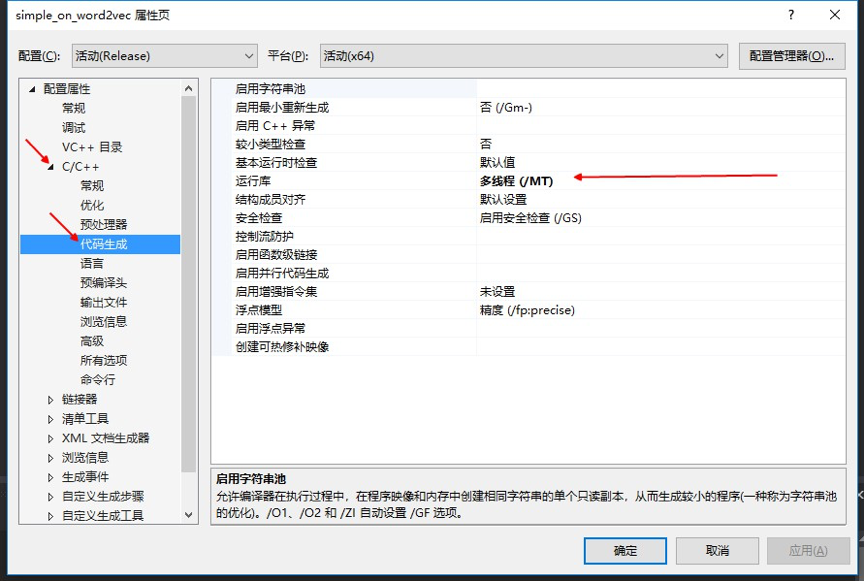
324.8 KB
{kind=link}
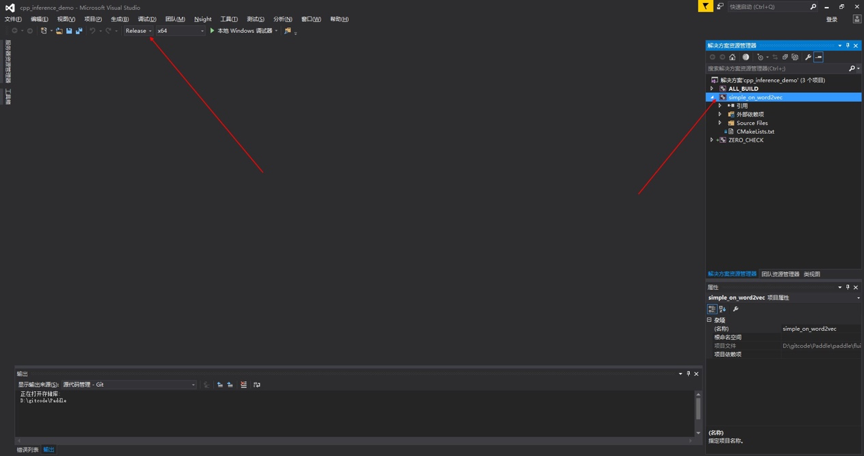
121.6 KB
{kind=link}
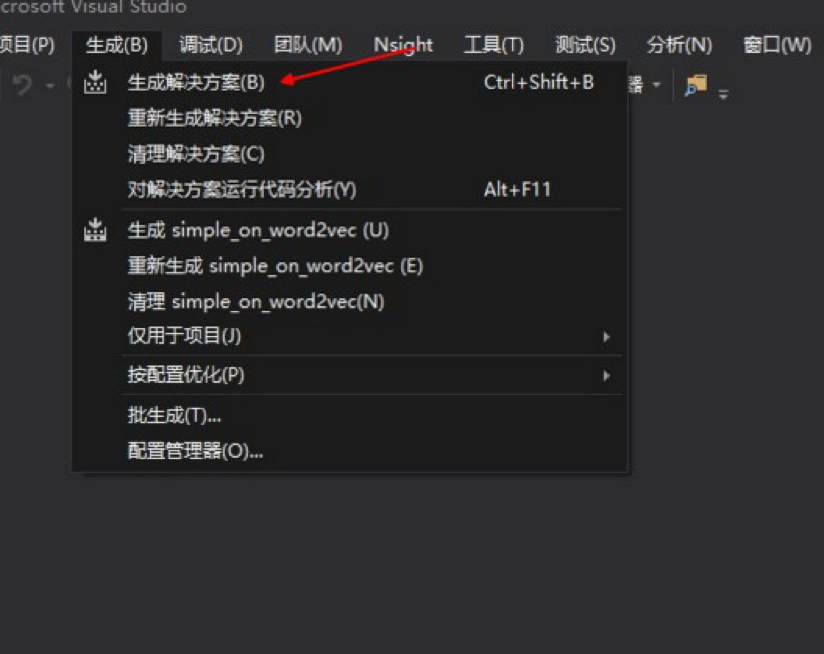
278.1 KB
{kind=link}

86.5 KB
{kind=link}
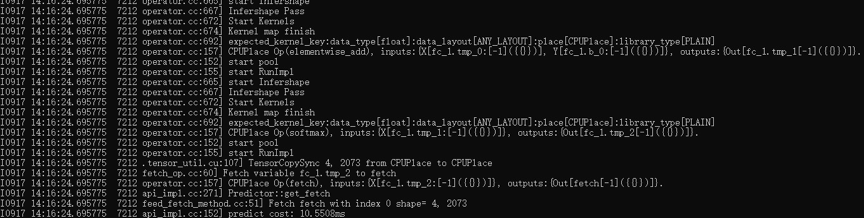
126.1 KB
{kind=link}

87.8 KB
{kind=link}

46.2 KB
{kind=link}

238.6 KB
{kind=link}

318.8 KB
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
{kind=link}

78.4 KB
{kind=link}
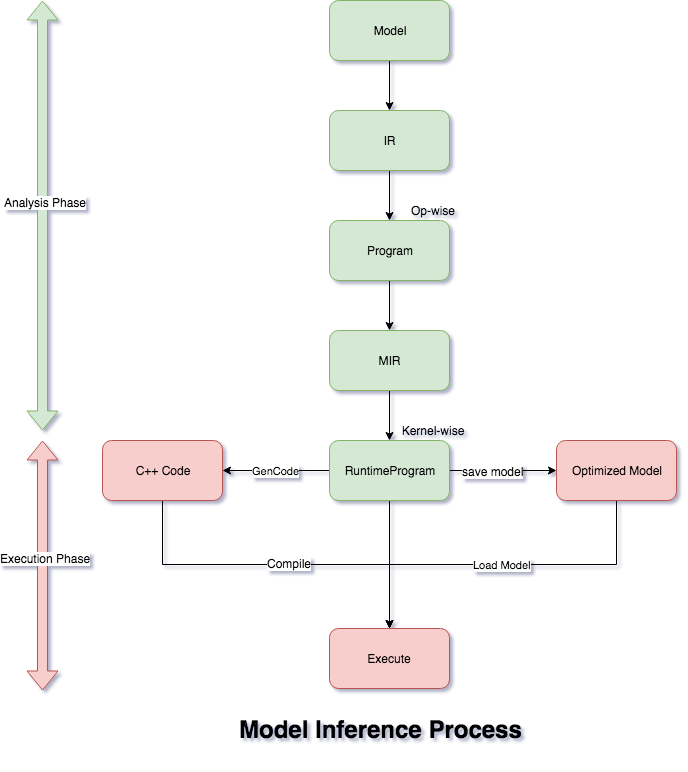
68.6 KB
{kind=link}

39.4 KB
{kind=link}
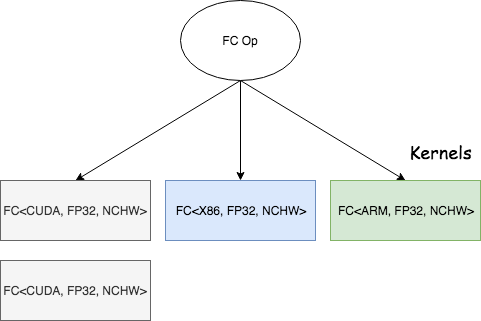
24.7 KB
{kind=link}

44.3 KB
{kind=link}

45.3 KB
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
{kind=link}

98.2 KB
{kind=link}

109.7 KB
{kind=link}

70.9 KB
{kind=link}

320.5 KB
{kind=link}

42.5 KB
{kind=link}

75.6 KB
{kind=link}

39.1 KB
{kind=link}

13.9 KB
{kind=link}

24.7 KB
{kind=link}

45.3 KB
{kind=link}

22.6 KB
{kind=link}

23.7 KB
{kind=link}

163.6 KB
{kind=link}

138.9 KB
{kind=link}

33.9 KB
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。