Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
PaddlePaddle
FluidDoc
提交
f320e491
F
FluidDoc
项目概览
PaddlePaddle
/
FluidDoc
通知
10
Star
2
Fork
0
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
23
列表
看板
标记
里程碑
合并请求
111
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
F
FluidDoc
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
23
Issue
23
列表
看板
标记
里程碑
合并请求
111
合并请求
111
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
提交
f320e491
编写于
6月 27, 2018
作者:
T
typhoonzero
浏览文件
操作
浏览文件
下载
差异文件
Merge branch 'add_dist_howto' of
https://github.com/typhoonzero/FluidDoc
into add_dist_howto
上级
0dc7c256
0621c2ab
变更
6
隐藏空白更改
内联
并排
Showing
6 changed file
with
44 addition
and
5 deletion
+44
-5
source/user_guides/howto/training/dist_train_howto.md
source/user_guides/howto/training/dist_train_howto.md
+44
-5
source/user_guides/howto/training/src/dist_train_nccl2.graffle
...e/user_guides/howto/training/src/dist_train_nccl2.graffle
+0
-0
source/user_guides/howto/training/src/dist_train_nccl2.png
source/user_guides/howto/training/src/dist_train_nccl2.png
+0
-0
source/user_guides/howto/training/src/dist_train_pserver.graffle
...user_guides/howto/training/src/dist_train_pserver.graffle
+0
-0
source/user_guides/howto/training/src/dist_train_pserver.png
source/user_guides/howto/training/src/dist_train_pserver.png
+0
-0
source/user_guides/howto/training/src/parallelism.png
source/user_guides/howto/training/src/parallelism.png
+0
-0
未找到文件。
source/user_guides/howto/training/dist_train_howto.md
浏览文件 @
f320e491
...
...
@@ -4,7 +4,7 @@
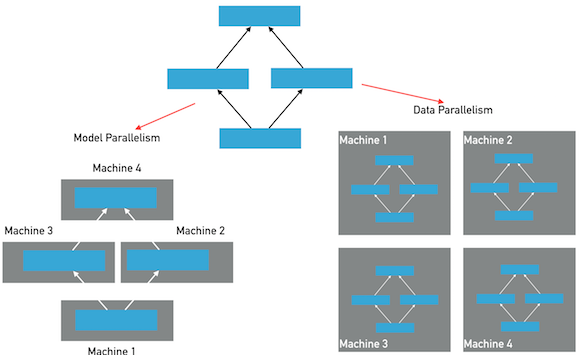
分布式深度学习训练通常分为两种并行化方法:数据并行,模型并行,参考下图:
<img
src=
"parallelism.png"
>
<img
src=
"
src/
parallelism.png"
>
在模型并行方式下,模型的层和参数将被分布在多个节点上,模型在一个mini-batch的前向和反向训练中,将经过多次跨
节点之间的通信。每个节点只保存整个模型的一部分;在数据并行方式下,每个节点保存有完整的模型的层和参数,每个节点
...
...
@@ -15,8 +15,8 @@
通信。其中RPC通信方式使用
[
gRPC
](
https://github.com/grpc/grpc/
)
,Collective通信方式使用
[
NCCL2
](
https://developer.nvidia.com/nccl
)
。下面是一个RPC通信和Collective通信的横向对比:
| Feature | Collective | RPC |
| ------------- |:-------------:| -----:|
| Feature | Collective | RPC
|
| ------------- |:-------------:|
:
-----:|
| Ring-Based Comm | Yes | No |
| Async Training | Reduce ranks | Fast, Direct async updates |
| Dist-Sparse-Table | No | Yes |
...
...
@@ -24,14 +24,53 @@
| Performance | Faster | Fast |
*
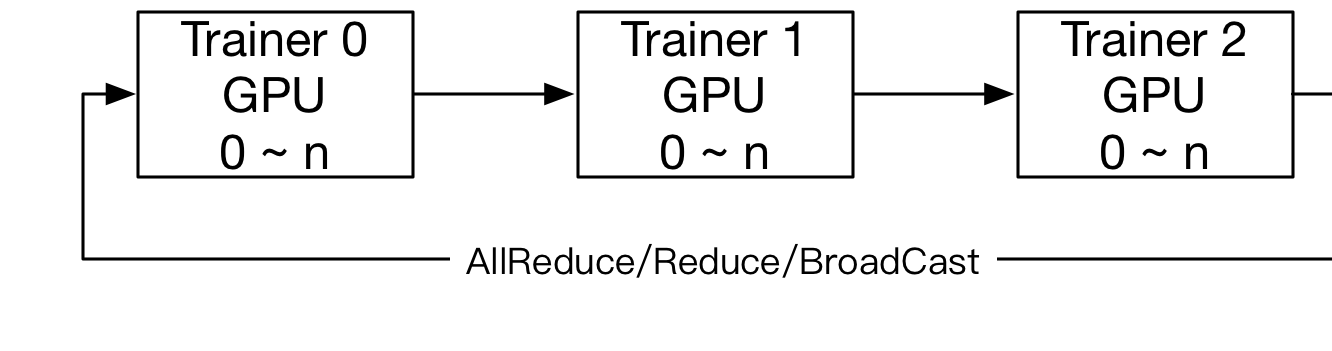
RPC通信方式的结构:
<img
src=
""
>
<img
src=
"
src/dist_train_pserver.png"
width=
"500
"
>
*
NCCL2通信方式的结构:
<img
src=
""
>
<img
src=
"
src/dist_train_nccl2.png"
width=
"500
"
>
## 使用parameter server方式的训练
使用"trainer" API,程序可以自动的通过识别环境变量决定是否已分布式方式执行,需要在您的分布式环境中配置的环境变量包括:
| Env Variable | Comment |
| ------------ | ------- |
| PADDLE_TRAINING_ROLE | role of current node, must be PSERVER or TRAINER |
| PADDLE_PSERVER_PORT | the port that the parameter servers will bind to |
| PADDLE_PSERVER_IPS | a comma separated list of parameter server ips or hostname |
| PADDLE_TRAINERS | number of trainers that in this distributed job |
| PADDLE_CURRENT_IP | current node ip address |
| PADDLE_TRAINER_ID | zero based ID for each trainer |
使用更加底层的"transpiler" API可以提供自定义的分布式训练的方法,比如可以在同一台机器上,启动多个pserver和trainer
进行训练,使用底层API的方法可以参考下面的样例代码:
```
python
role
=
"PSERVER"
trainer_id
=
0
pserver_endpoints
=
"127.0.0.1:6170,127.0.0.1:6171"
current_endpoint
=
"127.0.0.1:6170"
trainers
=
4
t
=
fluid
.
DistributeTranspiler
()
t
.
transpile
(
trainer_id
,
pservers
=
pserver_endpoints
,
trainers
=
trainers
)
if
role
==
"PSERVER"
:
pserver_prog
=
t
.
get_pserver_program
(
current_endpoint
)
pserver_startup
=
t
.
get_startup_program
(
current_endpoint
,
pserver_prog
)
exe
.
run
(
pserver_startup
)
exe
.
run
(
pserver_prog
)
elif
role
==
"TRAINER"
:
train_loop
(
t
.
get_trainer_program
())
```
## 使用NCCL2通信方式的训练
注NCCL2模式目前仅支持"trainer" API,NCCL2方式并没有很多可选项,也没有"transpiler",所以并没有底层API。
使用NCCL2方式同样需要配置每个节点的环境变量,此处与parameter server模式有所不同:
| Env Variable | Comment |
| ------------ | ------- |
| PADDLE_TRAINER_IPS | comma separated IP list of all trainer nodes |
| PADDLE_TRAINER_ID | zero based ID for each trainer, aka. "rank" |
| PADDLE_PSERVER_PORT | a port that will used at initial stage to broadcast the NCCL ID |
| PADDLE_CURRENT_IP | current IP address of current node |
source/user_guides/howto/training/src/dist_train_nccl2.graffle
0 → 100644
浏览文件 @
f320e491
文件已添加
source/user_guides/howto/training/src/dist_train_nccl2.png
0 → 100644
浏览文件 @
f320e491
30.1 KB
source/user_guides/howto/training/src/dist_train_pserver.graffle
0 → 100644
浏览文件 @
f320e491
文件已添加
source/user_guides/howto/training/src/dist_train_pserver.png
0 → 100644
浏览文件 @
f320e491
48.9 KB
source/user_guides/howto/training/src/parallelism.png
0 → 100644
浏览文件 @
f320e491
59.9 KB
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}
{kind=link}

{kind=link}