As the amount of training data increases, training deeper neural network models becomes more and more popular. Current deep-learning training usually keeps the hidden layer outputs in memory during the forward propagation,
and the number of outputs increases linearly with
the increase of the number of model layers,
which becomes a challenge of the memory size
for common devices.
Theory
---------
As we know, a training process of a deep-learning network contains 3 steps:
- **Forward Propagation**:Running forward operators and generate temporary variables as output
- **Backward Propagation**:Running backward operators to compute gradients of parameters
- **Optimization**:Applying optimization algorithm to update parameters
When the model becomes deeper, the number of temporary variables
generated in the forward propagation process can reach tens
of thousands, occupying a large amount of memory.
The `Garbage Collection mechanism <https://paddlepaddle.org.cn/documentation/docs/zh/advanced_usage/best_practice/memory_optimize.html>`_
in Paddle can delete useless variables for the sake of saving memory.
However, some variables serve as inputs of backward operators,
they must be kept in memory until particular operator finish.
Take a simple example, define a network contains two `mul` operators,
the forward propagation works as follows:
.. math::
y = W_1 * x
z = W_2 * y
where :math:`x, y, z` are vectors, :math:`W_1, W_2` are matrix。It is easy to conduct that the gradient of :math:`W_2` is:
.. math::
W_{2}^{'} = z^{'} / y
We can see that :math:`y` is used in the backward propagation process,
thus it must be kept in the memory during the whole forward propagation.
When network grows deeper, more 'y's need to be stored,
adding more requirements to the memory.
Forward Recomputation Backpropagation(FRB) splits a deep network to k segments.
For each segment, in forward propagation,
most of the temporary variables are erased in time,
except for some special variables (we will talk about that later);
in backward propagation, the forward operators will be recomputed
to get these temporary variables before running backward operators.
In short, FBR runs forward operators twice.
But how to split the network? A deep learning network usually consists
of connecting modules in series:
ResNet-50 contains 16 blocks and Bert-Large contains 24 transformers.
It is a good choice to treat such modules as segments.
The variables among segments are
called as checkpoints.
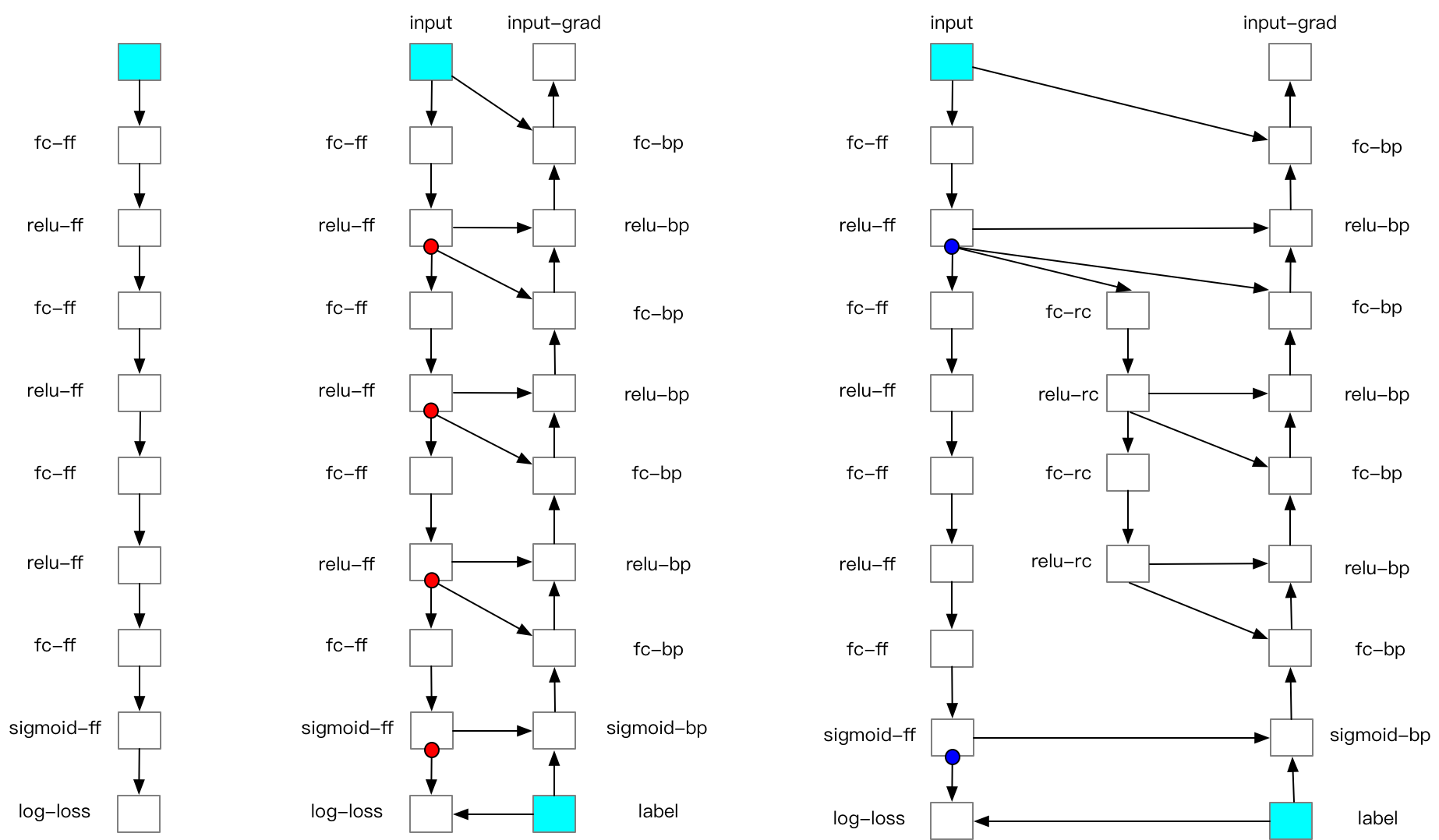
The following picture is a network with 4 fc layers, 3 relu layers,
1 sigmoid layer and 1 log-loss layer in series.
The left column is the forward propagation,
the middle column is the normal backward propagation,
and the right column is the FRB.
Rectangular boxes represent the operators, red dots represent
the intermediate variables in forward computation, blue dots
represent checkpoints and arrows represent the dependencies between operators.
.. image:: image/recompute.png
Note: the complete source code of this example: `source <https://github.com/PaddlePaddle/examples/blob/master/community_examples/recompute/demo.py>`_
After applying FBR, the forward computation only needs to store
2 variables (the blue dots) instead of 4 variables (the red
dots), saving the corresponding memories. It is notable that
recomputing operators generate new intermediate variables at the same time,
a trade-off needs to be considered in this situation.
While according to our experiments,
FBR usually saves rather than increase the memory load.
Usage
---------
We have implemented the FRB algorithm named "RecomputeOptimizer"
based on Paddle. More information about this algorithm can
be learned by the `source code <https://github.com/PaddlePaddle/Paddle/blob/develop/python/paddle/fluid/optimizer.py>`_
We supply some examples of using recompute in Fleet API for users.
We also post corresponding training speed,
test results and memory usages of these examples for reference.
- Fine-tuning Bert Large model with recomputing: `source <https://github.com/PaddlePaddle/Fleet/tree/develop/examples/recompute/bert>`_
- Training object detection models with recomputing:developing.
Q&A
-------
- **Does RecomputeOptimizer support operators with random outputs?**
We currently found that the dropout operator has random results
and RecomputeOptimizer is able to keep the outputs of
first-computation and recomputation consistent.
- **Are there more official examples of Recompute?**
More examples will be updated at `examples <https://github.com/PaddlePaddle/examples/tree/master/community_examples/recompute>`_
and `Fleet <https://github.com/PaddlePaddle/Fleet>`_ . Feel free to
raise issues if you get any problem with these examples.
- **How should I set checkpoints?**
The position of checkpoints is important:
we suggest setting the variable between the sub-model as checkpoints,
that is, set a variable as a checkpoint if it
can separate the network into two parts without short-cut connections.
The number of checkpoints is also important:
too few checkpoints will reduce the memory saved by recomputing while
too many checkpoints will occupy a lot of memory themselves.
We will add a tool to estimate the memory usage with specific checkpoints,
helping users to choose checkpointing variables.
[1] Tianqi Chen, Bing Xu, Chiyuan Zhang, and Carlos Guestrin . Training deep nets with sublinear memory cost.
arXiv preprint, arXiv:1604.06174, 2016.
[2] Audrunas Gruslys , Rémi Munos , Ivo Danihelka , Marc Lanctot , and Alex Graves. Memory efficient
backpropagation through time. In Advances in Neural Information Processing Systems (NIPS), pages 4125 4133,
2016.
[3] Kusumoto, Mitsuru, et al. "A Graph Theoretic Framework of Recomputation Algorithms for Memory-Efficient Backpropagation." arXiv preprint arXiv:1905.11722 (2019).
[1] Tianqi Chen, Bing Xu, Chiyuan Zhang, and Carlos Guestrin . Training deep nets with sublinear memory cost.
arXiv preprint, arXiv:1604.06174, 2016.
[2] Audrunas Gruslys , Rémi Munos , Ivo Danihelka , Marc Lanctot , and Alex Graves. Memory efficient
backpropagation through time. In Advances in Neural Information Processing Systems (NIPS), pages 4125 4133,
2016.
[3] Kusumoto, Mitsuru, et al. "A Graph Theoretic Framework of Recomputation Algorithms for Memory-Efficient Backpropagation." arXiv preprint arXiv:1905.11722 (2019).
{kind=link}