Fix images in beginners_guides
Showing
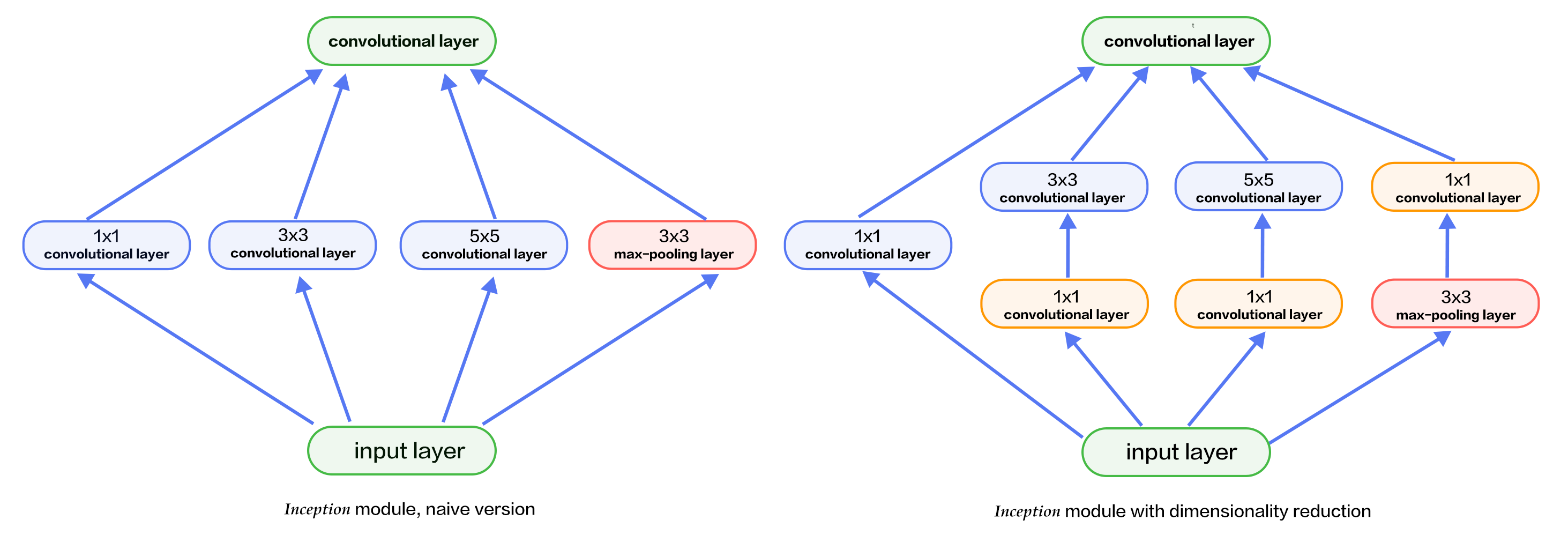
226.4 KB
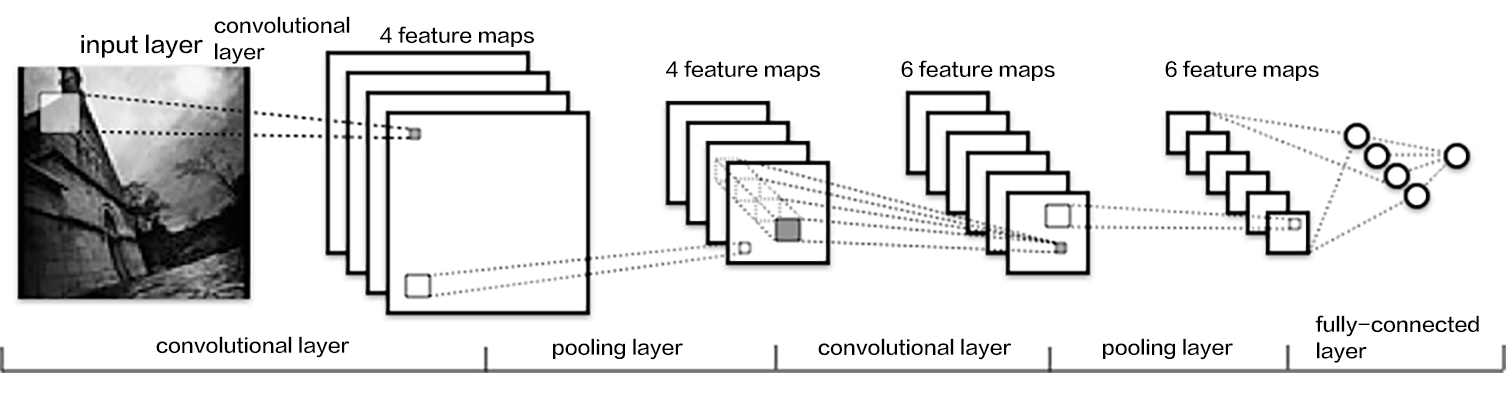
135.9 KB
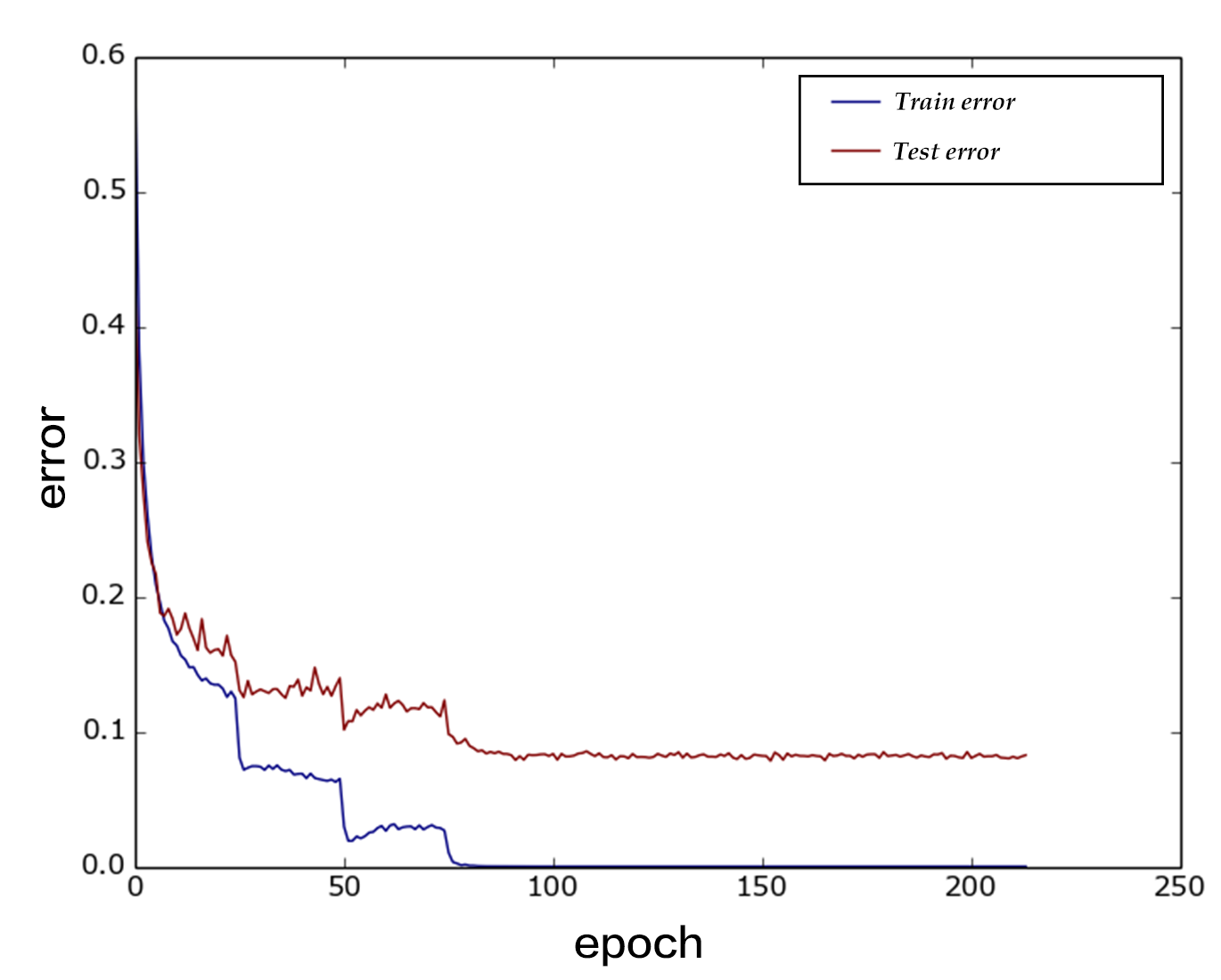
95.9 KB

2.3 MB
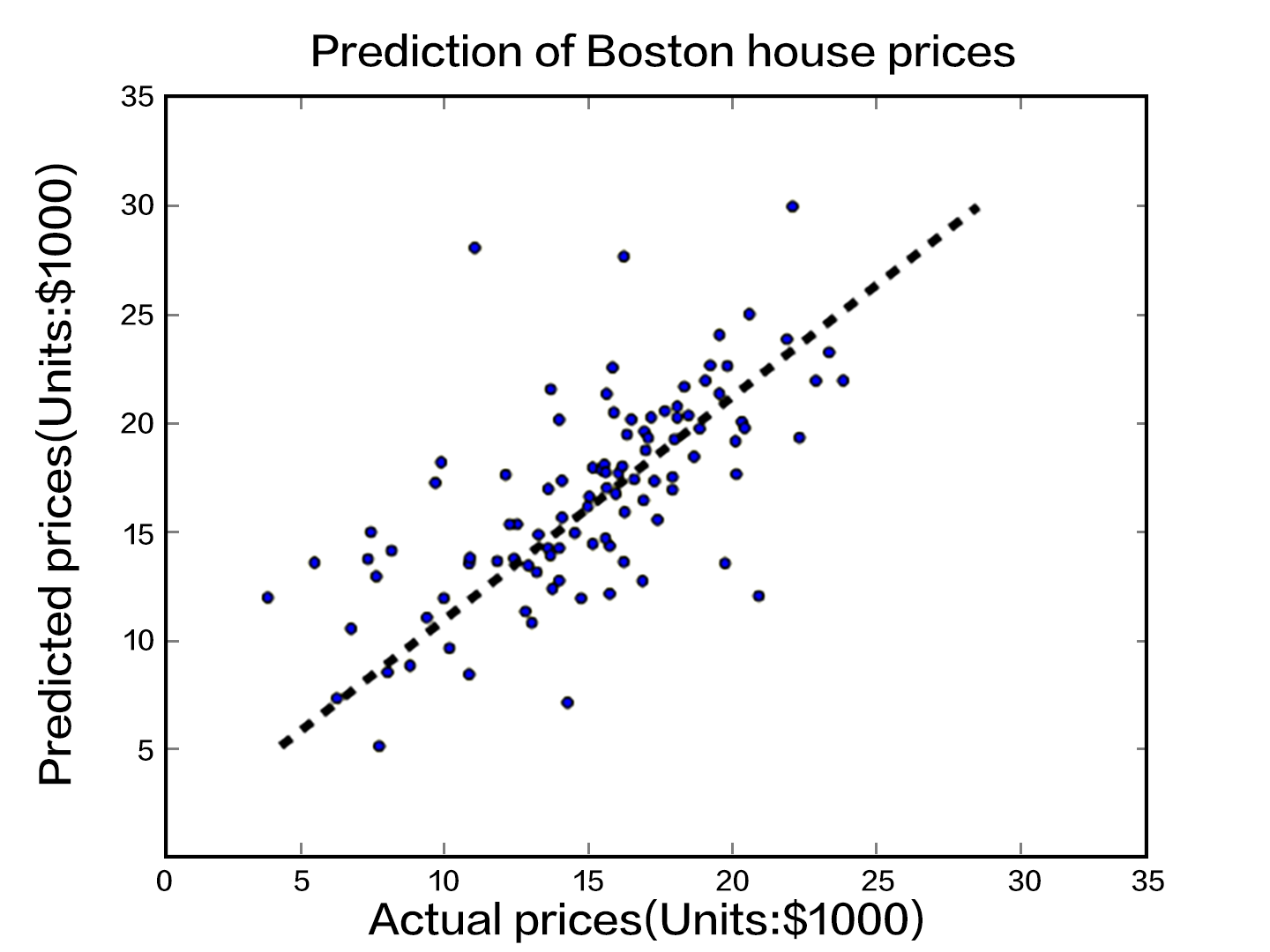
136.8 KB
29.6 KB
51.0 KB
82.6 KB
19.5 KB
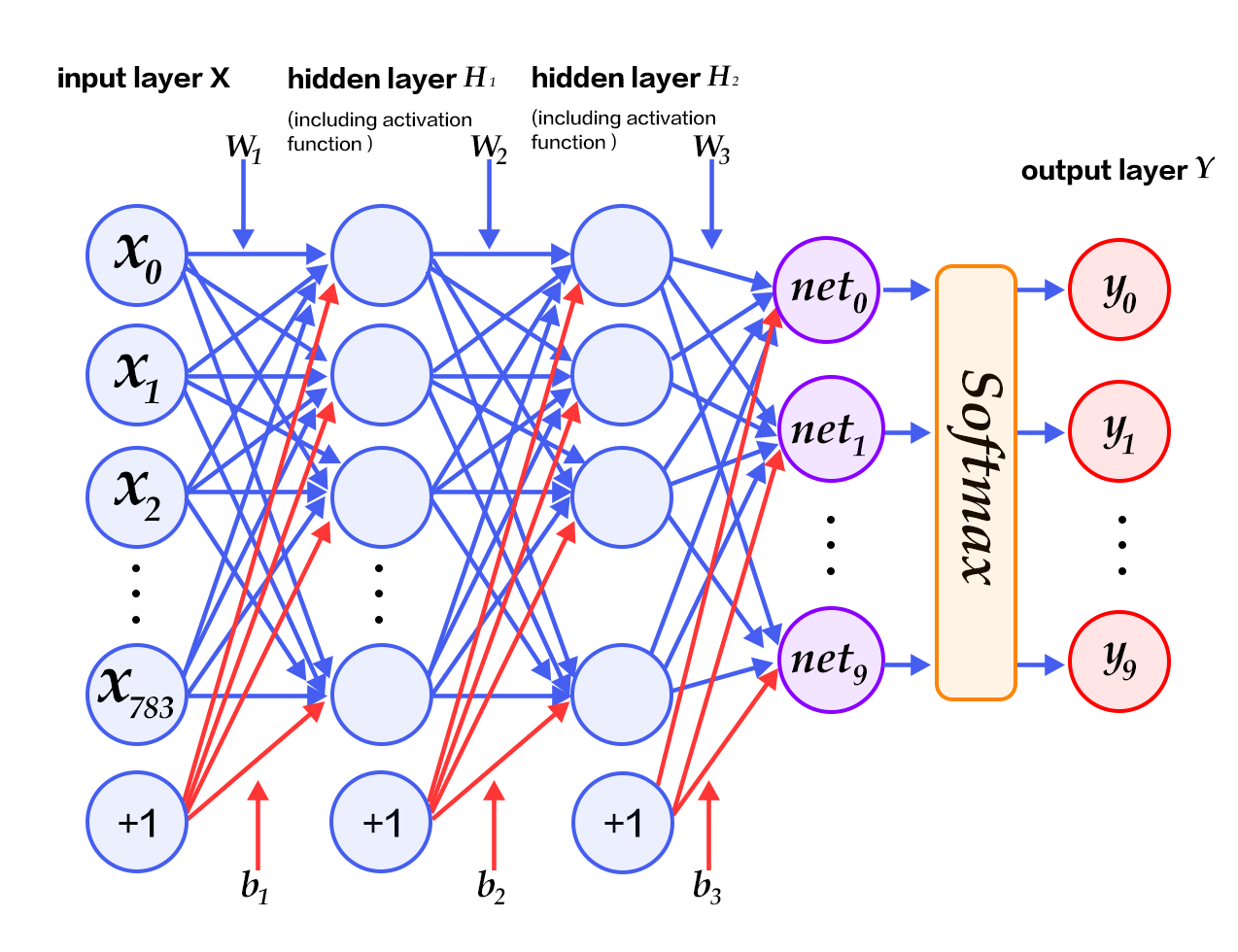
190.2 KB
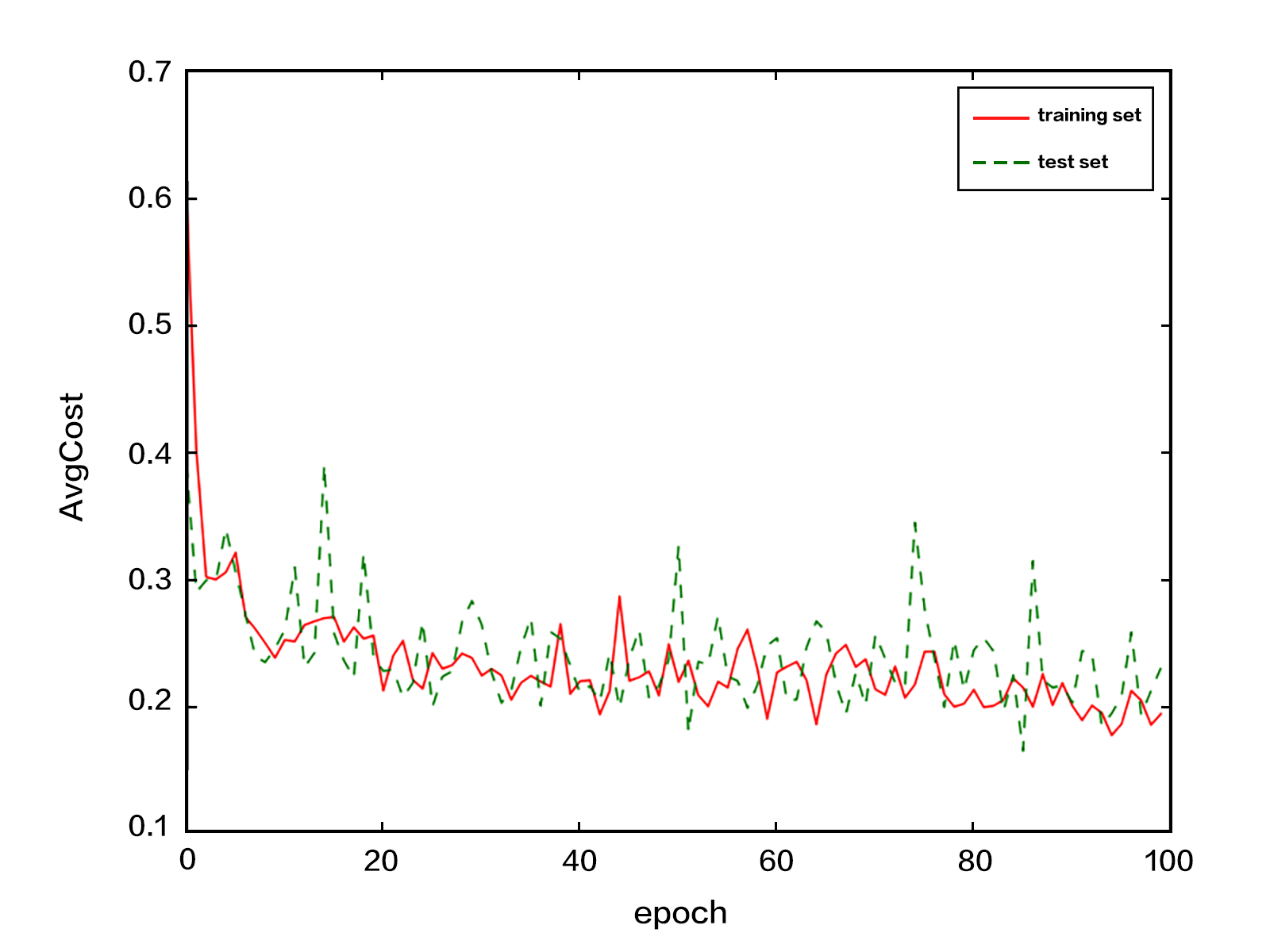
142.2 KB
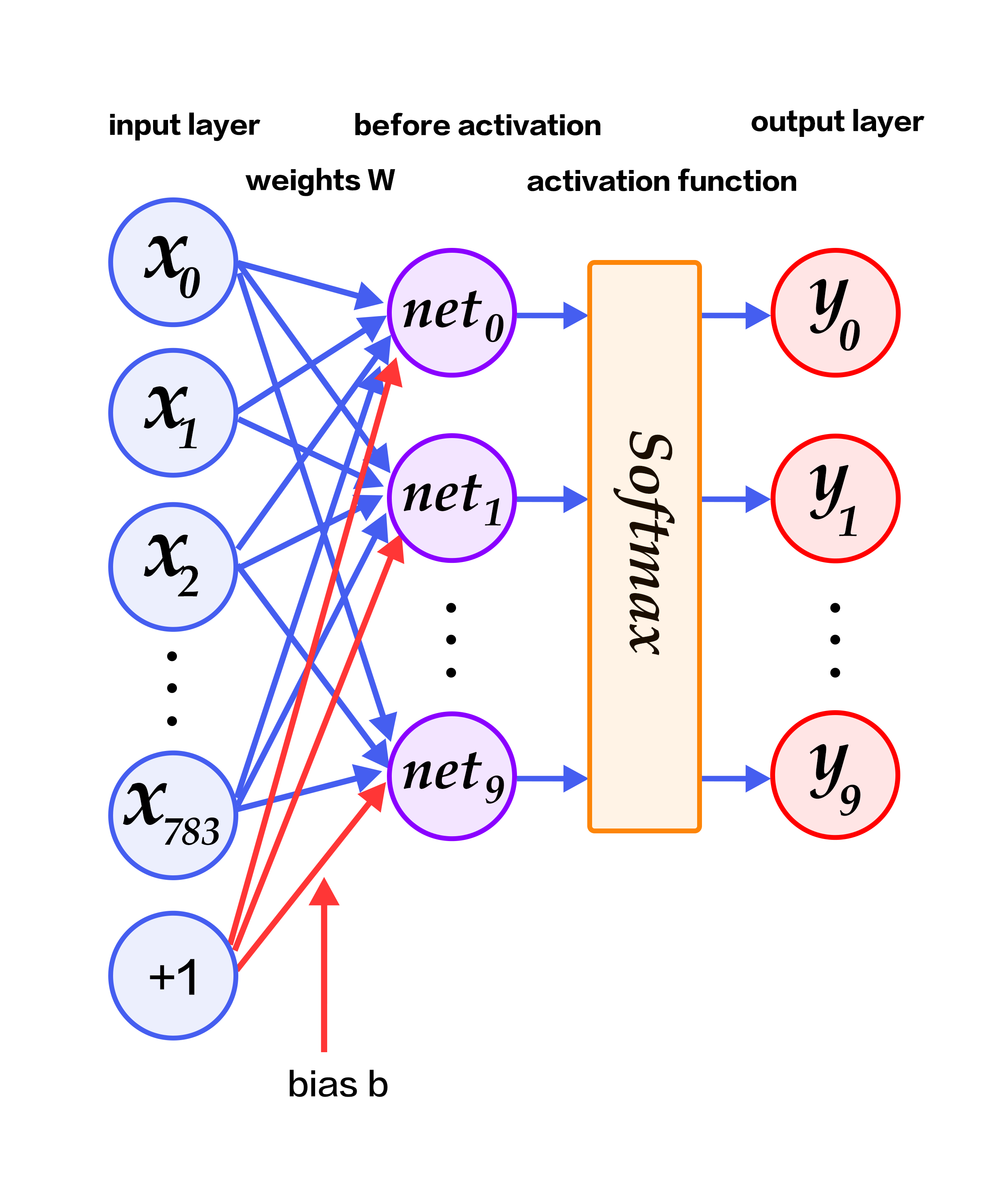
424.5 KB
226.4 KB
135.9 KB
95.9 KB
2.3 MB
136.8 KB
29.6 KB
51.0 KB
82.6 KB
19.5 KB
190.2 KB
142.2 KB
424.5 KB
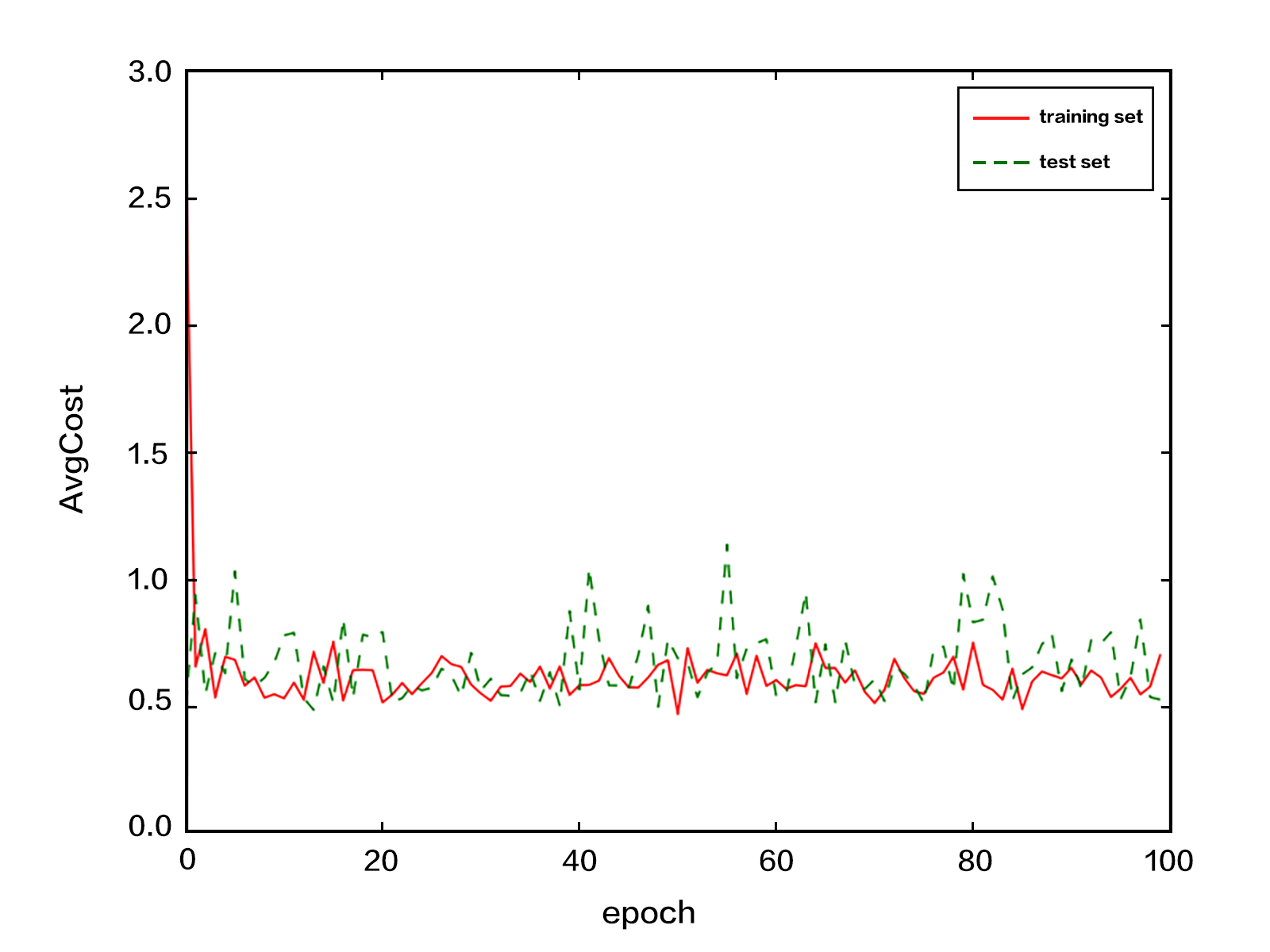
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}