Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
PaddlePaddle
FluidDoc
提交
6ad374ae
F
FluidDoc
项目概览
PaddlePaddle
/
FluidDoc
通知
10
Star
2
Fork
0
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
23
列表
看板
标记
里程碑
合并请求
111
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
F
FluidDoc
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
23
Issue
23
列表
看板
标记
里程碑
合并请求
111
合并请求
111
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
提交
6ad374ae
编写于
9月 19, 2018
作者:
T
typhoonzero
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
add doc
上级
0ce08a41
变更
7
隐藏空白更改
内联
并排
Showing
7 changed file
with
323 addition
and
0 deletion
+323
-0
doc/fluid/user_guides/howto/training/multi_node.rst
doc/fluid/user_guides/howto/training/multi_node.rst
+1
-0
doc/fluid/user_guides/howto/training/src/create_gpu_machine.png
...uid/user_guides/howto/training/src/create_gpu_machine.png
+0
-0
doc/fluid/user_guides/howto/training/src/create_image.png
doc/fluid/user_guides/howto/training/src/create_image.png
+0
-0
doc/fluid/user_guides/howto/training/src/create_more_nodes.png
...luid/user_guides/howto/training/src/create_more_nodes.png
+0
-0
doc/fluid/user_guides/howto/training/src/dist_train_demo.py
doc/fluid/user_guides/howto/training/src/dist_train_demo.py
+107
-0
doc/fluid/user_guides/howto/training/src/release.png
doc/fluid/user_guides/howto/training/src/release.png
+0
-0
doc/fluid/user_guides/howto/training/train_on_baidu_cloud_cn.md
...uid/user_guides/howto/training/train_on_baidu_cloud_cn.md
+215
-0
未找到文件。
doc/fluid/user_guides/howto/training/multi_node.rst
浏览文件 @
6ad374ae
...
@@ -7,3 +7,4 @@
...
@@ -7,3 +7,4 @@
cluster_quick_start.rst
cluster_quick_start.rst
cluster_howto.rst
cluster_howto.rst
train_on_baidu_cloud_cn.md
doc/fluid/user_guides/howto/training/src/create_gpu_machine.png
0 → 100644
浏览文件 @
6ad374ae
182.4 KB
doc/fluid/user_guides/howto/training/src/create_image.png
0 → 100644
浏览文件 @
6ad374ae
164.0 KB
doc/fluid/user_guides/howto/training/src/create_more_nodes.png
0 → 100644
浏览文件 @
6ad374ae
146.2 KB
doc/fluid/user_guides/howto/training/src/dist_train_demo.py
0 → 100644
浏览文件 @
6ad374ae
# Copyright (c) 2018 PaddlePaddle Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
from
__future__
import
print_function
import
paddle.fluid.core
as
core
import
math
import
os
import
sys
import
numpy
import
paddle
import
paddle.fluid
as
fluid
BATCH_SIZE
=
64
PASS_NUM
=
1
def
loss_net
(
hidden
,
label
):
prediction
=
fluid
.
layers
.
fc
(
input
=
hidden
,
size
=
10
,
act
=
'softmax'
)
loss
=
fluid
.
layers
.
cross_entropy
(
input
=
prediction
,
label
=
label
)
avg_loss
=
fluid
.
layers
.
mean
(
loss
)
acc
=
fluid
.
layers
.
accuracy
(
input
=
prediction
,
label
=
label
)
return
prediction
,
avg_loss
,
acc
def
conv_net
(
img
,
label
):
conv_pool_1
=
fluid
.
nets
.
simple_img_conv_pool
(
input
=
img
,
filter_size
=
5
,
num_filters
=
20
,
pool_size
=
2
,
pool_stride
=
2
,
act
=
"relu"
)
conv_pool_1
=
fluid
.
layers
.
batch_norm
(
conv_pool_1
)
conv_pool_2
=
fluid
.
nets
.
simple_img_conv_pool
(
input
=
conv_pool_1
,
filter_size
=
5
,
num_filters
=
50
,
pool_size
=
2
,
pool_stride
=
2
,
act
=
"relu"
)
return
loss_net
(
conv_pool_2
,
label
)
def
train
(
use_cuda
,
role
,
endpoints
,
current_endpoint
,
trainer_id
,
trainers
):
if
use_cuda
and
not
fluid
.
core
.
is_compiled_with_cuda
():
return
img
=
fluid
.
layers
.
data
(
name
=
'img'
,
shape
=
[
1
,
28
,
28
],
dtype
=
'float32'
)
label
=
fluid
.
layers
.
data
(
name
=
'label'
,
shape
=
[
1
],
dtype
=
'int64'
)
prediction
,
avg_loss
,
acc
=
conv_net
(
img
,
label
)
test_program
=
fluid
.
default_main_program
().
clone
(
for_test
=
True
)
optimizer
=
fluid
.
optimizer
.
Adam
(
learning_rate
=
0.001
)
optimizer
.
minimize
(
avg_loss
)
t
=
fluid
.
DistributeTranspiler
()
t
.
transpile
(
trainer_id
,
pservers
=
endpoints
,
trainers
=
trainers
)
if
role
==
"pserver"
:
prog
=
t
.
get_pserver_program
(
current_endpoint
)
startup
=
t
.
get_startup_program
(
current_endpoint
,
pserver_program
=
prog
)
exe
=
fluid
.
Executor
(
fluid
.
CPUPlace
())
exe
.
run
(
startup
)
exe
.
run
(
prog
)
elif
role
==
"trainer"
:
prog
=
t
.
get_trainer_program
()
place
=
fluid
.
CUDAPlace
(
0
)
if
use_cuda
else
fluid
.
CPUPlace
()
exe
=
fluid
.
Executor
(
place
)
train_reader
=
paddle
.
batch
(
paddle
.
reader
.
shuffle
(
paddle
.
dataset
.
mnist
.
train
(),
buf_size
=
500
),
batch_size
=
BATCH_SIZE
)
test_reader
=
paddle
.
batch
(
paddle
.
dataset
.
mnist
.
test
(),
batch_size
=
BATCH_SIZE
)
feeder
=
fluid
.
DataFeeder
(
feed_list
=
[
img
,
label
],
place
=
place
)
exe
.
run
(
fluid
.
default_startup_program
())
for
pass_id
in
range
(
PASS_NUM
):
for
batch_id
,
data
in
enumerate
(
train_reader
()):
acc_np
,
avg_loss_np
=
exe
.
run
(
prog
,
feed
=
feeder
.
feed
(
data
),
fetch_list
=
[
acc
,
avg_loss
])
if
(
batch_id
+
1
)
%
10
==
0
:
print
(
'PassID {0:1}, BatchID {1:04}, Loss {2:2.2}, Acc {3:2.2}'
.
format
(
pass_id
,
batch_id
+
1
,
float
(
avg_loss_np
.
mean
()),
float
(
acc_np
.
mean
())))
if
__name__
==
'__main__'
:
if
len
(
sys
.
argv
)
!=
6
:
print
(
"Usage: python %s role endpoints current_endpoint trainer_id trainers"
%
sys
.
argv
[
0
])
exit
(
0
)
role
,
endpoints
,
current_endpoint
,
trainer_id
,
trainers
=
\
sys
.
argv
[
1
:]
train
(
True
,
role
,
endpoints
,
current_endpoint
,
int
(
trainer_id
),
int
(
trainers
))
doc/fluid/user_guides/howto/training/src/release.png
0 → 100644
浏览文件 @
6ad374ae
209.0 KB
doc/fluid/user_guides/howto/training/train_on_baidu_cloud_cn.md
0 → 100644
浏览文件 @
6ad374ae
# 在百度云上启动Fluid分布式训练
PaddlePaddle Fluid分布式训练,可以不依赖集群系统(比如MPI,Kubernetes)也可以启动分布式训练。
本章节将会以
[
百度云
](
https://cloud.baidu.com/
)
为实例,说明如何在云端环境,甚至云端GPU环境启动
大规模分布式任务。
### 创建集群模板
登录到百度云控制台,选择BCC服务,点击“创建实例”。选择地域,注意,只有一些地域有GPU服务器可选,选择合适
的地域之后,并选择对应型号然后创建一个空的服务器,如下图:
<img
src=
"src/create_gpu_machine.png"
width=
"500"
>
*
在操作系统选项中,可以根据需要选择对应的版本,注意根据实际情况选择CUDA版本,这里我们选择CUDA-9.2。
*
示例中选择机器付费方式为后付费,表示随着机器的释放,收费也会对应停止,对运行一次性任务会比较划算。
在机器创建成功之后,执行下面的命令安装paddlepaddle GPU版本和相关依赖。
```
bash
apt-get update
&&
apt-get
install
-y
python python-pip python-opencv
# 注:百度云cuda-9.2镜像默认没有安装cudnn和nccl2,需要手动安装,如果自行安装,需要从官网下载
wget
-q
"http://paddle-train-on-cloud.cdn.bcebos.com/libcudnn7_7.2.1.38-1+cuda9.2_amd64.deb"
wget
-q
"http://paddle-train-on-cloud.cdn.bcebos.com/nccl_2.2.13-1+cuda9.0_x86_64.txz"
dpkg
-i
libcudnn7_7.2.1.38-1+cuda9.2_amd64.deb
ln
-s
/usr/lib/x86_64-linux-gnu/libcudnn.so.7 /usr/lib/libcudnn.so
unxz nccl_2.2.13-1+cuda9.0_x86_64.txz
tar
xf nccl_2.2.13-1+cuda9.0_x86_64.tar
cp
-r
nccl_2.2.13-1+cuda9.0_x86_64/lib/
*
/usr/lib
# 注:可以选择是否使用下面的pip镜像加速下载
pip
install
-i
https://pypi.tuna.tsinghua.edu.cn/simple
matplotlib
==
2.2.3
pip
install
-i
https://pypi.tuna.tsinghua.edu.cn/simple paddlepaddle-gpu
==
0.15.0.post97
```
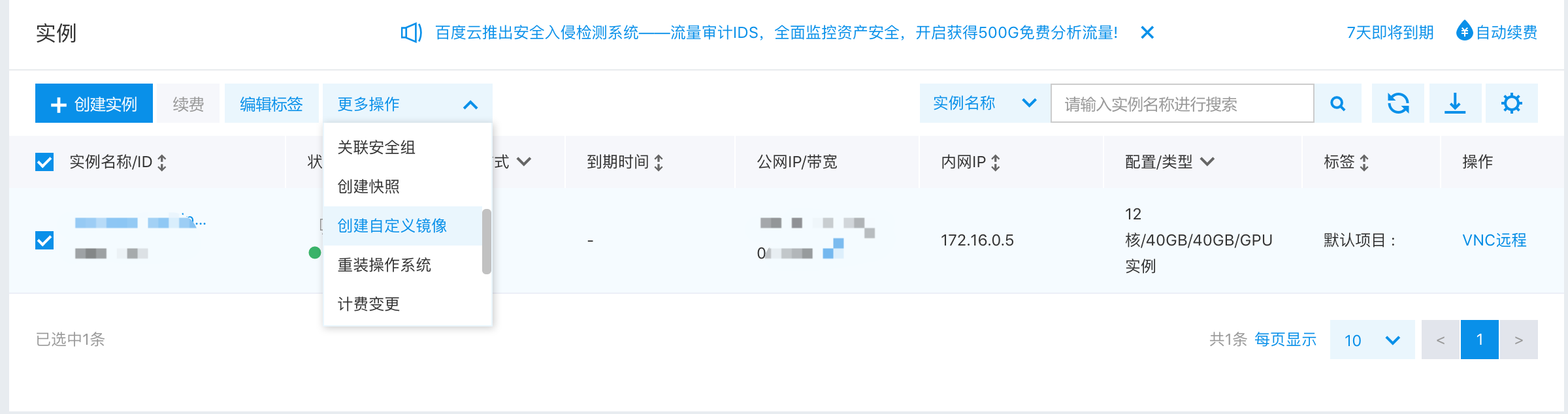
完成安装后,使用下面的测试程序,测试当前机器是否可以正确运行GPU训练程序,如果遇到报错,请根据报错提示修复
运行环境问题。为了方便启动GPU集群,测试程序执行成功之后,选择当前服务器,然后选择“创建自定义镜像”,后续
创建GPU集群时即可选择配置好的镜像。
<img
src=
"src/create_image.png"
width=
"500"
>
*
测试程序:
```
python
from
__future__
import
print_function
import
paddle.fluid.core
as
core
import
math
import
os
import
sys
import
numpy
import
paddle
import
paddle.fluid
as
fluid
BATCH_SIZE
=
64
PASS_NUM
=
1
def
loss_net
(
hidden
,
label
):
prediction
=
fluid
.
layers
.
fc
(
input
=
hidden
,
size
=
10
,
act
=
'softmax'
)
loss
=
fluid
.
layers
.
cross_entropy
(
input
=
prediction
,
label
=
label
)
avg_loss
=
fluid
.
layers
.
mean
(
loss
)
acc
=
fluid
.
layers
.
accuracy
(
input
=
prediction
,
label
=
label
)
return
prediction
,
avg_loss
,
acc
def
conv_net
(
img
,
label
):
conv_pool_1
=
fluid
.
nets
.
simple_img_conv_pool
(
input
=
img
,
filter_size
=
5
,
num_filters
=
20
,
pool_size
=
2
,
pool_stride
=
2
,
act
=
"relu"
)
conv_pool_1
=
fluid
.
layers
.
batch_norm
(
conv_pool_1
)
conv_pool_2
=
fluid
.
nets
.
simple_img_conv_pool
(
input
=
conv_pool_1
,
filter_size
=
5
,
num_filters
=
50
,
pool_size
=
2
,
pool_stride
=
2
,
act
=
"relu"
)
return
loss_net
(
conv_pool_2
,
label
)
def
train
(
use_cuda
):
if
use_cuda
and
not
fluid
.
core
.
is_compiled_with_cuda
():
return
img
=
fluid
.
layers
.
data
(
name
=
'img'
,
shape
=
[
1
,
28
,
28
],
dtype
=
'float32'
)
label
=
fluid
.
layers
.
data
(
name
=
'label'
,
shape
=
[
1
],
dtype
=
'int64'
)
prediction
,
avg_loss
,
acc
=
conv_net
(
img
,
label
)
test_program
=
fluid
.
default_main_program
().
clone
(
for_test
=
True
)
optimizer
=
fluid
.
optimizer
.
Adam
(
learning_rate
=
0.001
)
optimizer
.
minimize
(
avg_loss
)
place
=
fluid
.
CUDAPlace
(
0
)
if
use_cuda
else
fluid
.
CPUPlace
()
exe
=
fluid
.
Executor
(
place
)
train_reader
=
paddle
.
batch
(
paddle
.
reader
.
shuffle
(
paddle
.
dataset
.
mnist
.
train
(),
buf_size
=
500
),
batch_size
=
BATCH_SIZE
)
test_reader
=
paddle
.
batch
(
paddle
.
dataset
.
mnist
.
test
(),
batch_size
=
BATCH_SIZE
)
feeder
=
fluid
.
DataFeeder
(
feed_list
=
[
img
,
label
],
place
=
place
)
exe
.
run
(
fluid
.
default_startup_program
())
for
pass_id
in
range
(
PASS_NUM
):
for
batch_id
,
data
in
enumerate
(
train_reader
()):
acc_np
,
avg_loss_np
=
exe
.
run
(
fluid
.
default_main_program
(),
feed
=
feeder
.
feed
(
data
),
fetch_list
=
[
acc
,
avg_loss
])
if
(
batch_id
+
1
)
%
10
==
0
:
print
(
'PassID {0:1}, BatchID {1:04}, Loss {2:2.2}, Acc {3:2.2}'
.
format
(
pass_id
,
batch_id
+
1
,
float
(
avg_loss_np
.
mean
()),
float
(
acc_np
.
mean
())))
if
__name__
==
'__main__'
:
train
(
True
)
```
### 创建集群
完成创建镜像之后,可以使用这个配置好的镜像创建一个GPU集群,根据您的实际需求创建足够数量的GPU服务器,
作为示例,这里启动2台GPU服务器,包括上一步创建的服务器,所以这里再启动一台新的服务器。
点击“创建实例”,在相同地域选择同样配置的GPU服务器,注意选择刚才创建的镜像作为操作系统。
<img
src=
"src/create_more_nodes.png"
width=
"500"
>
### 编写集群任务启动脚本
为了方便在更多的GPU服务器上启动分布式训练任务,我们将使用
[
fabric
](
http://www.fabfile.org/
)
作为集群任务启动管理工具,您可以选择其他熟悉的集群框架,比如MPI, Kubernetes,本示例演示的方法
仅针对简单集群环境,而且服务器之间可以互相ssh登录。
安装fabric,需要执行:
```
bash
pip
install
fabric
```
假设我们创建了2台GPU服务器,ip分别是
`172.16.0.5,172.16.0.6`
,然后在第一台服务器上,
先创建训练程序文件
`dist_train_demo.py`
,从
[
这里
](
./src/dist_train_demo.py
)
下载代码。
然后编写
`fabfile.py`
脚本,用于控制在不同服务器上启动训练任务的parameter server和trainer:
```
python
from
fabric
import
Group
,
task
endpoints
=
"172.16.0.5:6173,172.16.0.6:6173"
port
=
"6173"
pservers
=
2
trainers
=
2
hosts
=
[]
eps
=
[]
for
ep
in
endpoints
.
split
(
","
):
eps
.
append
(
ep
)
hosts
.
append
(
ep
.
split
(
":"
)[
0
])
def
start_server
(
c
):
current_endpoint
=
"%s:%s"
%
(
c
.
host
,
port
)
trainer_id
=
hosts
.
index
(
c
.
host
)
cmd
=
"python /root/work/dist_train_demo.py pserver %s %s %d %d &> /root/work/server.log.%s &"
%
(
endpoints
,
current_endpoint
,
trainer_id
,
trainers
,
c
.
host
)
c
.
run
(
cmd
)
def
start_trainer
(
c
):
current_endpoint
=
"%s:%s"
%
(
c
.
host
,
port
)
trainer_id
=
hosts
.
index
(
c
.
host
)
cmd
=
"python /root/work/dist_train_demo.py trainer %s %s %d %d &> /root/work/trainer.log.%s &"
%
(
endpoints
,
current_endpoint
,
trainer_id
,
trainers
,
c
.
host
)
c
.
run
(
cmd
)
@
task
def
start
(
c
):
c
.
connect_kwargs
.
password
=
"work@paddle123"
c
.
run
(
"mkdir -p /root/work"
)
c
.
put
(
"dist_train_demo.py"
,
"/root/work"
)
start_server
(
c
)
start_trainer
(
c
)
@
task
def
tail_log
(
c
):
c
.
connect_kwargs
.
password
=
"work@paddle123"
c
.
run
(
"tail /root/work/trainer.log.%s"
%
c
.
host
)
```
保存上述代码到
`fabfile.py`
之后,执行
```
bash
fab
-H
172.16.0.5,172.16.0.6 start
```
就可以开始一个分布式训练任务。这个任务会在两台GPU服务器分别启动2个pserver进程和2个trainer进程开始训练。
### 获取分布式训练结果
示例任务会在
`/root/work`
下记录日志,分别为
`pserver.log.[IP]`
和
`trainer.log.[IP]`
的形式,可以手动在
服务器上查看这些日志文件观察结果,也可以使用fabric获取所有节点的日志信息,比如:
```
bash
fab
-H
172.16.0.5,172.16.0.6 tail-log
```
### 关闭集群
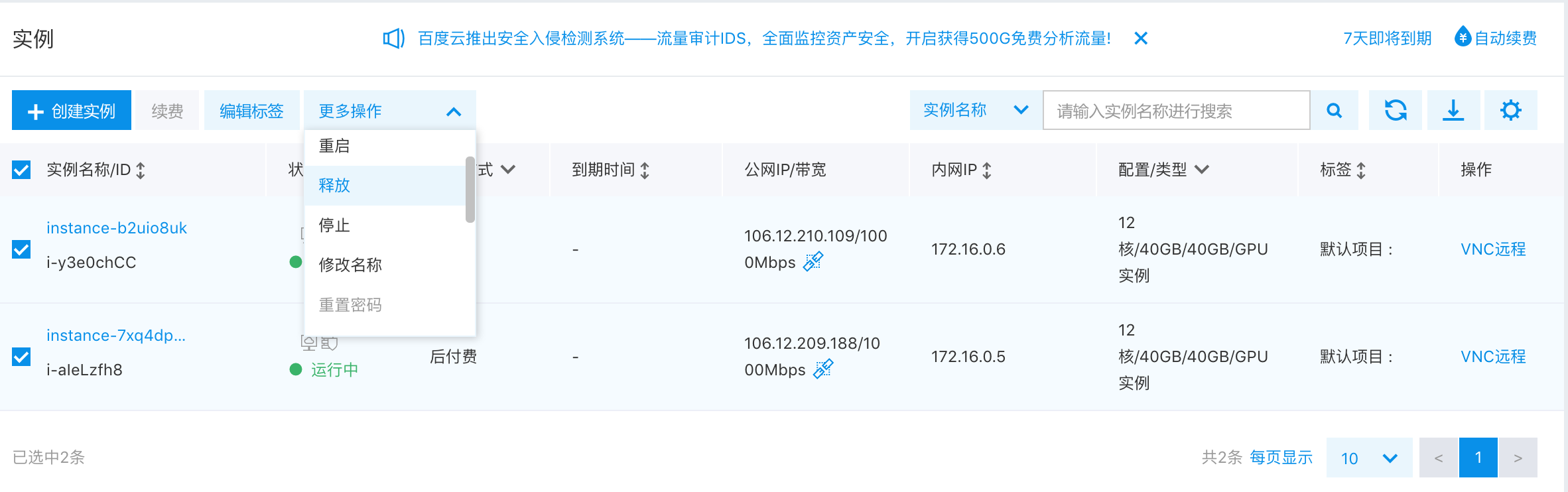
任务执行完成后,不要忘记释放掉GPU集群资源,勾选选择需要释放的服务器,选择“释放”,则会关闭机器并释放资源。
如果需要执行新的任务,可以直接使用之前保存的镜像,启动新的集群,并参照前面的步骤开始训练。
<img
src=
"src/release.png"
width=
"500"
>
\ No newline at end of file
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}

{kind=link}
{kind=link}

{kind=link}