Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
PaddlePaddle
FluidDoc
提交
27e29b54
F
FluidDoc
项目概览
PaddlePaddle
/
FluidDoc
通知
10
Star
2
Fork
0
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
23
列表
看板
标记
里程碑
合并请求
111
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
F
FluidDoc
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
23
Issue
23
列表
看板
标记
里程碑
合并请求
111
合并请求
111
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
提交
27e29b54
编写于
11月 19, 2018
作者:
D
dengkaipeng
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
shrink image and adjust doc
上级
2d93e595
变更
2
隐藏空白更改
内联
并排
Showing
2 changed file
with
2 addition
and
2 deletion
+2
-2
doc/fluid/api/api_guides/low_level/layers/learning_rate_scheduler.rst
...i/api_guides/low_level/layers/learning_rate_scheduler.rst
+2
-2
doc/fluid/images/learning_rate_scheduler.png
doc/fluid/images/learning_rate_scheduler.png
+0
-0
未找到文件。
doc/fluid/api/api_guides/low_level/layers/learning_rate_scheduler.rst
浏览文件 @
27e29b54
...
...
@@ -4,10 +4,10 @@
学习率调度器
############
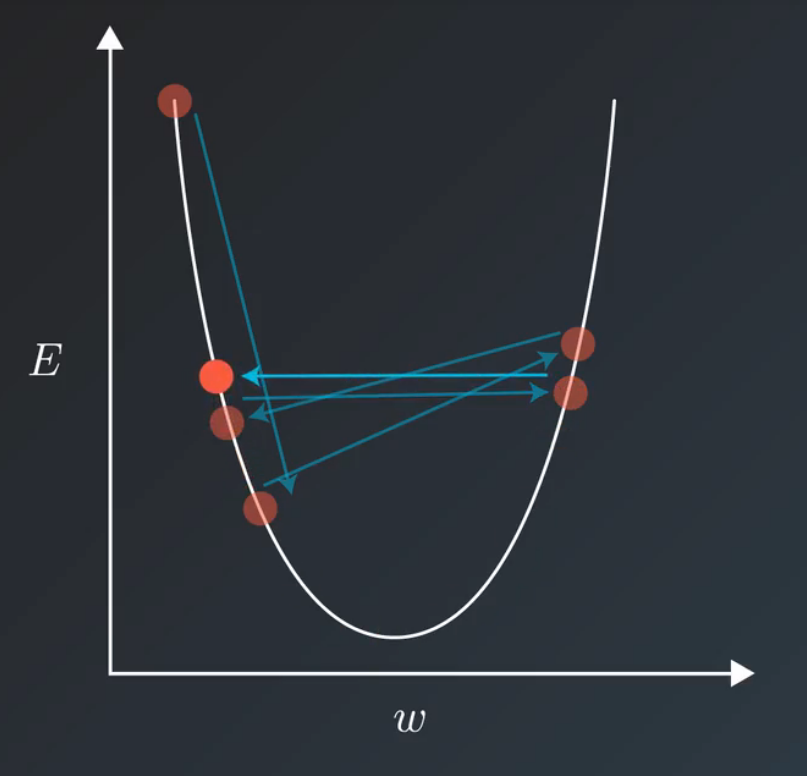
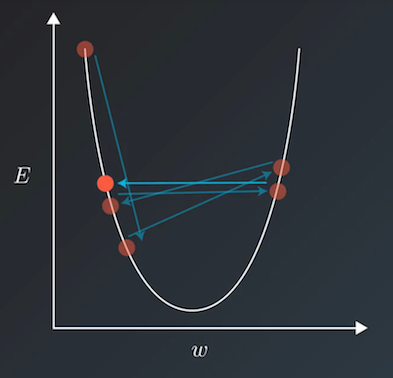
当我们使用诸如梯度下降法等方式来训练模型时,一般会兼顾训练速度和损失(loss)
选择相对合适的学习率,但若在训练过程中一直使用一个学习率的话,训练集的损失下降到一定程度后就会不在继续下降了,而是在一定范围内震荡。其震荡原理如下图所示,即当损失函数收敛到局部极小值附近时,会由于学习率过大而导致更新步幅过大而
越过极小值而出现震荡。
当我们使用诸如梯度下降法等方式来训练模型时,一般会兼顾训练速度和损失(loss)
来选择相对合适的学习率。但若在训练过程中一直使用一个学习率的话,训练集的损失下降到一定程度后就会不在继续下降了,而是在一定范围内震荡。其震荡原理如下图所示,即当损失函数收敛到局部极小值附近时,会由于学习率过大导致更新步幅过大,每步参数更新会反复
越过极小值而出现震荡。
.. image:: ../../../../images/learning_rate_scheduler.png
:scale:
5
0 %
:scale:
8
0 %
:align: center
...
...
doc/fluid/images/learning_rate_scheduler.png
查看替换文件 @
2d93e595
浏览文件 @
27e29b54
141.0 KB
|
W:
|
H:
62.6 KB
|
W:
|
H:
2-up
Swipe
Onion skin
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}
{kind=link}