ernie tiny 的finetune_classifier异常
Created by: leyiwang
下载了ernie tiny的config, 启动finetune_classifier时,参照reademe的说明:
1 线上GPU 容器环境下:
ERNIE tiny 模型采用了subword粒度输入,需要在数据前处理中加入切词(segmentation)并使用sentence piece进行tokenization. segmentation 以及 tokenization 需要使用的模型包含在了 ERNIE tiny 的预训练模型文件中,分别是 ./subword/dict.wordseg.pickle 和 ./subword/spm_cased_simp_sampled.model.
目前./example/下的代码针对 ERNIE tiny 的前处理进行了适配只需在脚本中通过 --sentence_piece_model 引入tokenization 模型,再通过 --word_dict 引入 segmentation 模型之后即可进行 ERNIE tiny 的 Fine-tune。指定了--sentence_piece_model 和--word_dict参数,
# for ernie tiny
python3.6 ernie/finetune_classifier.py \
--data_dir ${TASK_DATA_PATH}/chnsenticorp/ \
--warm_start_from ${MODEL_PATH}/params \
--vocab_file ${MODEL_PATH}/vocab.txt \
--max_seqlen 128 \
--sentence_piece_model ${MODEL_PATH}/subword/spm_cased_simp_sampled.model \
--word_dict ${MODEL_PATH}/subword/dict.wordseg.pickle \
--run_config '{
"model_dir": "output",
"max_steps": '$((10 * 9600 / 32))',
"save_steps": 100,
"log_steps": 10,
"max_ckpt": 1,
"skip_steps": 0,
"eval_steps": 100
}' \
--hparam ${MODEL_PATH}/ernie_config.json \
--hparam '{ # model definition
"sent_type_vocab_size": None, # default term in official config
"use_task_id": False,
"task_id": 0,
}' \
--hparam '{ # learn
"warmup_proportion": 0.1,
"weight_decay": 0.01,
"use_fp16": 0,
"learning_rate": 0.00005,
"num_label": 2,
"batch_size": 32
}'
2 本地mac环境下
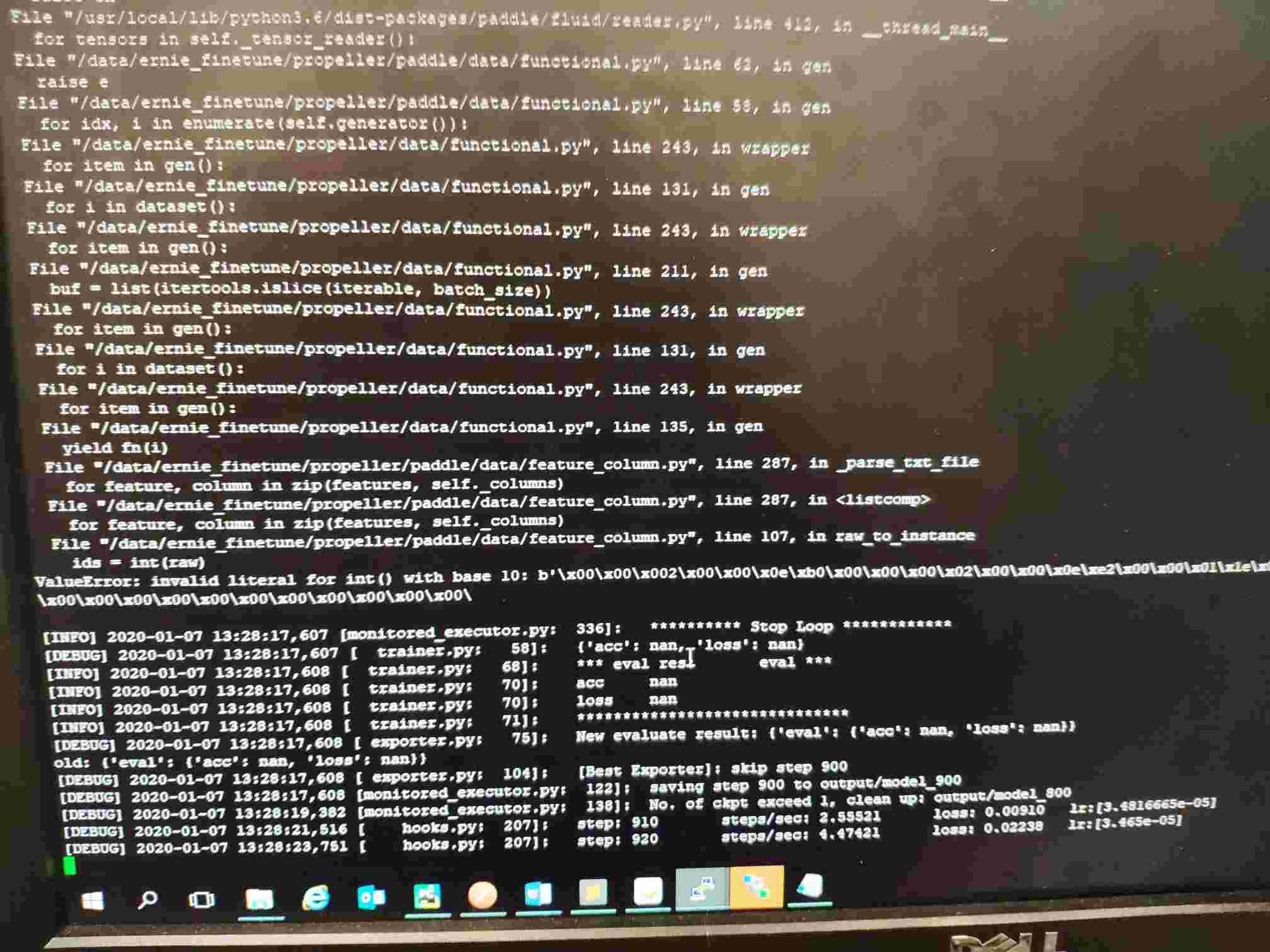
线上gpu环境下的docker容器里的ernie tiny 的finetune是使用github上的ernie代码,根据readme说明下载了相关的数据、模型文件,修改了启动的python命令,跑的,报https://github.com/PaddlePaddle/ERNIE/issues/397的错误。
因为本地没有gpu,直接跑会报错,我根据错误提示将几处cuda_places替换为cpu_places,发现本地用cpu可以跑通,不再报类型转换的错误。 但是线上gpu环境下的代码和本地差的就是这几处cpu_places的替换,数据、模型一致,却报了类型转换错误。
...
[INFO] 2020-01-08 12:42:39,990 [monitored_executor.py: 230]: warm start: encoder_layer_2_post_ffn_layer_norm_bias
[INFO] 2020-01-08 12:42:39,990 [monitored_executor.py: 230]: warm start: pooled_fc.w_0
[INFO] 2020-01-08 12:42:39,990 [monitored_executor.py: 230]: warm start: pooled_fc.b_0
[DEBUG] 2020-01-08 12:42:41,849 [monitored_executor.py: 281]: freezing program
[INFO] 2020-01-08 12:42:41,849 [monitored_executor.py: 269]: replica id 0 of 1
[DEBUG] 2020-01-08 12:42:41,884 [monitored_executor.py: 283]: done freezing
[INFO] 2020-01-08 12:42:41,884 [monitored_executor.py: 284]: ********** Start Loop ************
[DEBUG] 2020-01-08 12:42:41,884 [monitored_executor.py: 289]: train loop has hook <propeller.paddle.train.hooks.StopAtStepHook object at 0x12d108cc0>
[DEBUG] 2020-01-08 12:42:41,885 [monitored_executor.py: 289]: train loop has hook <propeller.paddle.train.hooks.LoggingHook object at 0x12d29c5c0>
[DEBUG] 2020-01-08 12:42:41,885 [monitored_executor.py: 289]: train loop has hook <propeller.paddle.train.trainer.train_and_eval.<locals>.EvalHookOnTrainLoop object at 0x1391a93c8>
[DEBUG] 2020-01-08 12:42:41,885 [monitored_executor.py: 289]: train loop has hook <propeller.paddle.train.hooks.CheckpointSaverHook object at 0x12d2d3080>
I0108 12:42:42.160605 3072451456 parallel_executor.cc:421] The number of CPUPlace, which is used in ParallelExecutor, is 1. And the Program will be copied 1 copies
I0108 12:42:42.206982 3072451456 build_strategy.cc:363] SeqOnlyAllReduceOps:0, num_trainers:1
I0108 12:42:42.243758 3072451456 parallel_executor.cc:285] Inplace strategy is enabled, when build_strategy.enable_inplace = True
I0108 12:42:42.325690 3072451456 parallel_executor.cc:315] Cross op memory reuse strategy is enabled, when build_strategy.memory_optimize = True or garbage collection strategy is disabled, which is not recommended
I0108 12:42:42.351922 3072451456 parallel_executor.cc:368] Garbage collection strategy is enabled, when FLAGS_eager_delete_tensor_gb = 0
[DEBUG] 2020-01-08 12:47:09,765 [ hooks.py: 207]: step: 10 steps/sec: -1.00000 loss: 0.77125 lr:[1.6666667e-06]
[DEBUG] 2020-01-08 12:51:13,554 [ hooks.py: 207]: step: 20 steps/sec: 0.03969 loss: 0.77323 lr:[3.3333333e-06]
[DEBUG] 2020-01-08 12:56:19,886 [ hooks.py: 207]: step: 30 steps/sec: 0.03903 loss: 0.71317 lr:[5.e-06]
[INFO] 2020-01-08 12:59:26,841 [monitored_executor.py: 336]: ********** Stop Loop ************