Dygraph fix3 (#457)
* update readme * update demo * + 160G model * qa model bugfix: models inherits docstrings * Update README.zh.md * Update README.en.md * Update README.zh.md * reorganize binaries * Update README.zh.md * Update README.en.md * Update README.zh.md * Update README.en.md
Showing
{kind=link}
693.0 KB
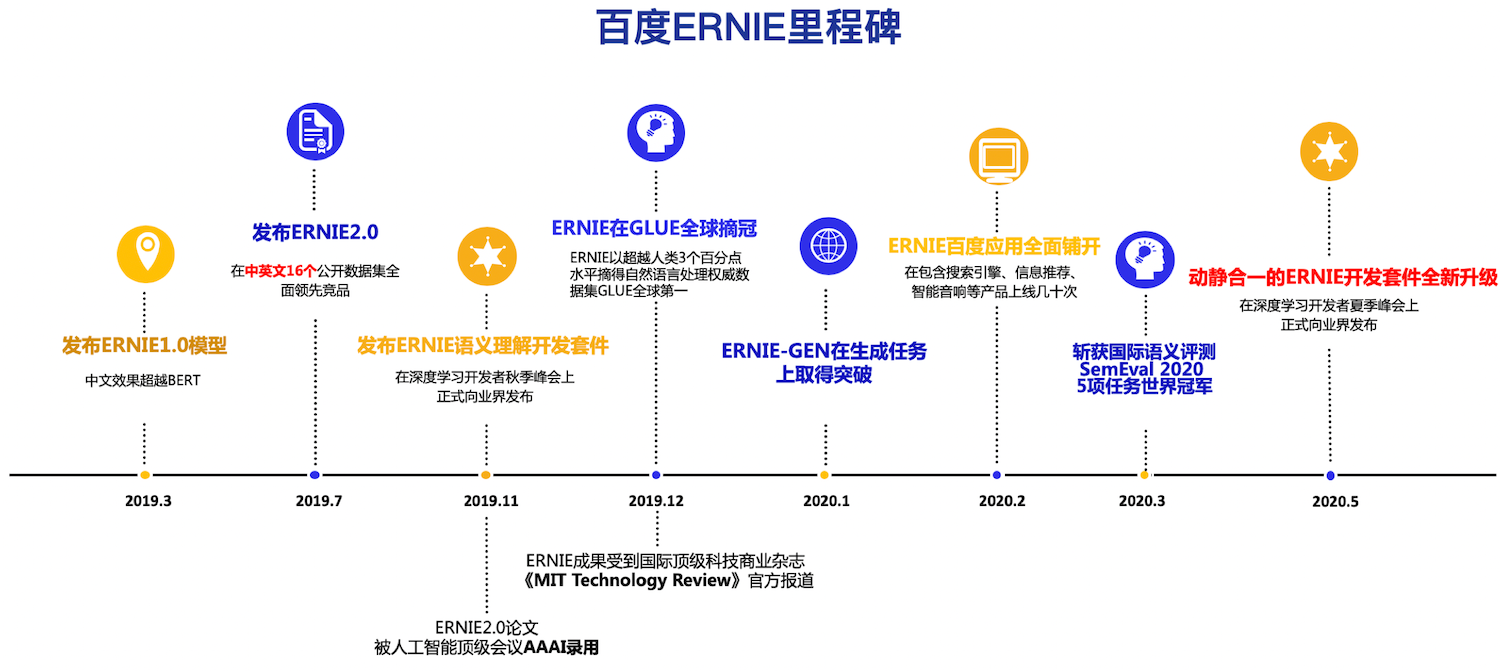
.metas/ERNIE_milestone_en.png
0 → 100644
{kind=link}
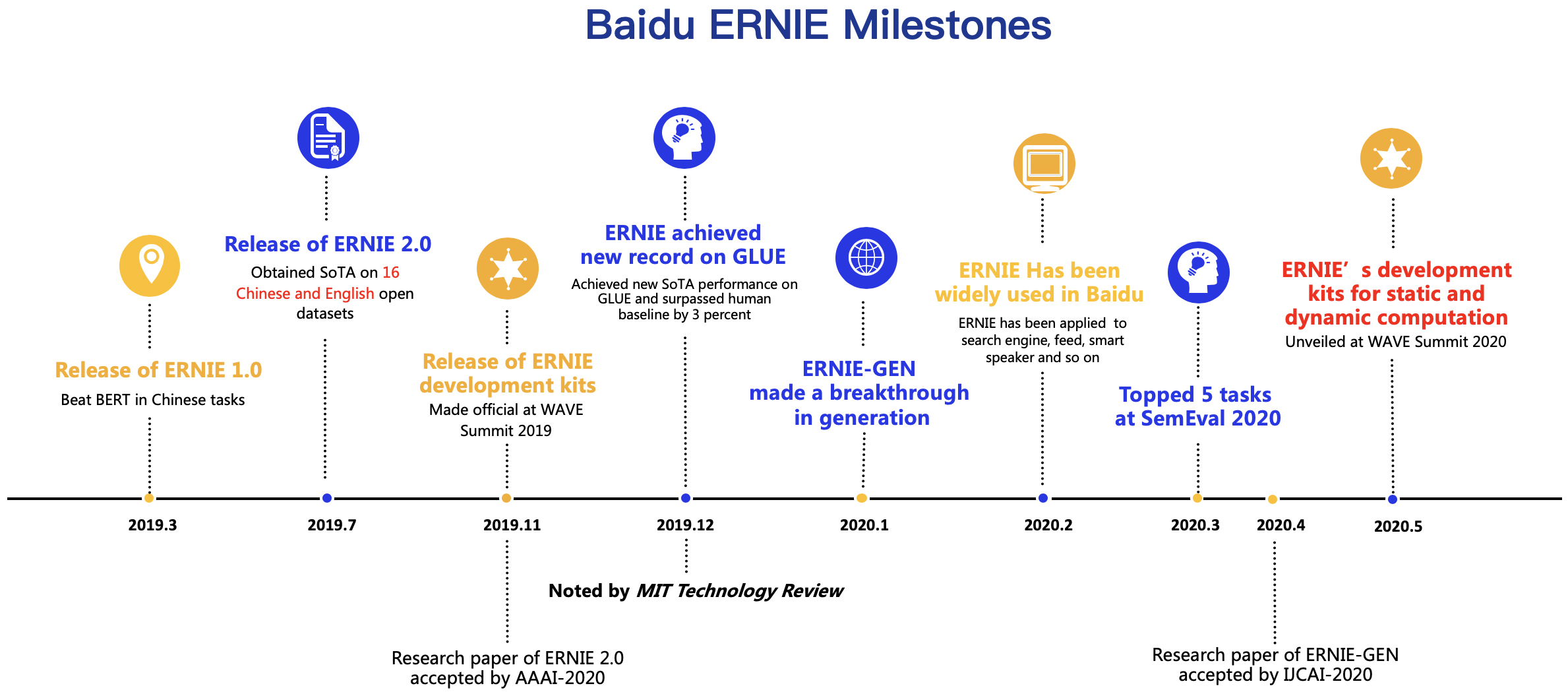
792.4 KB
{kind=link}
.metas/dygraph_show.gif
已删除
100644 → 0
{kind=link}
1.3 MB
.metas/ernie-head-banner.gif
已删除
100644 → 0
{kind=link}

2.6 MB
.metas/ernie.png
已删除
100644 → 0
{kind=link}

332.8 KB