Repro (#661)
* add ernie-unimo * add ernie-unimo
Showing
ernie-unimo/README.md
0 → 100644
ernie-unimo/env.sh
0 → 100644
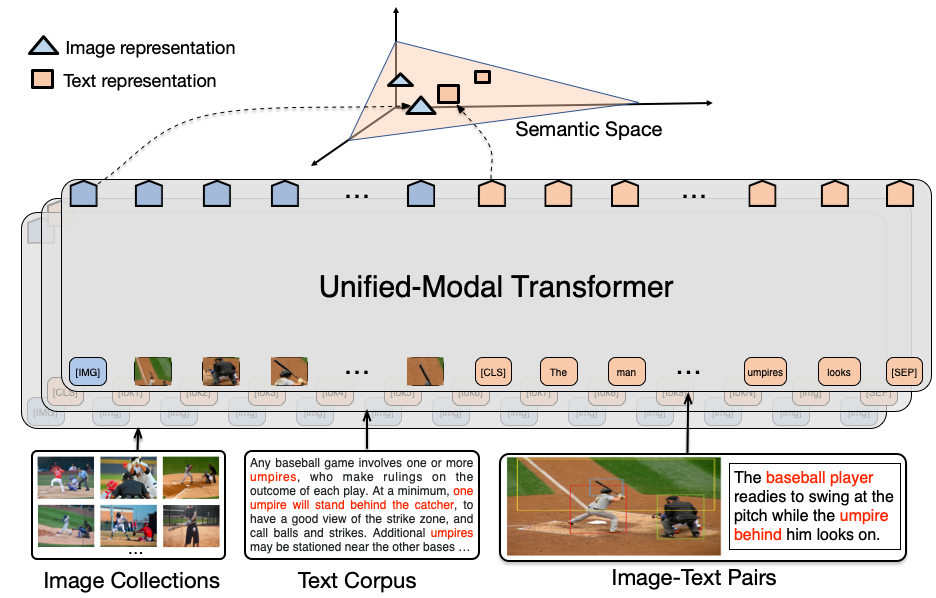
ernie-unimo/images/framework.png
0 → 100644
{kind=link}
183.1 KB
ernie-unimo/images/multiple.png
0 → 100644
{kind=link}

851.3 KB
ernie-unimo/images/paper.png
0 → 100644
{kind=link}

405.5 KB
ernie-unimo/images/single.png
0 → 100644
{kind=link}
729.3 KB
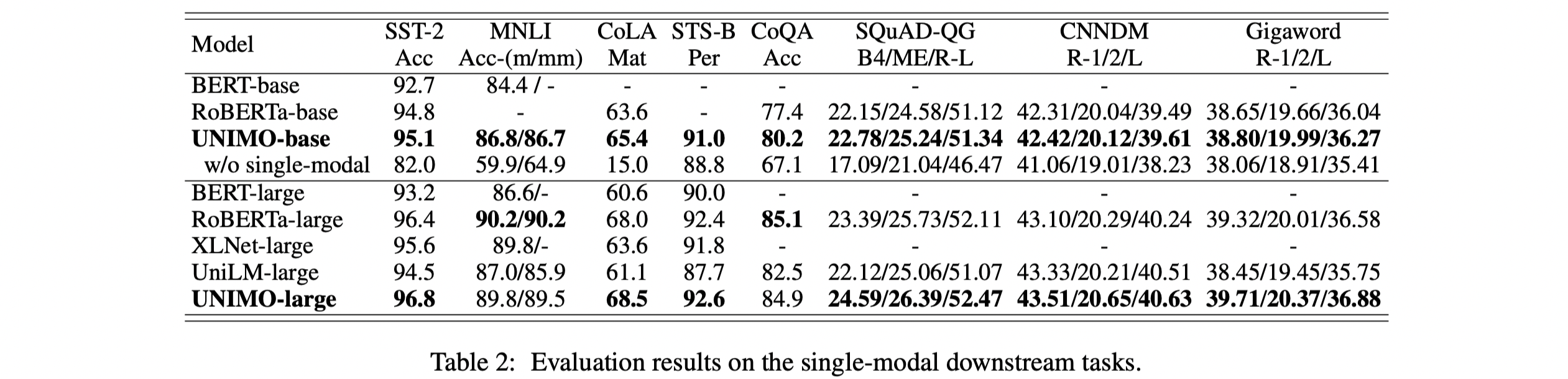
ernie-unimo/images/table1.png
0 → 100644
{kind=link}

759.3 KB
{kind=link}

67.0 KB
{kind=link}

74.9 KB
此差异已折叠。
此差异已折叠。
此差异已折叠。
ernie-unimo/requirements.txt
0 → 100644
ernie-unimo/src/__init__.py
0 → 100644
ernie-unimo/src/args/__init__.py
0 → 100644
ernie-unimo/src/eval/__init__.py
0 → 100644
ernie-unimo/src/eval/gen_eval.py
0 → 100644
ernie-unimo/src/eval/glue_eval.py
0 → 100644
ernie-unimo/src/eval/img_eval.py
0 → 100644
此差异已折叠。
此差异已折叠。
ernie-unimo/src/launch.py
0 → 100644
ernie-unimo/src/model/__init__.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
ernie-unimo/src/run_classifier.py
0 → 100644
此差异已折叠。
ernie-unimo/src/run_img2txt.py
0 → 100644
此差异已折叠。
ernie-unimo/src/run_regression.py
0 → 100644
此差异已折叠。
ernie-unimo/src/run_retrieval.py
0 → 100644
此差异已折叠。
ernie-unimo/src/run_seq2seq.py
0 → 100644
此差异已折叠。
ernie-unimo/src/utils/__init__.py
0 → 100644
ernie-unimo/src/utils/args.py
0 → 100644
此差异已折叠。
此差异已折叠。
ernie-unimo/src/utils/fp16.py
0 → 100644
此差异已折叠。
ernie-unimo/src/utils/init.py
0 → 100644
此差异已折叠。
此差异已折叠。
ernie-unimo/src/utils/stat_res.py
0 → 100644
此差异已折叠。
ernie-unimo/src/utils/utils.py
0 → 100644
此差异已折叠。
ernie-unimo/utils.sh
0 → 100644
此差异已折叠。