`Remind`: *ERNIE-Gram* model has been officially released in [here](??). Our reproduction codes will be released to [repro branch](https://github.com/PaddlePaddle/ERNIE/tree/repro) soon.
`Remind`: *ERNIE-Gram* model has been officially released in [here](#3-download-pretrained-models-optional). Our reproduction codes will be released to [repro branch](https://github.com/PaddlePaddle/ERNIE/tree/repro) soon.
## _ERNIE-Gram_: Pre-Training with Explicitly N-Gram Masked Language Modeling for Natural Language Understanding
## _ERNIE-Gram_: Pre-Training with Explicitly N-Gram Masked Language Modeling for Natural Language Understanding

-[Framework](#ernie-gram-framework)
-[Framework](#ernie-gram-framework)
-[Quick Tour](#quick-tour)
-[Quick Tour](#quick-tour)
-[Setup](#setup)
-[Setup](#setup)
...
@@ -17,8 +19,6 @@ English|[简体中文](./README.zh.md)
...
@@ -17,8 +19,6 @@ English|[简体中文](./README.zh.md)
### ERNIE-Gram Framework
### ERNIE-Gram Framework
整图
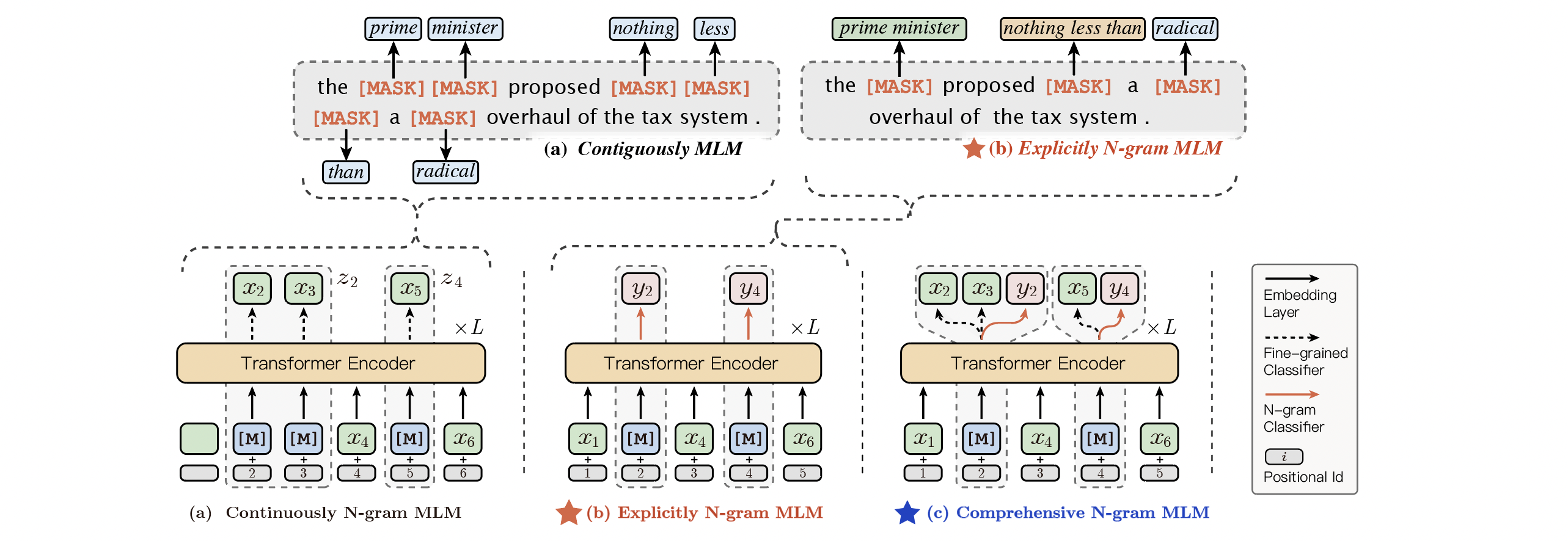
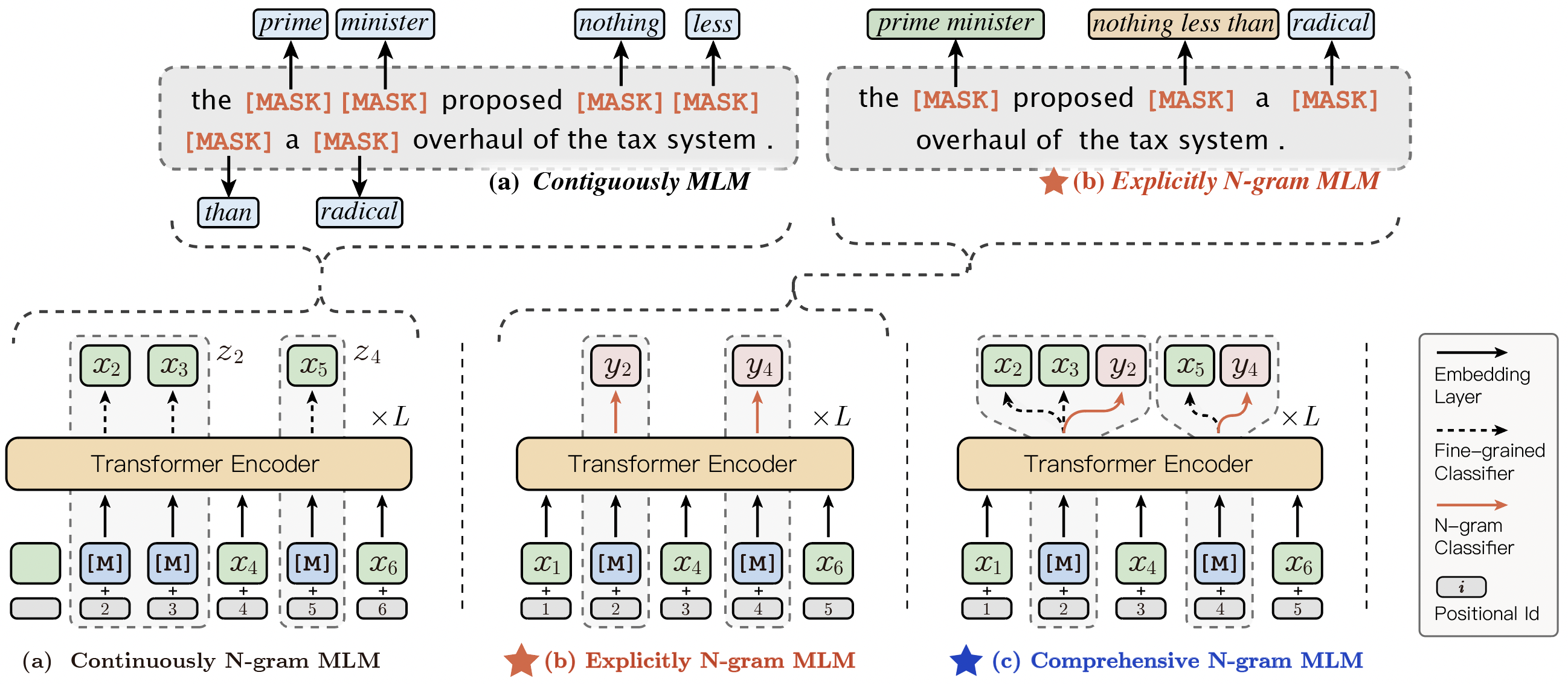
Since **ERNIE 1.0**, Baidu researchers have introduced **knowledge-enhanced representation learning** in pre-training to achieve better pre-training learning by masking consecutive words, phrases, named entities, and other semantic knowledge units. Furthermore, we propose **ERNIE-Gram**, an explicitly n-gram masking language model to enhance the integration of coarse-grained information for pre-training. In **ERNIE-Gram**, **n-grams** are masked and predicted directly using **explicit** n-gram identities rather than contiguous sequences of tokens.
Since **ERNIE 1.0**, Baidu researchers have introduced **knowledge-enhanced representation learning** in pre-training to achieve better pre-training learning by masking consecutive words, phrases, named entities, and other semantic knowledge units. Furthermore, we propose **ERNIE-Gram**, an explicitly n-gram masking language model to enhance the integration of coarse-grained information for pre-training. In **ERNIE-Gram**, **n-grams** are masked and predicted directly using **explicit** n-gram identities rather than contiguous sequences of tokens.
In downstream tasks, **ERNIE-gram** uses a `bert-style` fine-tuning approach, thus maintaining the same parameter size and computational complexity.
In downstream tasks, **ERNIE-gram** uses a `bert-style` fine-tuning approach, thus maintaining the same parameter size and computational complexity.
{kind=link}
{kind=link}