fix paddle install (#574)
* add ernie-vil * fix requirements.txt * Update README.md * Update requirements.txt * Update requirements.txt * Update requirements.txt * Update requirements.txt
Showing
{kind=link}
326.9 KB
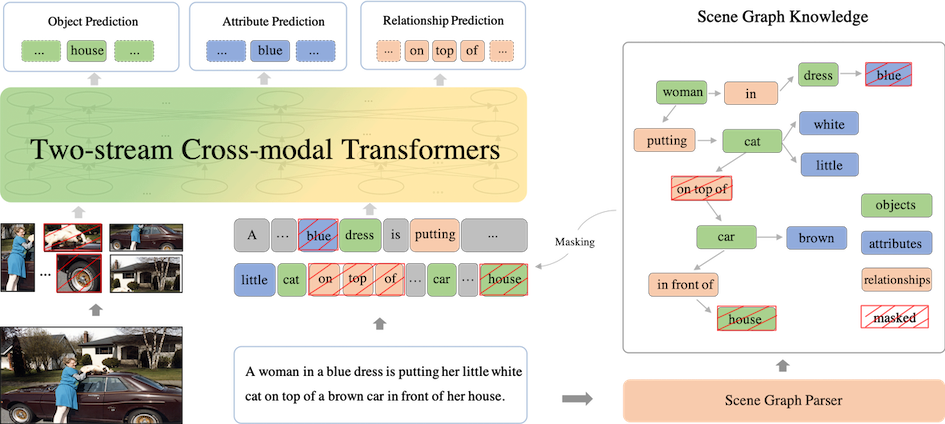
ernie-vil/README.md
0 → 100644
ernie-vil/README_zh.md
0 → 100644
ernie-vil/args/__init__.py
0 → 100644
ernie-vil/args/finetune_args.py
0 → 100644
ernie-vil/batching/__init__.py
0 → 100644
ernie-vil/conf/vcr/model_conf_vcr
0 → 100644
ernie-vil/conf/vcr/task_vcr.json
0 → 100644
ernie-vil/finetune.py
0 → 100755
ernie-vil/model/__init__.py
0 → 100644
ernie-vil/model/ernie_vil.py
0 → 100644
ernie-vil/optim/__init__.py
0 → 100644
ernie-vil/optim/optimization.py
0 → 100644
ernie-vil/preprocess/__init__.py
0 → 100644
ernie-vil/reader/__init__.py
0 → 100644
ernie-vil/requirements.txt
0 → 100644
ernie-vil/run_finetuning.sh
0 → 100644
ernie-vil/run_inference.sh
0 → 100644
ernie-vil/utils/__init__.py
0 → 100644
ernie-vil/utils/args.py
0 → 100644
ernie-vil/utils/init.py
0 → 100644
| ... | ... | @@ -6,4 +6,5 @@ scipy==1.2.1 |
| six==1.11.0 | ||
| sklearn==0.0 | ||
| sentencepiece==0.1.8 | ||
| opencv-python==3.4.2.17 | ||
| paddlepaddle-gpu==1.6.3.post107 |