Merge pull request #803 from webYFDT/ernie-kit-open-v1.0
Ernie kit open v1.0
Showing
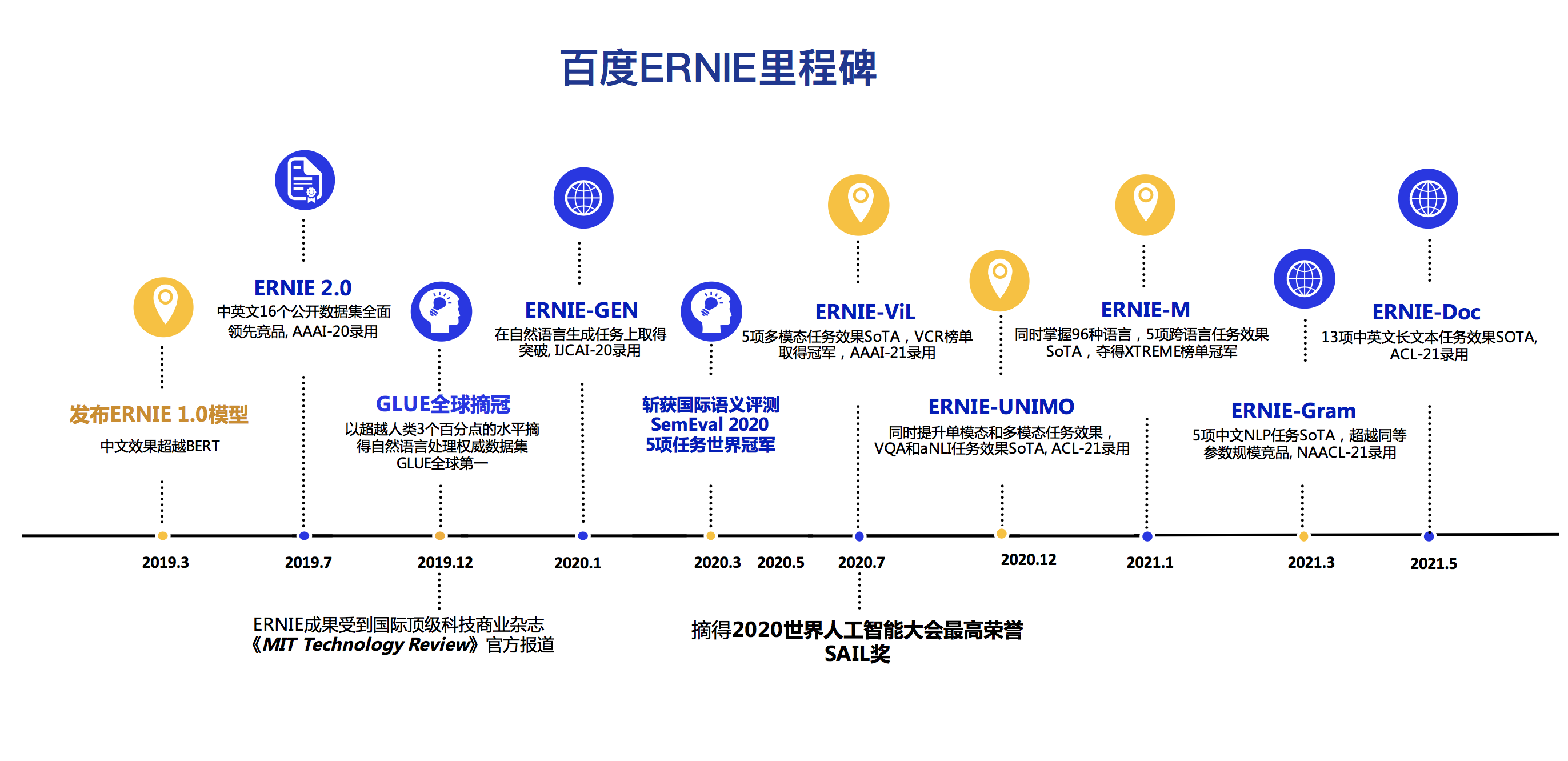
ERNIE_milestone_20210519_zh.png
0 → 100644
{kind=link}
459.0 KB
LICENSE
已删除
100644 → 0
README.en.md
已删除
100644 → 0
README.md
已删除
120000 → 0
README.md
0 → 100644
README.zh.md
已删除
100644 → 0
Research/readme.md
0 → 100644
demo/distill/README.md
已删除
100644 → 0
demo/distill/distill.py
已删除
100644 → 0
demo/finetune_classifier.py
已删除
100644 → 0
demo/finetune_mrc.py
已删除
100644 → 0
demo/finetune_ner.py
已删除
100644 → 0
demo/mrc/mrc_reader.py
已删除
100644 → 0
demo/optimization.py
已删除
100644 → 0
demo/pretrain/README.md
已删除
100644 → 0
demo/pretrain/pretrain.py
已删除
100644 → 0
demo/seq2seq/README.md
已删除
100644 → 0
demo/seq2seq/decode.py
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
demo/utils.py
已删除
100644 → 0
此差异已折叠。
ernie-doc/README.md
已删除
100644 → 0
此差异已折叠。
ernie-gen/README.md
已删除
100644 → 0
此差异已折叠。
{kind=link}
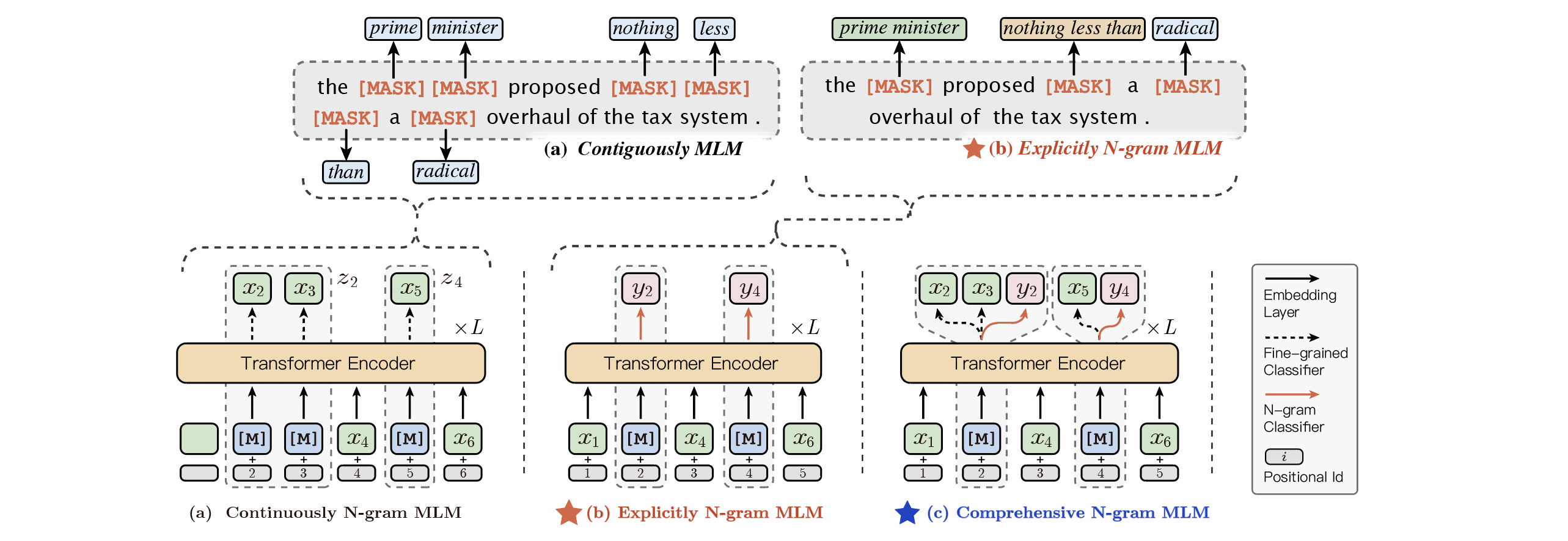
791.3 KB
ernie-gram/README.en.md
已删除
100644 → 0
此差异已折叠。
ernie-gram/README.md
已删除
120000 → 0
此差异已折叠。
ernie-gram/README.zh.md
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
ernie-gram/finetune_mrc.py
已删除
100644 → 0
此差异已折叠。
ernie-gram/finetune_ner.py
已删除
100644 → 0
此差异已折叠。
ernie-gram/mrc/mrc_metrics.py
已删除
100644 → 0
此差异已折叠。
ernie-gram/mrc/mrc_reader.py
已删除
100644 → 0
此差异已折叠。
ernie-gram/optimization.py
已删除
100644 → 0
此差异已折叠。
ernie-gram/run_cls.sh
已删除
100644 → 0
此差异已折叠。
ernie-gram/run_mrc.sh
已删除
100644 → 0
此差异已折叠。
ernie-gram/run_ner.sh
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
ernie-gram/utils.py
已删除
100644 → 0
此差异已折叠。
ernie-m/README.md
已删除
100644 → 0
此差异已折叠。
ernie-unimo/README.md
已删除
100644 → 0
此差异已折叠。
ernie-vil/.meta/ernie-vil.png
已删除
100644 → 0
{kind=link}
此差异已折叠。
ernie-vil/README.md
已删除
100644 → 0
此差异已折叠。
ernie/__init__.py
已删除
100644 → 0
此差异已折叠。
ernie/file_utils.py
已删除
100644 → 0
此差异已折叠。
ernie/modeling_ernie.py
已删除
100644 → 0
此差异已折叠。
ernie/tokenizing_ernie.py
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
inference/README.md
已删除
100644 → 0
此差异已折叠。
inference/cpu/CMakeLists.txt
已删除
100644 → 0
此差异已折叠。
inference/cpu/inference.cc
已删除
100644 → 0
此差异已折叠。
inference/cpu/run.sh
已删除
100755 → 0
此差异已折叠。
inference/data/sample
已删除
100644 → 0
此差异已折叠。
inference/gpu/CMakeLists.txt
已删除
100644 → 0
此差异已折叠。
inference/gpu/inference.cc
已删除
100644 → 0
此差异已折叠。
inference/gpu/run.sh
已删除
100755 → 0
此差异已折叠。
nlp-ernie/.DS_Store
0 → 100644
此差异已折叠。
nlp-ernie/wenxin/.gitignore
0 → 100644
此差异已折叠。
nlp-ernie/wenxin/__init__.py
0 → 100644
此差异已折叠。
nlp-ernie/wenxin/build.sh
0 → 100644
此差异已折叠。
nlp-ernie/wenxin/ci.yml
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
nlp-ernie/wenxin/common/rule.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
nlp-ernie/wenxin/data/data_set.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
nlp-ernie/wenxin/data/field.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
nlp-ernie/wenxin/metrics/mrr.py
0 → 100644
此差异已折叠。
nlp-ernie/wenxin/metrics/tuple.py
0 → 100644
此差异已折叠。
此差异已折叠。
nlp-ernie/wenxin/model/model.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
nlp-ernie/wenxin/modules/ernie.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
nlp-ernie/wenxin/utils/args.py
0 → 100644
此差异已折叠。
nlp-ernie/wenxin/utils/log.py
0 → 100644
此差异已折叠。
此差异已折叠。
nlp-ernie/wenxin/utils/params.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
nlp-ernie/wenxin/version.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
nlp-ernie/wenxin_appzoo/README.md
0 → 100644
此差异已折叠。
nlp-ernie/wenxin_appzoo/build.sh
0 → 100644
此差异已折叠。
nlp-ernie/wenxin_appzoo/ci.yml
0 → 100644
此差异已折叠。
此差异已折叠。
nlp-ernie/wenxin_appzoo/setup.cfg
0 → 100644
此差异已折叠。
nlp-ernie/wenxin_appzoo/setup.py
0 → 100755
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
propeller/__init__.py
已删除
100644 → 0
此差异已折叠。
propeller/data/__init__.py
已删除
100644 → 0
此差异已折叠。
propeller/data/example.proto
已删除
100644 → 0
此差异已折叠。
propeller/data/example_pb2.py
已删除
100644 → 0
此差异已折叠。
propeller/data/feature.proto
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
propeller/data/feature_pb2.py
已删除
100644 → 0
此差异已折叠。
propeller/data/functional.py
已删除
100644 → 0
此差异已折叠。
propeller/paddle/__init__.py
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
propeller/paddle/summary.py
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
propeller/service/__init__.py
已删除
100644 → 0
此差异已折叠。
propeller/service/client.py
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
此差异已折叠。
propeller/service/server.py
已删除
100644 → 0
此差异已折叠。
propeller/service/utils.py
已删除
100644 → 0
此差异已折叠。
propeller/tools/__init__.py
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
此差异已折叠。
propeller/train/__init__.py
已删除
100644 → 0
此差异已折叠。
propeller/train/model.py
已删除
100644 → 0
此差异已折叠。
propeller/types.py
已删除
100644 → 0
此差异已折叠。
propeller/util.py
已删除
100644 → 0
此差异已折叠。
readme_env.md
0 → 100644
此差异已折叠。
readme_model.md
0 → 100644
此差异已折叠。
readme_score.md
0 → 100644
此差异已折叠。
requirements.txt
已删除
100644 → 0
此差异已折叠。
setup.py
已删除
100644 → 0
此差异已折叠。