Training gets hung while using multiple GPU's
Created by: dalonlobo
Hi,
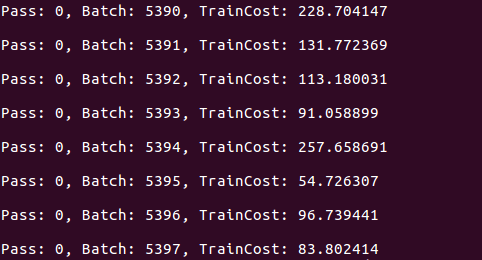
I'm training on a custom dataset of approx 1000hrs of data. The training starts and after completion of some batches (In this case after completion of 5397batch), the training just hangs. It does not progress to next batch. The training is using 4 GPU's on azure VM. All 4 GPU's are only ~40% utilized, so the problem is not with memory. Batch size used is 32. GPU used is K80. There is no error message nor does the program exit.
Is there a problem with using multiple GPU's, does data read/write between them cause any error? Is there a way to debug this?
Please help!
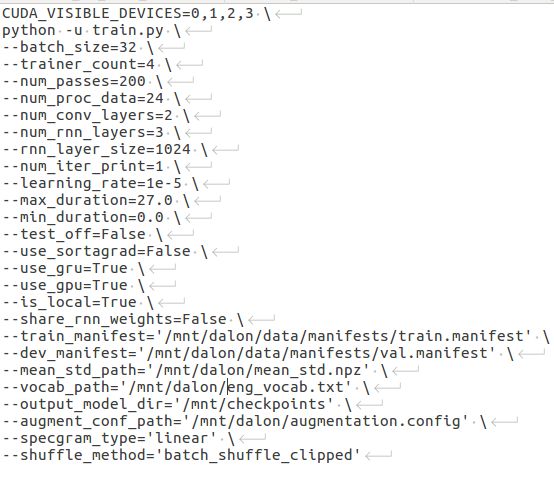
Configuration:
Screenshot of output: