rm tune.py in root dir of DS2
Showing
此差异已折叠。
cloud/README.md
0 → 100644
cloud/_init_paths.py
0 → 100644
cloud/pcloud_submit.sh
0 → 100644
cloud/pcloud_train.sh
0 → 100644
cloud/pcloud_upload_data.sh
0 → 100644
cloud/split_data.py
0 → 100644
cloud/upload_data.py
0 → 100644
data/aishell/aishell.py
0 → 100644
datasets/run_all.sh
已删除
100644 → 0
datasets/run_noise.sh
已删除
100644 → 0
datasets/vocab/eng_vocab.txt
已删除
100644 → 0
decoders/swig/__init__.py
0 → 100644
decoders/swig/_init_paths.py
0 → 100644
decoders/swig/decoder_utils.cpp
0 → 100644
decoders/swig/decoder_utils.h
0 → 100644
decoders/swig/decoders.i
0 → 100644
decoders/swig/path_trie.cpp
0 → 100644
decoders/swig/path_trie.h
0 → 100644
decoders/swig/scorer.cpp
0 → 100644
decoders/swig/scorer.h
0 → 100644
decoders/swig/setup.py
0 → 100644
decoders/swig/setup.sh
0 → 100644
decoders/swig_wrapper.py
0 → 100644
docs/images/multi_gpu_speedup.png
0 → 100755
{kind=link}
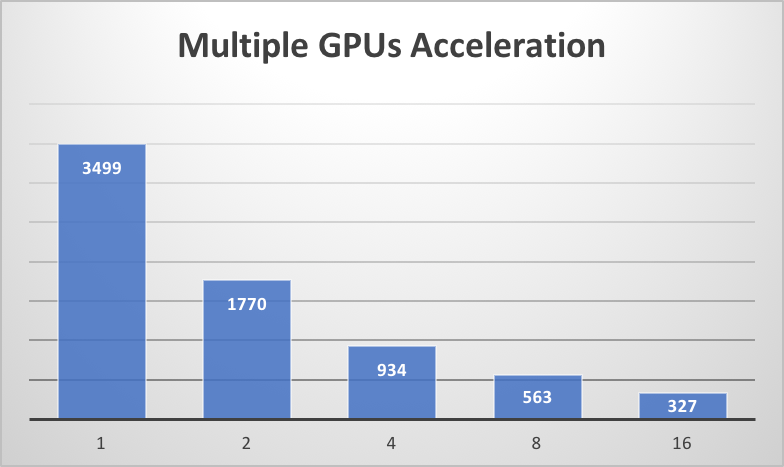
153.1 KB
{kind=link}
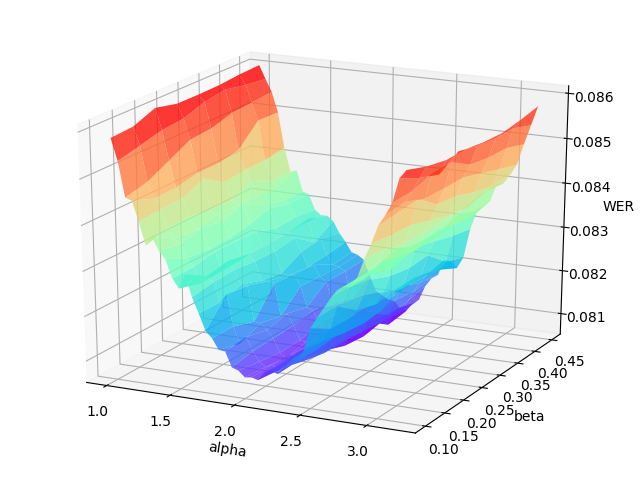
107.9 KB
examples/aishell/run_data.sh
0 → 100644
examples/aishell/run_train.sh
0 → 100644
examples/librispeech/run_data.sh
0 → 100644
examples/librispeech/run_infer.sh
0 → 100644
examples/librispeech/run_test.sh
0 → 100644
examples/librispeech/run_train.sh
0 → 100644
examples/librispeech/run_tune.sh
0 → 100644
examples/tiny/run_data.sh
0 → 100644
examples/tiny/run_infer.sh
0 → 100644
examples/tiny/run_infer_golden.sh
0 → 100644
examples/tiny/run_test.sh
0 → 100644
examples/tiny/run_test_golden.sh
0 → 100644
examples/tiny/run_train.sh
0 → 100644
examples/tiny/run_tune.sh
0 → 100644
lm/run.sh
已删除
100644 → 0
model_utils/__init__.py
0 → 100644
models/aishell/download_model.sh
0 → 100644
models/lm/download_lm_ch.sh
0 → 100644
models/lm/download_lm_en.sh
0 → 100644
| ... | @@ -2,4 +2,3 @@ scipy==0.13.1 | ... | @@ -2,4 +2,3 @@ scipy==0.13.1 |
| resampy==0.1.5 | resampy==0.1.5 | ||
| SoundFile==0.9.0.post1 | SoundFile==0.9.0.post1 | ||
| python_speech_features | python_speech_features | ||
| https://github.com/luotao1/kenlm/archive/master.zip |
此差异已折叠。
tests/test_setup.py
已删除
100644 → 0
tools/_init_paths.py
0 → 100644
tools/build_vocab.py
0 → 100644
此差异已折叠。
tools/profile.sh
0 → 100644
此差异已折叠。
tools/tune.py
0 → 100644
此差异已折叠。
此差异已折叠。
tune.py
已删除
100644 → 0
此差异已折叠。
utils/__init__.py
0 → 100644
utils/utility.sh
0 → 100644
此差异已折叠。