@@ -11,7 +11,7 @@ Audio retrieval (speech, music, speaker, etc.) enables querying and finding simi
...
@@ -11,7 +11,7 @@ Audio retrieval (speech, music, speaker, etc.) enables querying and finding simi
In this demo, you will learn how to build an audio retrieval system to retrieve similar sound snippets. The uploaded audio clips are converted into vector data using paddlespeech-based pre-training models (audio classification model, speaker recognition model, etc.) and stored in Milvus. Milvus automatically generates a unique ID for each vector, then stores the ID and the corresponding audio information (audio ID, audio speaker ID, etc.) in MySQL to complete the library construction. During retrieval, users upload test audio to obtain vector, and then conduct vector similarity search in Milvus. The retrieval result returned by Milvus is vector ID, and the corresponding audio information can be queried in MySQL by ID
In this demo, you will learn how to build an audio retrieval system to retrieve similar sound snippets. The uploaded audio clips are converted into vector data using paddlespeech-based pre-training models (audio classification model, speaker recognition model, etc.) and stored in Milvus. Milvus automatically generates a unique ID for each vector, then stores the ID and the corresponding audio information (audio ID, audio speaker ID, etc.) in MySQL to complete the library construction. During retrieval, users upload test audio to obtain vector, and then conduct vector similarity search in Milvus. The retrieval result returned by Milvus is vector ID, and the corresponding audio information can be queried in MySQL by ID


Note:this demo uses the [CN-Celeb](http://openslr.org/82/) dataset of at least 650,000 audio entries and 3000 speakers to build the audio vector library, which is then retrieved using a preset distance calculation. The dataset can also use other, Adjust as needed, e.g. Librispeech, VoxCeleb, UrbanSound, etc
Note:this demo uses the [CN-Celeb](http://openslr.org/82/) dataset of at least 650,000 audio entries and 3000 speakers to build the audio vector library, which is then retrieved using a preset distance calculation. The dataset can also use other, Adjust as needed, e.g. Librispeech, VoxCeleb, UrbanSound, etc
...
@@ -31,6 +31,7 @@ Creating milvus-minio ... done
...
@@ -31,6 +31,7 @@ Creating milvus-minio ... done
Creating milvus-etcd ... done
Creating milvus-etcd ... done
Creating audio-mysql ... done
Creating audio-mysql ... done
Creating milvus-standalone ... done
Creating milvus-standalone ... done
Creating audio-webclient ... done
```
```
And show all containers with `docker ps`, and you can use `docker logs audio-mysql` to get the logs of server container
And show all containers with `docker ps`, and you can use `docker logs audio-mysql` to get the logs of server container
...
@@ -41,7 +42,7 @@ b2bcf279e599 milvusdb/milvus:v2.0.1 "/tini -- milvus run…" 22 hours ago Up
...
@@ -41,7 +42,7 @@ b2bcf279e599 milvusdb/milvus:v2.0.1 "/tini -- milvus run…" 22 hours ago Up
d8ef4c84e25c mysql:5.7 "docker-entrypoint.s…" 22 hours ago Up 22 hours 0.0.0.0:3306->3306/tcp, 33060/tcp audio-mysql
d8ef4c84e25c mysql:5.7 "docker-entrypoint.s…" 22 hours ago Up 22 hours 0.0.0.0:3306->3306/tcp, 33060/tcp audio-mysql
8fb501edb4f3 quay.io/coreos/etcd:v3.5.0 "etcd -advertise-cli…" 22 hours ago Up 22 hours 2379-2380/tcp milvus-etcd
8fb501edb4f3 quay.io/coreos/etcd:v3.5.0 "etcd -advertise-cli…" 22 hours ago Up 22 hours 2379-2380/tcp milvus-etcd
ffce340b3790 minio/minio:RELEASE.2020-12-03T00-03-10Z "/usr/bin/docker-ent…" 22 hours ago Up 22 hours (healthy) 9000/tcp milvus-minio
ffce340b3790 minio/minio:RELEASE.2020-12-03T00-03-10Z "/usr/bin/docker-ent…" 22 hours ago Up 22 hours (healthy) 9000/tcp milvus-minio
15c84a506754 iregistry.baidu-int.com/paddlespeech/audio-search-client:1.0 "/bin/bash -c '/usr/…" 22 hours ago Up 22 hours (healthy) 0.0.0.0:8068->80/tcp audio-webclient
```
```
### 2. Start API Server
### 2. Start API Server
...
@@ -49,79 +50,112 @@ Then to start the system server, and it provides HTTP backend services.
...
@@ -49,79 +50,112 @@ Then to start the system server, and it provides HTTP backend services.
- Install the Python packages
- Install the Python packages
```bash
```bash
pip install-r requirements.txt
pip install-r requirements.txt
```
```
- Set configuration
- Set configuration
```bash
```bash
vim src/config.py
vim src/config.py
```
```
Modify the parameters according to your own environment. Here listing some parameters that need to be set, for more information please refer to [config.py](./src/config.py).
Modify the parameters according to your own environment. Here listing some parameters that need to be set, for more information please refer to [config.py](./src/config.py).
Note: If you want to build a quick demo, you can use ./src/test_main.py:download_audio_data function, it download 20 audio files , Subsequent results show this collection as an example
Note: If you want to build a quick demo, you can use ./src/test_main.py:download_audio_data function, it downloads 20 audio files , Subsequent results show this collection as an example
- Run
- scripts test (recommend!)
The internal process is downloading data, loading the Paddlespeech model, extracting embedding, storing library, retrieving and deleting library
```bash
python ./src/test_main.py
```
Output:
The internal process is downloading data, loading the Paddlespeech model, extracting embedding, storing library, retrieving and deleting library
```bash
```bash
Checkpoint path: %your model path%
python ./src/test_main.py
Extracting feature from audio No. 1 , 20 audios in total
```
Extracting feature from audio No. 2 , 20 audios in total
...
Output:
2022-03-09 17:22:13,870 | INFO | main.py | load_audios | 85 | Successfully loaded data, total count: 20
```bash
2022-03-09 17:22:13,898 | INFO | main.py | count_audio | 147 | Successfully count the number of data!
2022-03-09 17:22:32,582 | INFO | main.py | search_local_audio | 135 | Successfully searched similar audio!
...
2022-03-09 17:22:33,658 | INFO | main.py | drop_tables | 159 | Successfully drop tables in Milvus and MySQL!
2022-03-09 17:22:32,580 | INFO | main.py | search_local_audio | 131 | search result http://testserver/data?audio_path=./example_audio/test.wav, distance 0.0
```
2022-03-09 17:22:32,580 | INFO | main.py | search_local_audio | 131 | search result http://testserver/data?audio_path=./example_audio/knife_chopping.wav, distance 0.021805256605148315
2022-03-09 17:22:32,580 | INFO | main.py | search_local_audio | 131 | search result http://testserver/data?audio_path=./example_audio/knife_cut_into_flesh.wav, distance 0.052762262523174286
...
2022-03-09 17:22:32,582 | INFO | main.py | search_local_audio | 135 | Successfully searched similar audio!
2022-03-09 17:22:33,658 | INFO | main.py | drop_tables | 159 | Successfully drop tables in Milvus and MySQL!
```
- GUI test (optional)
Navigate to 127.0.0.1:8068 in your browser to access the front-end interface.
- Insert data
Download the data and decompress it to a path named /home/speech/data. Then enter /home/speech/data in the address bar of the upload page to upload the data

- Search for similar audio
Select the magnifying glass icon on the left side of the interface. Then, press the "Default Target Audio File" button and upload a .wav sound file you'd like to search. Results will be displayed
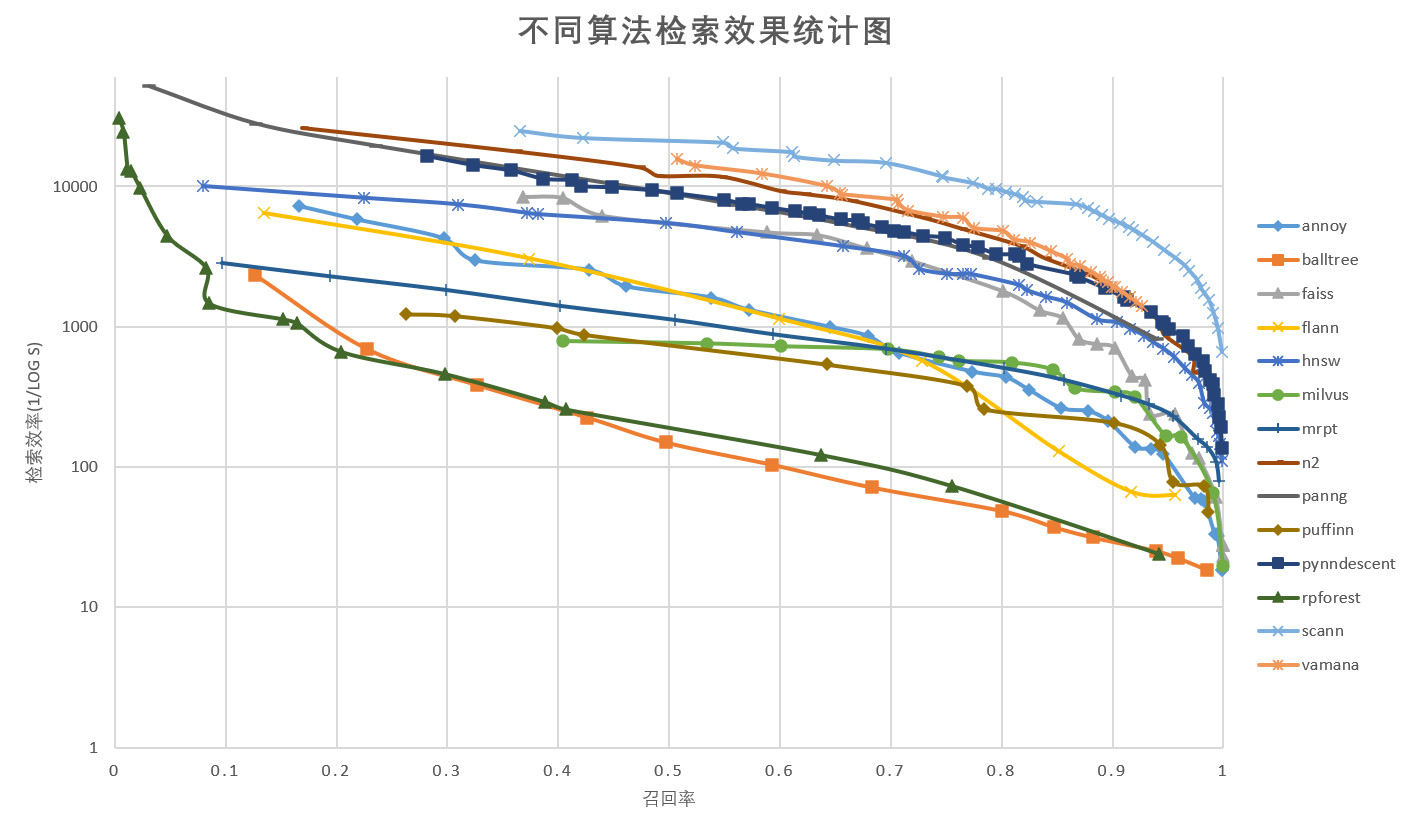
recall and elapsed time statistics are shown in the following figure:

Compared with other algorithms, the retrieval framework based on Milvus ranks in the middle in terms of speed and performance. Under the premise of 90% recall rate, the retrieval time is about 2.9 milliseconds, which can meet most application scenarios
### 4.Pretrained Models
### 5.Pretrained Models
Here is a list of pretrained models released by PaddleSpeech :
Here is a list of pretrained models released by PaddleSpeech :
{kind=link}