[doc] add topic/gan_vocoder (#1150)
* add conformer demos * add README_cn for demos/text_to_speech, test=doc_fix * add README_cn for demos/text_to_speech, test=doc_fix * add README_cn for demos/text_to_speech, test=doc_fix * update tts_tutorial.ipynb, test=doc_fix * update tts_tutorial.ipynb, test=doc_fix * update tts_tutorial.ipynb, test=doc_fix * add topic/gan_vocoder, test=doc_fix * add topic/gan_vocoder, test=doc_fix * add topic/gan_vocoder, test=doc_fix
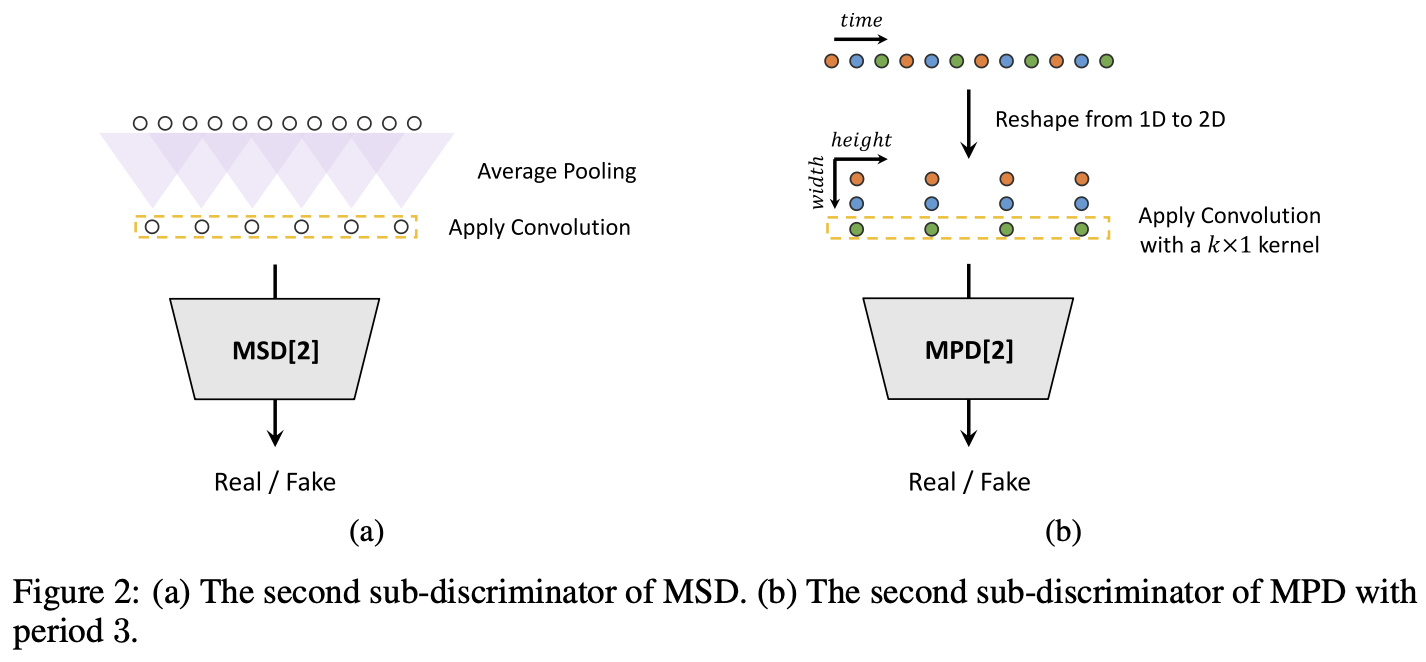
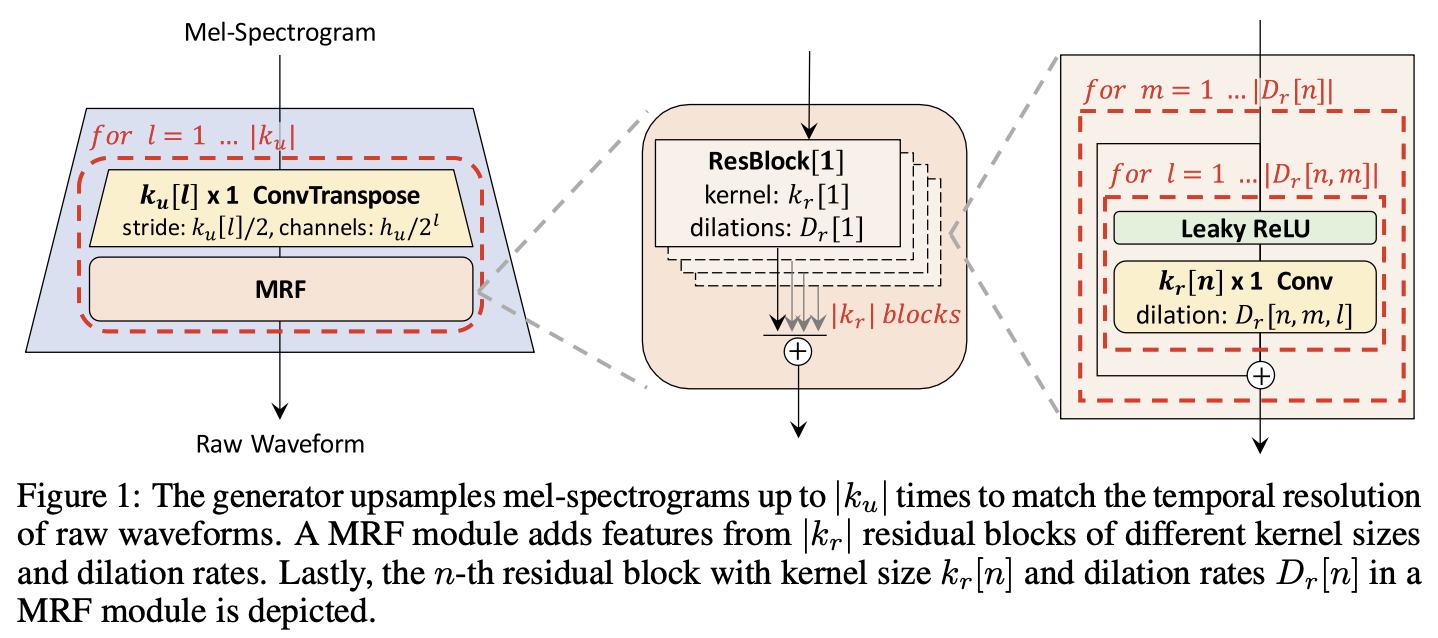
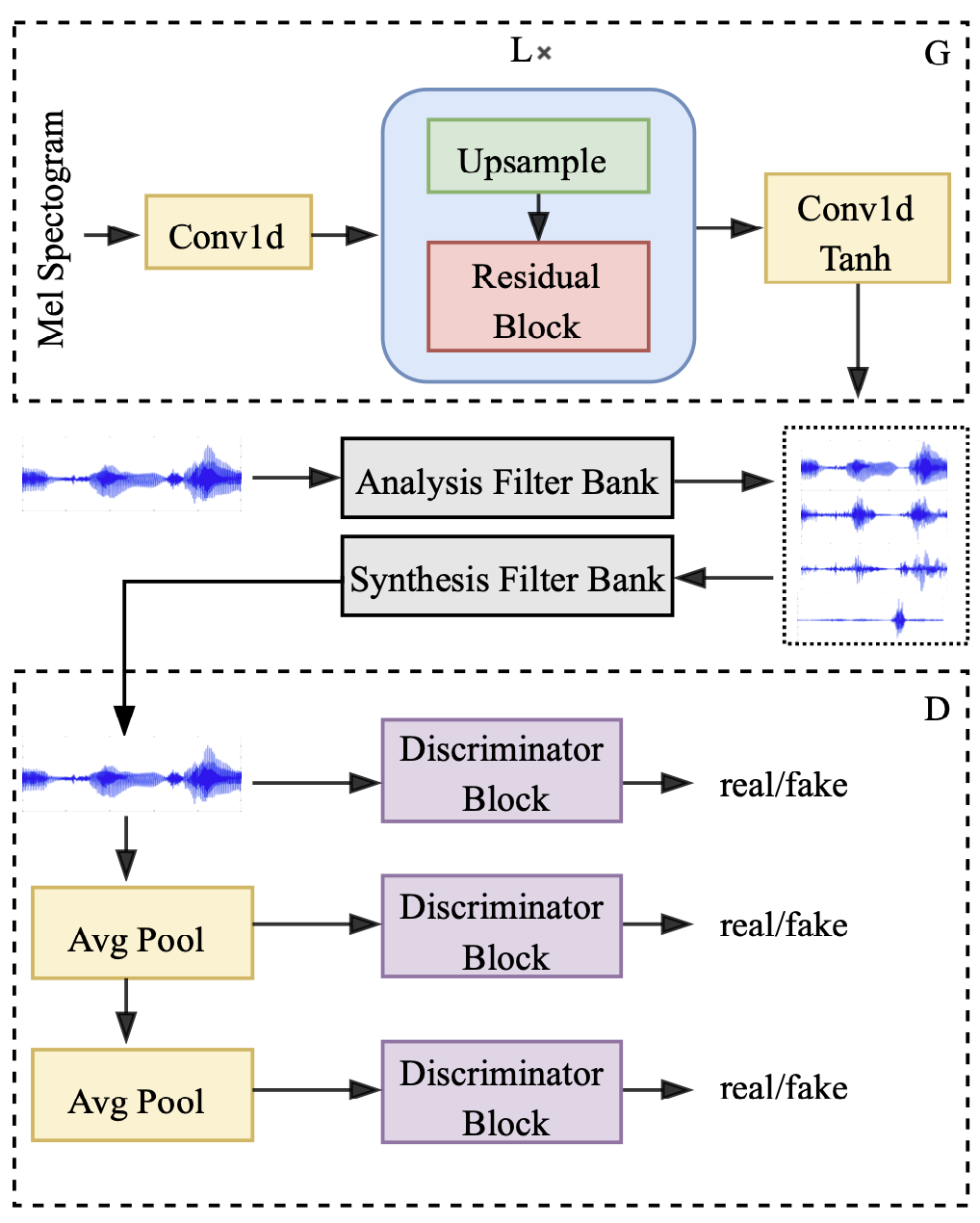
Showing
{kind=link}
105.6 KB
{kind=link}
169.1 KB
{kind=link}
205.5 KB
{kind=link}
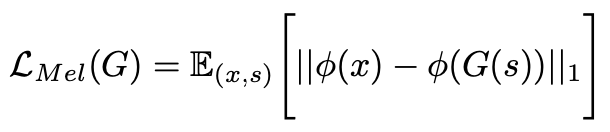
13.8 KB
{kind=link}
93.1 KB
{kind=link}
68.6 KB
{kind=link}
30.1 KB
{kind=link}
40.4 KB
{kind=link}
37.2 KB
{kind=link}
259.2 KB
{kind=link}
311.0 KB
{kind=link}
313.7 KB