Merge branch 'PaddlePaddle:develop' into develop
Showing
demos/speech_web/.gitignore
0 → 100644
demos/speech_web/README_cn.md
0 → 100644
demos/speech_web/docs/效果展示.png
0 → 100644
{kind=link}
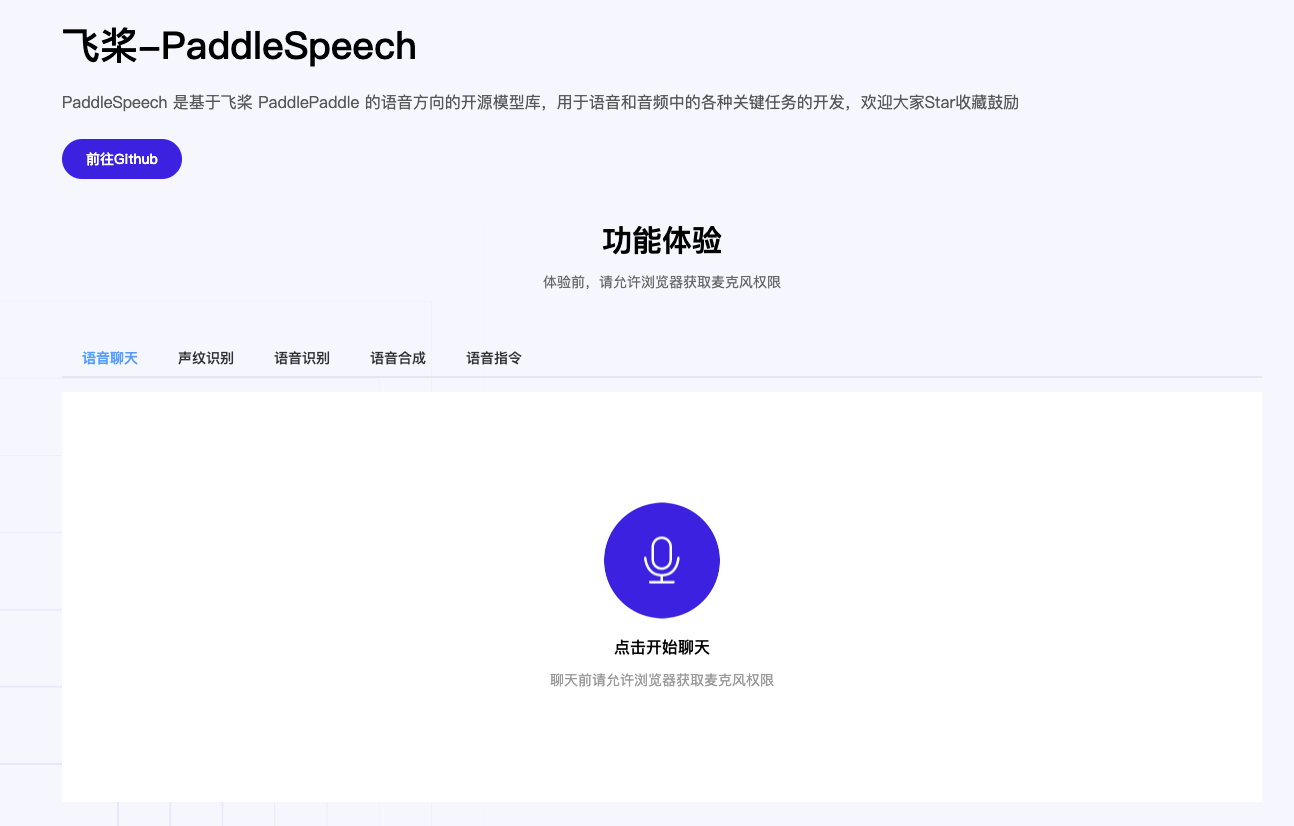
84.1 KB
此差异已折叠。
4.2 KB
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}

76.7 KB
{kind=link}

8.3 KB
{kind=link}

8.8 KB
{kind=link}

9.7 KB
{kind=link}

5.4 KB
{kind=link}

7.3 KB
{kind=link}

8.0 KB
{kind=link}
6.7 KB
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
demos/speech_web/接口文档.md
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddlespeech/utils/env.py
0 → 100644
此差异已折叠。
此差异已折叠。