add ctc loss topic
Showing
docs/topic/ctc/ctc_loss.md
0 → 100644
{kind=link}

162.1 KB
{kind=link}

65.8 KB
{kind=link}

50.6 KB
{kind=link}
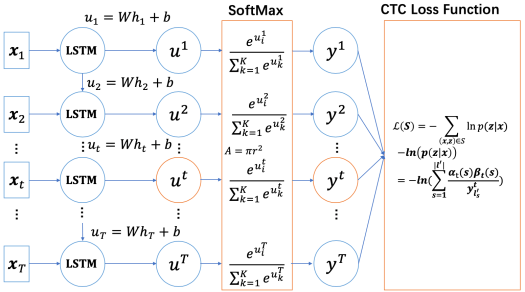
20.6 KB
{kind=link}
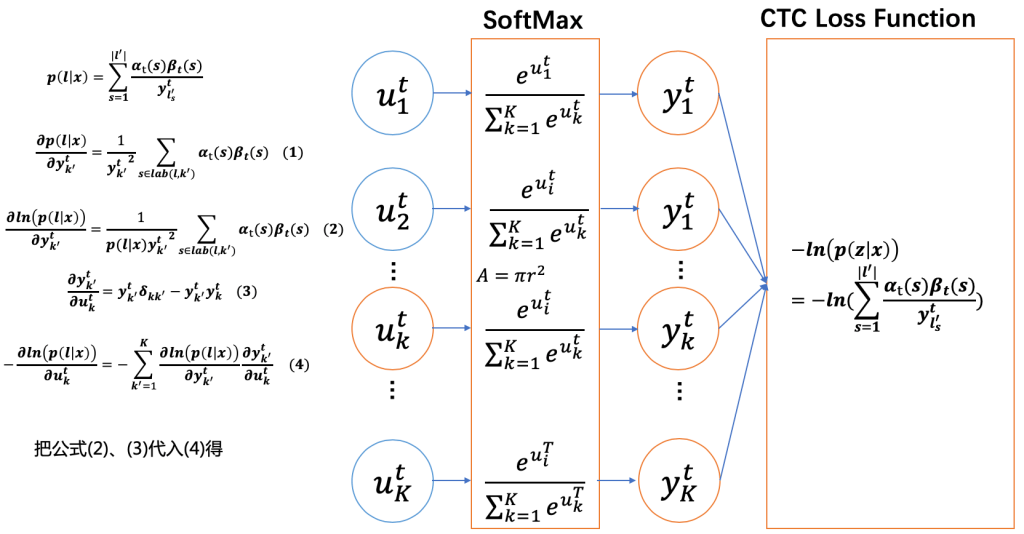
50.4 KB
{kind=link}

48.3 KB
{kind=link}

114.8 KB
{kind=link}
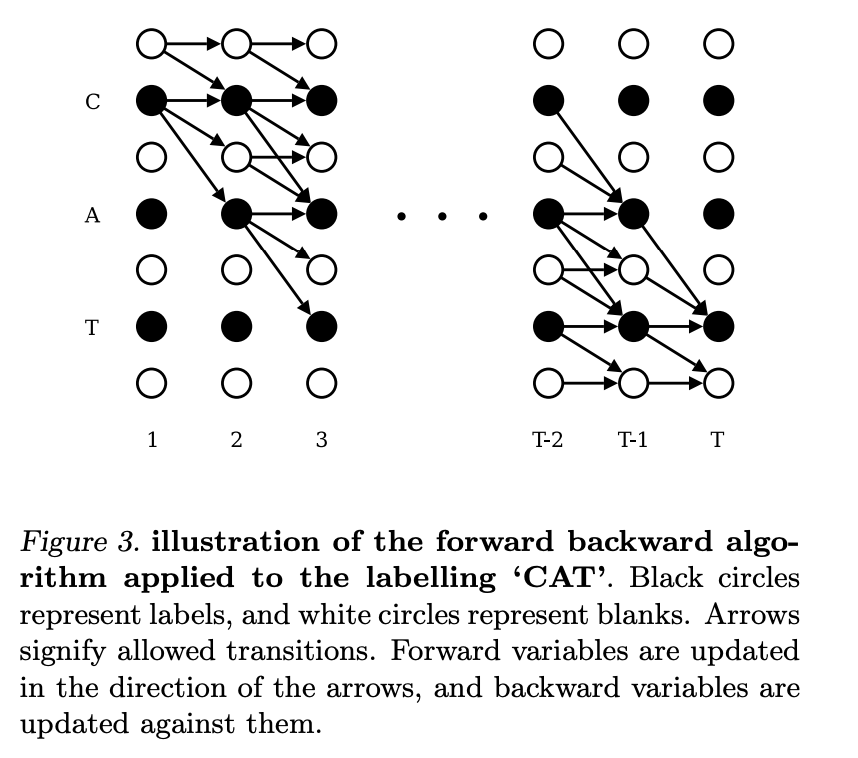
123.4 KB
{kind=link}

112.6 KB
{kind=link}

49.8 KB
{kind=link}
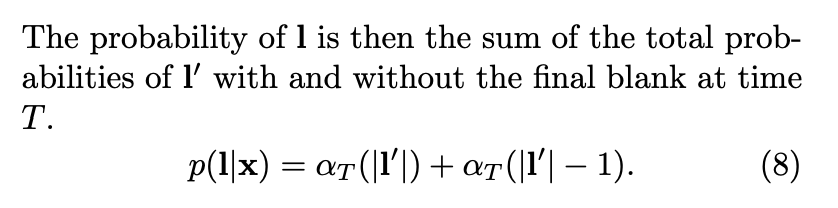
31.3 KB
{kind=link}

111.5 KB
{kind=link}

223.1 KB
{kind=link}

140.1 KB
{kind=link}

107.9 KB
{kind=link}

125.5 KB