Merge branch 'develop' into vox12
Showing
demos/audio_searching/README.md
0 → 100644
{kind=link}

29.0 KB
{kind=link}

49.7 KB
{kind=link}
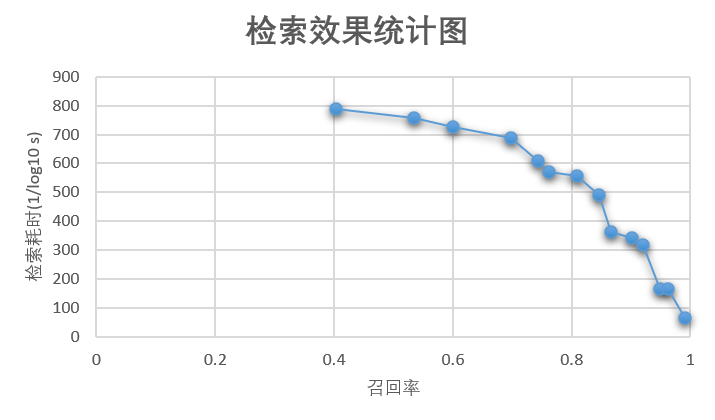
32.9 KB
{kind=link}
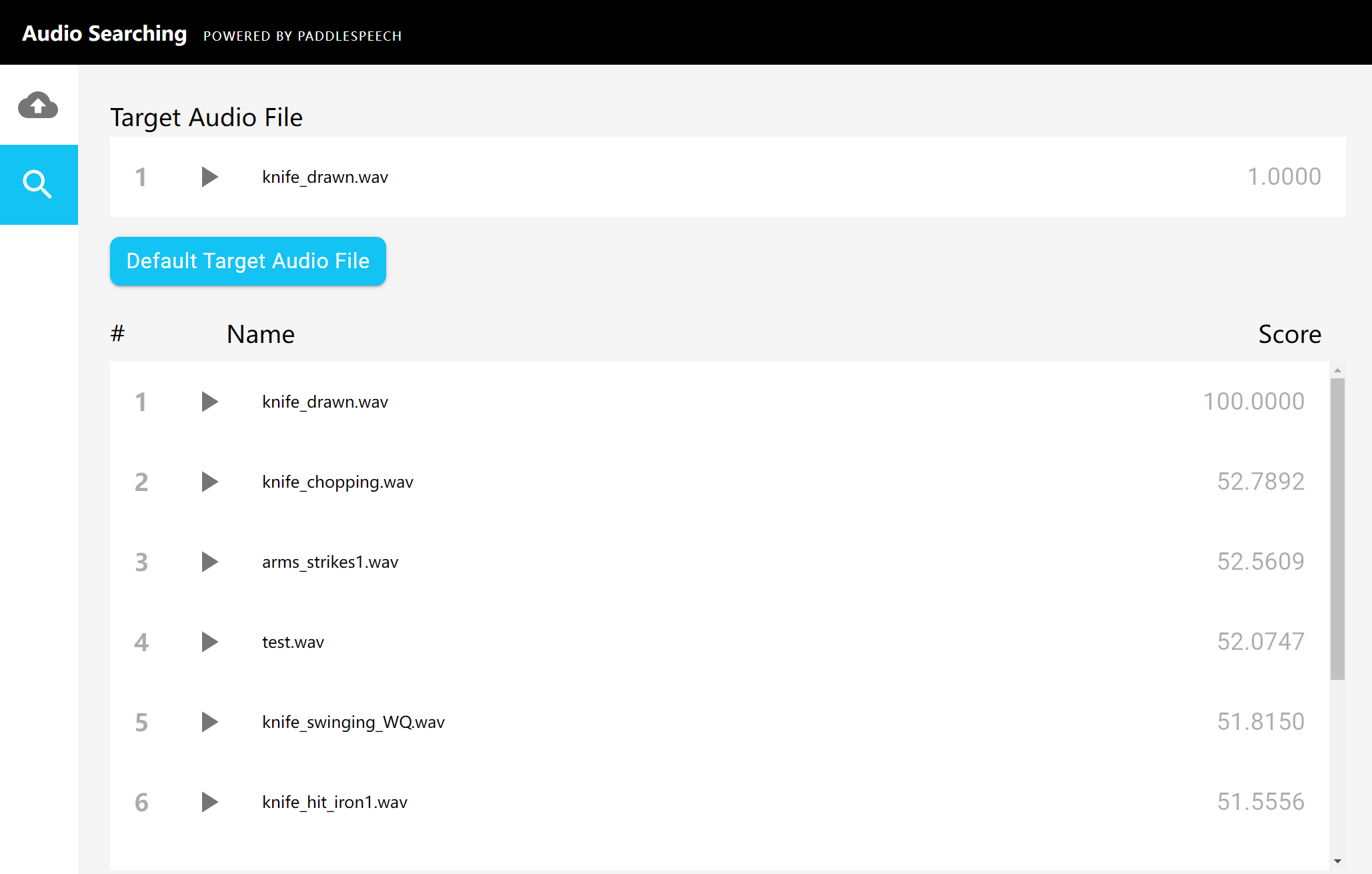
84.1 KB
demos/audio_searching/src/logs.py
0 → 100644
demos/audio_searching/src/main.py
0 → 100644
demos/speech_server/.gitignore
0 → 100644
demos/speech_server/cls_client.sh
0 → 100644
examples/ljspeech/voc5/README.md
0 → 100644
examples/ljspeech/voc5/path.sh
0 → 100755
examples/ljspeech/voc5/run.sh
0 → 100755
paddleaudio/.gitignore
0 → 100644
paddleaudio/docs/Makefile
0 → 100644
paddleaudio/docs/README.md
0 → 100644
{kind=link}

4.9 KB
paddleaudio/docs/make.bat
0 → 100644
paddleaudio/docs/source/conf.py
0 → 100644
paddleaudio/docs/source/index.rst
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddlespeech/s2t/modules/align.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
speechx/.gitignore
0 → 100644
此差异已折叠。
speechx/README.md
0 → 100644
此差异已折叠。
speechx/build.sh
0 → 100755
此差异已折叠。
speechx/cmake/EnableCMP0048.cmake
0 → 100644
此差异已折叠。
speechx/cmake/external/absl.cmake
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
speechx/cmake/external/glog.cmake
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
speechx/examples/.gitignore
0 → 100644
此差异已折叠。
speechx/examples/.gitkeep
已删除
100644 → 0
speechx/examples/CMakeLists.txt
0 → 100644
此差异已折叠。
speechx/examples/README.md
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
speechx/examples/decoder/path.sh
0 → 100644
此差异已折叠。
speechx/examples/decoder/run.sh
0 → 100755
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
speechx/examples/feat/path.sh
0 → 100644
此差异已折叠。
speechx/examples/feat/run.sh
0 → 100755
此差异已折叠。
speechx/examples/feat/valgrind.sh
0 → 100755
此差异已折叠。
此差异已折叠。
speechx/examples/nnet/path.sh
0 → 100644
此差异已折叠。
此差异已折叠。
speechx/examples/nnet/run.sh
0 → 100755
此差异已折叠。
speechx/examples/nnet/valgrind.sh
0 → 100755
此差异已折叠。
speechx/patch/CPPLINT.cfg
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
speechx/speechx/base/common.h
0 → 100644
此差异已折叠。
speechx/speechx/base/flags.h
0 → 100644
此差异已折叠。
speechx/speechx/base/log.h
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
speechx/speechx/decoder/common.h
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
speechx/speechx/frontend/fbank.h
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
speechx/speechx/frontend/mfcc.h
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
speechx/speechx/frontend/window.h
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
speechx/speechx/kaldi/feat/cmvn.h
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
speechx/speechx/nnet/decodable.cc
0 → 100644
此差异已折叠。
speechx/speechx/nnet/decodable.h
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
speechx/tools/setup_valgrind.sh
0 → 100755
此差异已折叠。