@@ -13,7 +13,7 @@ In this demo, you will learn how to build an audio retrieval system to retrieve

Note:this demo uses the [CN-Celeb](http://openslr.org/82/) dataset of at least 650,000 audio entries and 3000 speakers to build the audio vector library, which is then retrieved using a preset distance calculation. The dataset can also use other, Adjust as needed, e.g. Librispeech, VoxCeleb, UrbanSound, etc
Note:this demo uses the [CN-Celeb](http://openslr.org/82/) dataset of at least 650,000 audio entries and 3000 speakers to build the audio vector library, which is then retrieved using a preset distance calculation. The dataset can also use other, Adjust as needed, e.g. Librispeech, VoxCeleb, UrbanSound, GloVe, MNIST, etc
## Usage
### 1. Prepare MySQL and Milvus services by docker-compose
...
...
@@ -146,14 +146,14 @@ Then to start the system server, and it provides HTTP backend services.
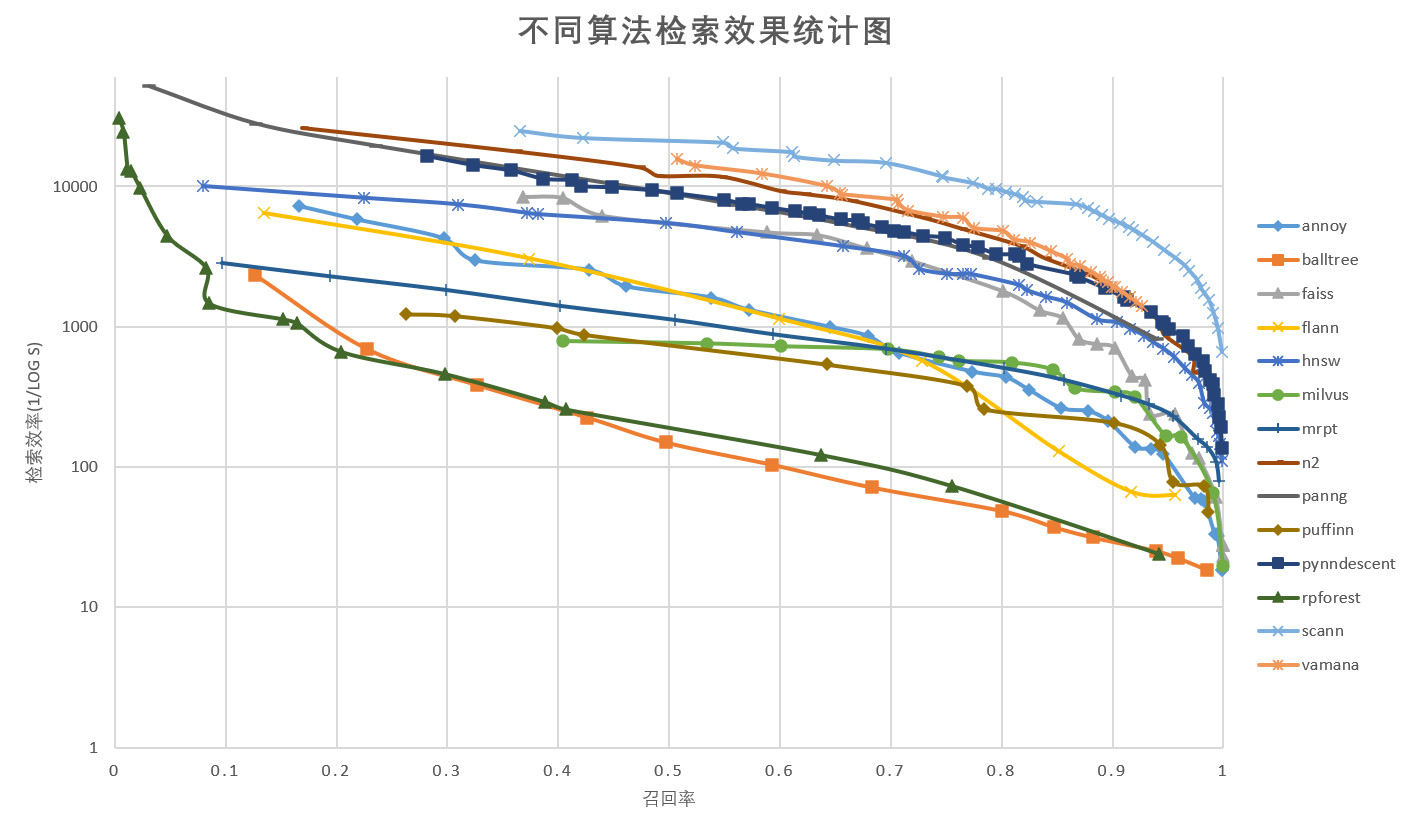
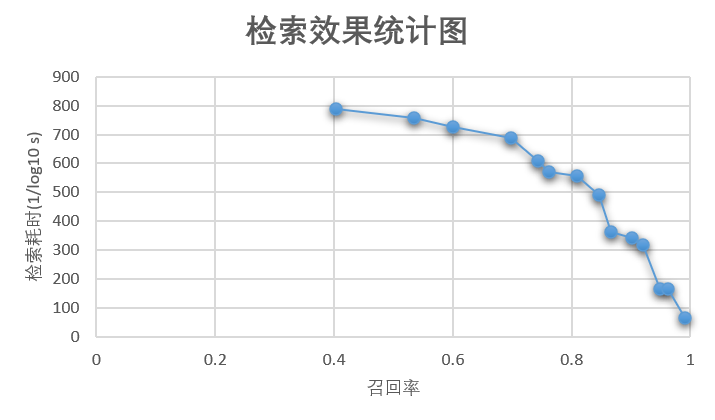
recall and elapsed time statistics are shown in the following figure:

Compared with other algorithms, the retrieval framework based on Milvus ranks in the middle in terms of speed and performance. Under the premise of 90% recall rate, the retrieval time is about 2.9 milliseconds, which can meet most application scenarios
The retrieval framework based on Milvus takes about 2.9 milliseconds to retrieve on the premise of 90% recall rate, and it takes about 500 milliseconds for feature extraction (testing audio takes about 5 seconds), that is, a single audio test takes about 503 milliseconds in total, which can meet most application scenarios
{kind=link}
{kind=link}