updated interface to use Blocks
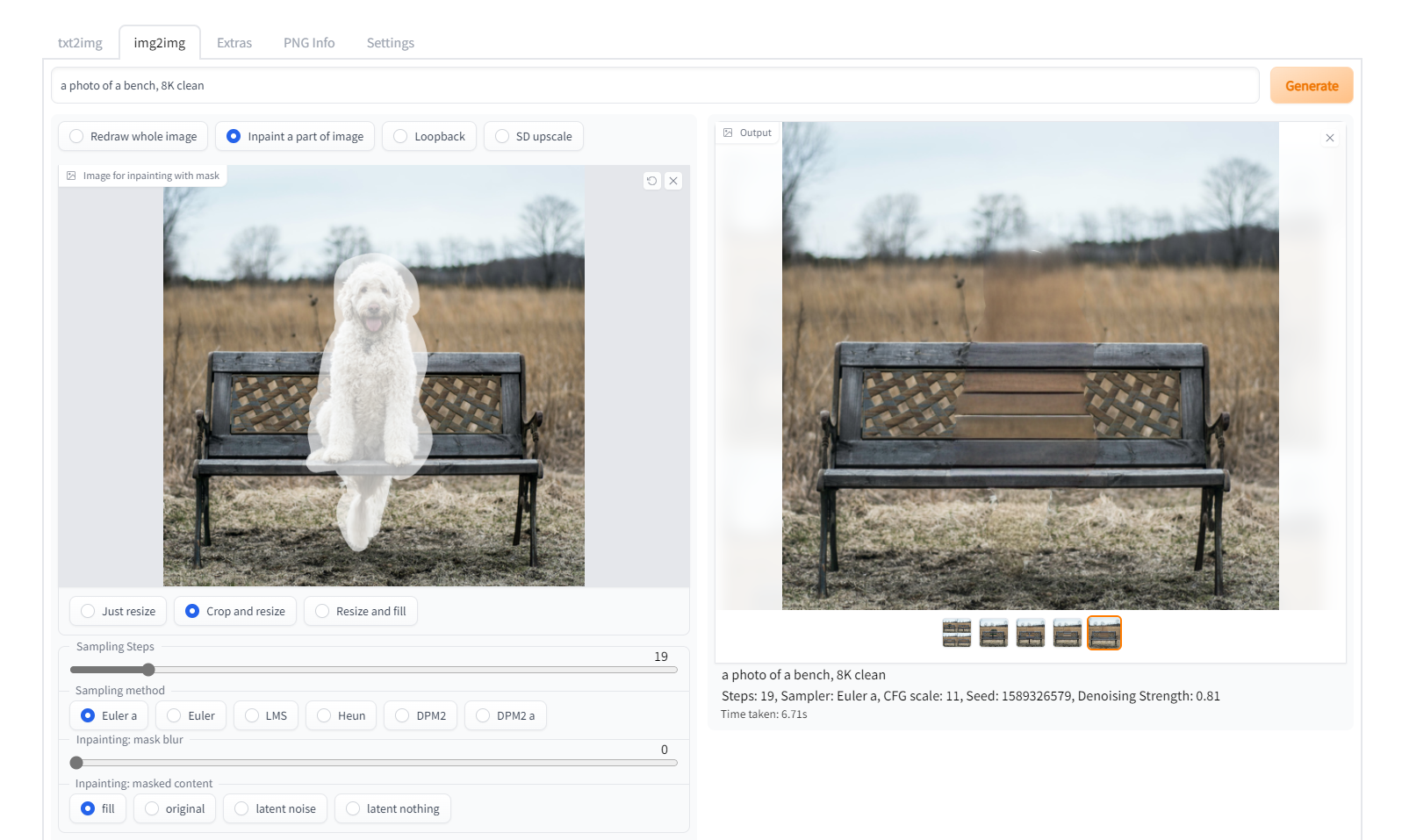
added mode toggle for img2img added inpainting to readme
Showing
images/inpainting.png
0 → 100644
{kind=link}
1.3 MB
{kind=link}
{kind=link}
| W: | H:
| W: | H:
style.css
0 → 100644
added mode toggle for img2img added inpainting to readme
1.3 MB
| W: | H:
| W: | H: