Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
openvinotoolkit
mmaction2
提交
31843475
M
mmaction2
项目概览
openvinotoolkit
/
mmaction2
10 个月 前同步成功
通知
2
Star
5
Fork
3
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
0
列表
看板
标记
里程碑
合并请求
0
DevOps
流水线
流水线任务
计划
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
M
mmaction2
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
0
Issue
0
列表
看板
标记
里程碑
合并请求
0
合并请求
0
Pages
DevOps
DevOps
流水线
流水线任务
计划
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
流水线任务
提交
Issue看板
前往新版Gitcode,体验更适合开发者的 AI 搜索 >>
提交
31843475
编写于
6月 23, 2020
作者:
L
linjintao
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
Move doc pictures to imgs dir
上级
b9f9b661
变更
6
隐藏空白更改
内联
并排
Showing
6 changed file
with
4 addition
and
4 deletion
+4
-4
docs/GETTING_STARTED.md
docs/GETTING_STARTED.md
+1
-1
docs/TECHNICAL_DETAILS.md
docs/TECHNICAL_DETAILS.md
+1
-1
docs/datapipeline.png
docs/datapipeline.png
+0
-0
docs/imgs/acc_curve.png
docs/imgs/acc_curve.png
+0
-0
docs/imgs/data_pipeline.png
docs/imgs/data_pipeline.png
+0
-0
docs/tutorials/data_pipeline.md
docs/tutorials/data_pipeline.md
+2
-2
未找到文件。
docs/GETTING_STARTED.md
浏览文件 @
31843475
...
...
@@ -242,7 +242,7 @@ We provide lots of useful tools under `tools/` directory.
You can plot loss/top-k acc curves given a training log file. Run
`pip install seaborn`
first to install the dependency.


```
shell
python tools/analyze_logs.py plot_curve
${
JSON_LOGS
}
[
--keys
${
KEYS
}
]
[
--title
${
TITLE
}
]
[
--legend
${
LEGEND
}
]
[
--backend
${
BACKEND
}
]
[
--style
${
STYLE
}
]
[
--out
${
OUT_FILE
}
]
...
...
docs/TECHNICAL_DETAILS.md
浏览文件 @
31843475
...
...
@@ -21,7 +21,7 @@ Each operation takes a dict as input and also output a dict for the next transfo
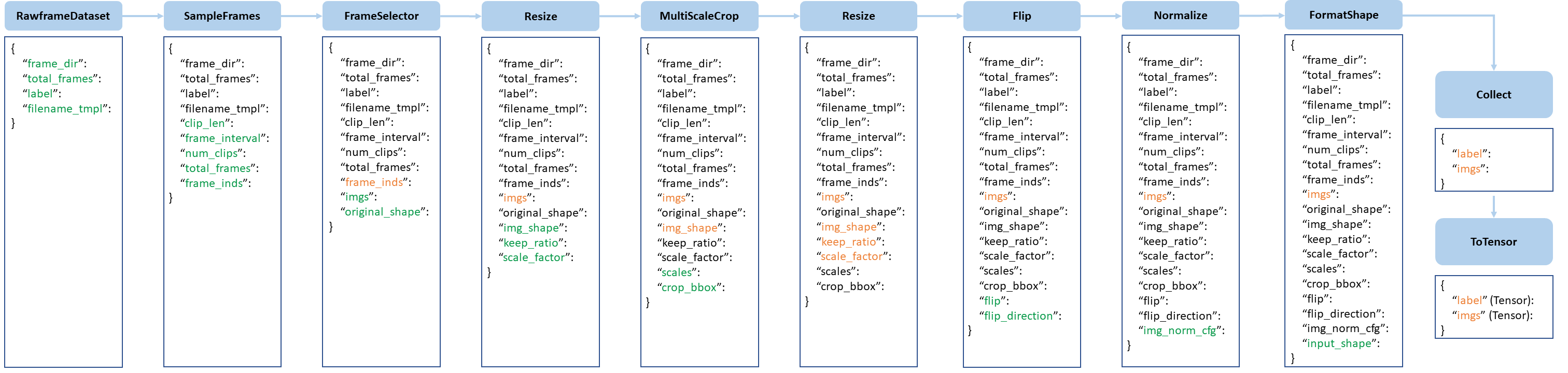
A typical pipeline is shown in the following figure.
With the pipeline going on, each operator can add new keys (marked as green) to the result dict or update the existing keys (marked as orange).


The operations are categorized into data loading, pre-processing, formatting.
...
...
docs/datapipeline.png
已删除
100644 → 0
浏览文件 @
b9f9b661
114.6 KB
docs/acc_curve.png
→
docs/
imgs/
acc_curve.png
浏览文件 @
31843475
文件已移动
docs/
tutorial
s/data_pipeline.png
→
docs/
img
s/data_pipeline.png
浏览文件 @
31843475
文件已移动
docs/tutorials/data_pipeline.md
浏览文件 @
31843475
...
...
@@ -13,9 +13,9 @@ The data preparation pipeline and the dataset is decomposed. Usually a dataset
defines how to process the annotations and a data pipeline defines all the steps to prepare a data dict.
A pipeline consists of a sequence of operations. Each operation takes a dict as input and also output a dict for the next operation.
We present a typical pipeline in the following figure. The blue blocks are pipeline operations.
We present a typical pipeline in the following figure. The blue blocks are pipeline operations.
With the pipeline going on, each operator can add new keys (marked as green) to the result dict or update the existing keys (marked as orange).


The operations are categorized into data loading, pre-processing and formatting.
...
...
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}
{kind=link}
{kind=link}