Initial commit
上级
Showing
.gitignore
0 → 100644
.pre-commit-config.yaml
0 → 100644
LICENSE
0 → 100644
此差异已折叠。
README.md
0 → 100644
README_cn.md
0 → 100644
assets/banner-YOLO.png
0 → 100644
{kind=link}

190.7 KB
assets/image3.jpg
0 → 100644
{kind=link}

135.6 KB
assets/picture.png
0 → 100644
{kind=link}
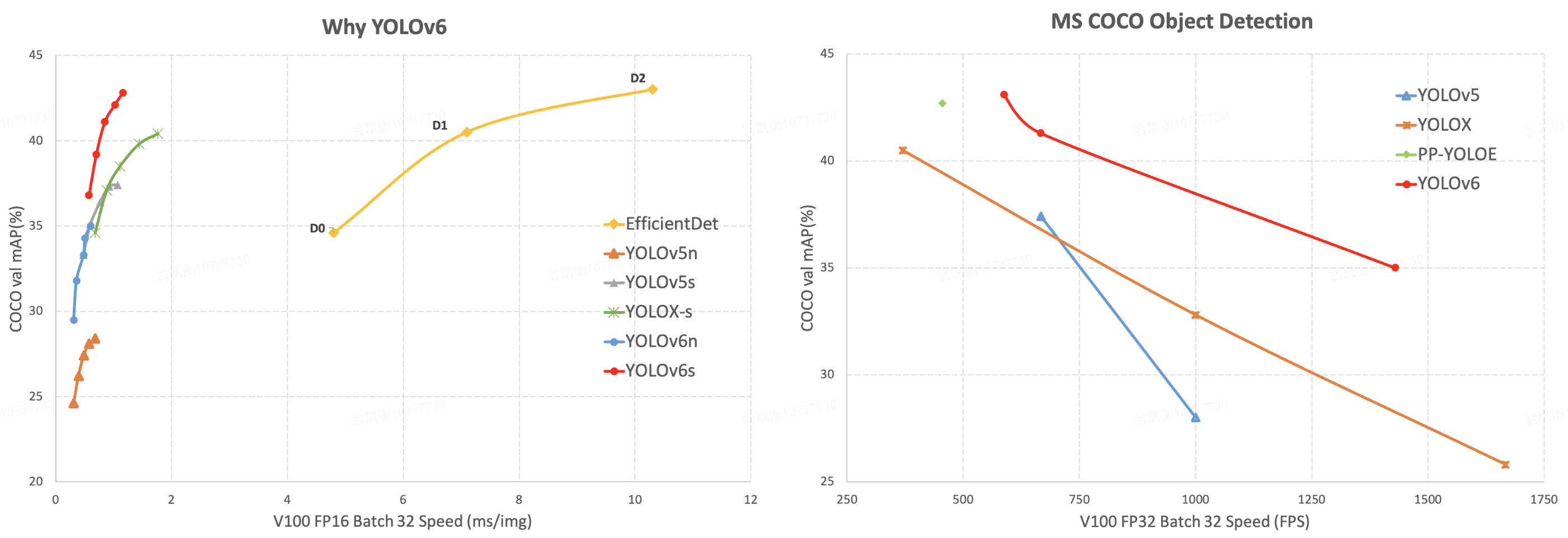
516.6 KB
assets/speed_comparision_v2.png
0 → 100644
{kind=link}
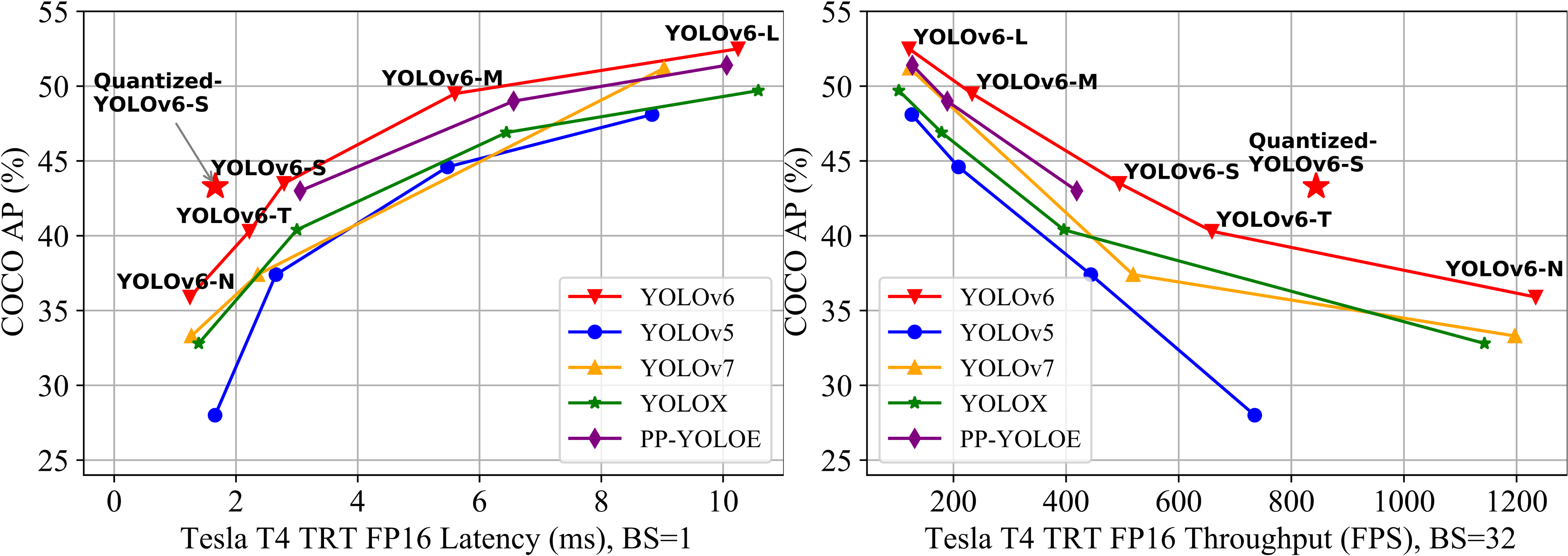
926.1 KB
assets/speed_comparision_v3.png
0 → 100644
{kind=link}
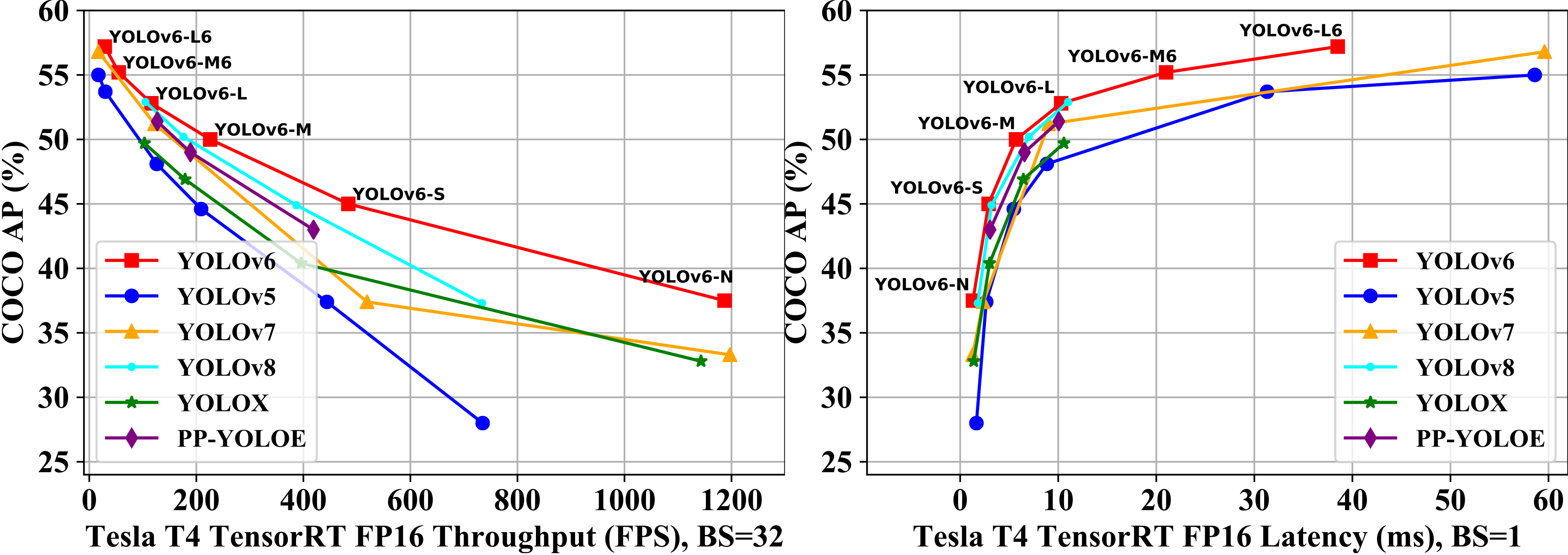
500.4 KB
assets/train_batch.jpg
0 → 100644
{kind=link}
1.0 MB
assets/voc_loss_curve.jpg
0 → 100644
{kind=link}

325.6 KB
assets/wechat_qrcode.png
0 → 100644
{kind=link}

214.7 KB
assets/yolov5s.jpg
0 → 100644
{kind=link}
517.6 KB
assets/yolov6s.jpg
0 → 100644
{kind=link}
511.5 KB
assets/yoloxs.jpg
0 → 100644
{kind=link}
526.1 KB
configs/base/README.md
0 → 100644
configs/base/README_cn.md
0 → 100644
configs/base/yolov6l_base.py
0 → 100644
configs/base/yolov6m_base.py
0 → 100644
configs/base/yolov6n_base.py
0 → 100644
configs/base/yolov6s_base.py
0 → 100644
configs/experiment/yolov6t.py
0 → 100644
configs/repopt/yolov6_tiny_hs.py
0 → 100644
configs/repopt/yolov6_tiny_opt.py
0 → 100644
configs/repopt/yolov6n_hs.py
0 → 100644
configs/repopt/yolov6n_opt.py
0 → 100644
configs/repopt/yolov6n_opt_qat.py
0 → 100644
configs/repopt/yolov6s_hs.py
0 → 100644
configs/repopt/yolov6s_opt.py
0 → 100644
configs/repopt/yolov6s_opt_qat.py
0 → 100644
configs/yolov6l.py
0 → 100644
configs/yolov6l6.py
0 → 100644
configs/yolov6l6_finetune.py
0 → 100644
configs/yolov6l_finetune.py
0 → 100644
configs/yolov6m.py
0 → 100644
configs/yolov6m6.py
0 → 100644
configs/yolov6m6_finetune.py
0 → 100644
configs/yolov6m_finetune.py
0 → 100644
configs/yolov6n.py
0 → 100644
configs/yolov6n6.py
0 → 100644
configs/yolov6n6_finetune.py
0 → 100644
configs/yolov6n_finetune.py
0 → 100644
configs/yolov6s.py
0 → 100644
configs/yolov6s6.py
0 → 100644
configs/yolov6s6_finetune.py
0 → 100644
configs/yolov6s_finetune.py
0 → 100644
data/coco.yaml
0 → 100644
data/dataset.yaml
0 → 100644
data/images/image1.jpg
0 → 100644
{kind=link}

78.8 KB
data/images/image2.jpg
0 → 100644
{kind=link}

140.3 KB
data/images/image3.jpg
0 → 100644
{kind=link}

114.9 KB
data/test1.yaml
0 → 100644
data/test1/images/.train.json
0 → 100644
此差异已折叠。
data/test1/images/.val.json
0 → 100644
{kind=link}

315.7 KB
{kind=link}

444.4 KB
{kind=link}

444.3 KB
{kind=link}

451.9 KB
{kind=link}

439.3 KB
{kind=link}

425.4 KB
{kind=link}
329.6 KB
{kind=link}

453.6 KB
{kind=link}

451.4 KB
{kind=link}

466.7 KB
{kind=link}

396.5 KB
{kind=link}

419.0 KB
{kind=link}

448.4 KB
{kind=link}

463.1 KB
{kind=link}

447.2 KB
{kind=link}

422.3 KB
{kind=link}

334.3 KB
{kind=link}

387.3 KB
{kind=link}

371.7 KB
{kind=link}

253.9 KB
{kind=link}

290.0 KB
{kind=link}

318.9 KB
{kind=link}

362.8 KB
{kind=link}

366.1 KB
{kind=link}

365.7 KB
{kind=link}

253.1 KB
{kind=link}

255.5 KB
{kind=link}

249.2 KB
{kind=link}

311.0 KB
{kind=link}

303.0 KB
{kind=link}

296.4 KB
{kind=link}

308.8 KB
{kind=link}

272.0 KB
{kind=link}

255.4 KB
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
data/voc.yaml
0 → 100644
此差异已折叠。
deploy/ONNX/OpenCV/README.md
0 → 100644
此差异已折叠。
deploy/ONNX/OpenCV/coco.names
0 → 100644
此差异已折叠。
deploy/ONNX/OpenCV/sample.jpg
0 → 100644
{kind=link}
此差异已折叠。
deploy/ONNX/OpenCV/yolo.py
0 → 100644
此差异已折叠。
deploy/ONNX/OpenCV/yolo_video.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
deploy/ONNX/OpenCV/yolox.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
deploy/ONNX/README.md
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
deploy/ONNX/eval_trt.py
0 → 100644
此差异已折叠。
deploy/ONNX/export_onnx.py
0 → 100644
此差异已折叠。
deploy/OpenVINO/README.md
0 → 100644
此差异已折叠。
此差异已折叠。
deploy/TensorRT/CMakeLists.txt
0 → 100644
此差异已折叠。
deploy/TensorRT/Processor.py
0 → 100644
此差异已折叠。
deploy/TensorRT/README.md
0 → 100644
此差异已折叠。
deploy/TensorRT/calibrator.py
0 → 100644
此差异已折叠。
deploy/TensorRT/eval_yolo_trt.py
0 → 100644
此差异已折叠。
deploy/TensorRT/logging.h
0 → 100644
此差异已折叠。
deploy/TensorRT/onnx_to_trt.py
0 → 100644
此差异已折叠。
deploy/TensorRT/visualize.py
0 → 100644
此差异已折叠。
deploy/TensorRT/yolov6.cpp
0 → 100644
此差异已折叠。
docs/Test_speed.md
0 → 100644
此差异已折叠。
docs/Train_coco_data.md
0 → 100644
此差异已折叠。
docs/Train_custom_data.md
0 → 100644
此差异已折叠。
docs/Tutorial of Quantization.md
0 → 100644
此差异已折叠。
docs/tutorial_repopt.md
0 → 100644
此差异已折叠。
docs/tutorial_voc.ipynb
0 → 100644
此差异已折叠。
eval.py
0 → 100644
此差异已折叠。
infer.py
0 → 100644
此差异已折叠。
inference.ipynb
0 → 100644
此差异已折叠。
mytrain/dataseg.py
0 → 100644
此差异已折叠。
mytrain/images/garb01_001.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_002.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_003.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_004.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_005.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_006.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_007.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_008.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_009.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_010.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_011.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_012.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_013.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_014.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_015.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_016.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_017.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_018.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_019.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_020.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_021.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_022.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_023.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_024.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_025.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_026.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_027.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_028.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_029.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_030.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_031.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_032.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_033.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_034.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_035.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_036.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_037.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_038.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_039.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_040.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_041.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_042.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_043.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_044.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_045.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_046.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_047.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_048.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_049.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_050.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_051.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_052.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_053.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_054.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_055.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_056.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_057.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_058.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_059.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_060.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_061.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_062.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_063.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_064.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_065.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_066.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_067.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_068.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_069.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_070.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_071.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_072.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_073.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_074.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_075.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_076.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_077.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_078.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_079.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_080.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_081.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_082.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_083.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_084.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_085.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_086.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_087.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_088.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_089.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_090.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_091.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_092.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_093.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_094.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_095.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_096.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_097.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_098.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_099.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_100.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_101.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_102.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_103.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_104.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_105.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_106.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_107.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_108.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_109.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_110.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_111.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_112.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_113.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_114.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_115.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_116.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_117.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_118.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_119.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_120.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_121.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_122.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_123.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_124.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_125.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_126.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_127.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_128.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_129.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_130.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_131.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_132.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_133.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_134.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_135.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_136.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_137.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_139.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_140.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_141.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_142.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_143.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_144.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_145.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_146.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_147.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_148.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_149.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_150.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/images/garb01_151.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/labels/garb01_001.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_002.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_003.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_004.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_005.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_006.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_007.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_008.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_009.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_010.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_011.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_012.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_013.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_014.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_015.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_016.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_017.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_018.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_019.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_020.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_021.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_022.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_023.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_024.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_025.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_026.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_027.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_028.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_029.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_030.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_031.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_032.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_033.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_034.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_035.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_036.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_037.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_038.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_039.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_040.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_041.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_042.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_043.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_044.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_045.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_046.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_047.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_048.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_049.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_050.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_051.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_052.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_053.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_054.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_055.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_056.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_057.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_058.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_059.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_060.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_061.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_062.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_063.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_064.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_065.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_066.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_067.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_068.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_069.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_070.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_071.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_072.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_073.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_074.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_075.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_076.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_077.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_078.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_079.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_080.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_081.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_082.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_083.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_084.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_085.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_086.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_087.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_088.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_089.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_090.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_091.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_092.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_093.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_094.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_095.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_096.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_097.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_098.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_099.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_100.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_101.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_102.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_103.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_104.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_105.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_106.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_107.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_108.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_109.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_110.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_111.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_112.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_113.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_114.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_115.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_116.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_117.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_118.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_119.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_120.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_121.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_122.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_123.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_124.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_125.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_126.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_127.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_128.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_129.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_130.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_131.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_132.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_133.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_134.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_135.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_136.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_137.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_139.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_140.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_141.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_142.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_143.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_144.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_145.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_146.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_147.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_148.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_149.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_150.txt
0 → 100644
此差异已折叠。
mytrain/labels/garb01_151.txt
0 → 100644
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
mytrain/val/images/garb01_145.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/val/images/garb01_146.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/val/images/garb01_147.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/val/images/garb01_148.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/val/images/garb01_149.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/val/images/garb01_150.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/val/images/garb01_151.jpg
0 → 100644
{kind=link}
此差异已折叠。
mytrain/val/labels/garb01_145.txt
0 → 100644
此差异已折叠。
mytrain/val/labels/garb01_146.txt
0 → 100644
此差异已折叠。