Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
OpenHarmony
Docs
提交
cb0d6c63
D
Docs
项目概览
OpenHarmony
/
Docs
大约 2 年 前同步成功
通知
161
Star
293
Fork
28
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
0
列表
看板
标记
里程碑
合并请求
0
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
D
Docs
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
0
Issue
0
列表
看板
标记
里程碑
合并请求
0
合并请求
0
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
提交
cb0d6c63
编写于
7月 20, 2023
作者:
G
ge-yafang
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
update docs
Signed-off-by:
N
ge-yafang
<
geyafang@huawei.com
>
上级
7406f02c
变更
25
隐藏空白更改
内联
并排
Showing
25 changed file
with
1841 addition
and
1 deletion
+1841
-1
zh-cn/application-dev/Readme-CN.md
zh-cn/application-dev/Readme-CN.md
+1
-0
zh-cn/application-dev/application-dev-guide-for-gitee.md
zh-cn/application-dev/application-dev-guide-for-gitee.md
+2
-1
zh-cn/application-dev/application-dev-guide.md
zh-cn/application-dev/application-dev-guide.md
+1
-0
zh-cn/application-dev/arkts-uitls/Readme-CN.md
zh-cn/application-dev/arkts-uitls/Readme-CN.md
+23
-0
zh-cn/application-dev/arkts-uitls/arkts-commonlibrary-overview.md
...plication-dev/arkts-uitls/arkts-commonlibrary-overview.md
+39
-0
zh-cn/application-dev/arkts-uitls/async-concurrency-overview.md
...application-dev/arkts-uitls/async-concurrency-overview.md
+87
-0
zh-cn/application-dev/arkts-uitls/concurrency-overview.md
zh-cn/application-dev/arkts-uitls/concurrency-overview.md
+20
-0
zh-cn/application-dev/arkts-uitls/container-overview.md
zh-cn/application-dev/arkts-uitls/container-overview.md
+10
-0
zh-cn/application-dev/arkts-uitls/cpu-intensive-task-development.md
...ication-dev/arkts-uitls/cpu-intensive-task-development.md
+190
-0
zh-cn/application-dev/arkts-uitls/figures/arkts-commonlibrary.png
...plication-dev/arkts-uitls/figures/arkts-commonlibrary.png
+0
-0
zh-cn/application-dev/arkts-uitls/figures/newWorker.png
zh-cn/application-dev/arkts-uitls/figures/newWorker.png
+0
-0
zh-cn/application-dev/arkts-uitls/figures/taskpool.png
zh-cn/application-dev/arkts-uitls/figures/taskpool.png
+0
-0
zh-cn/application-dev/arkts-uitls/figures/worker.png
zh-cn/application-dev/arkts-uitls/figures/worker.png
+0
-0
zh-cn/application-dev/arkts-uitls/io-intensive-task-development.md
...lication-dev/arkts-uitls/io-intensive-task-development.md
+51
-0
zh-cn/application-dev/arkts-uitls/linear-container.md
zh-cn/application-dev/arkts-uitls/linear-container.md
+253
-0
zh-cn/application-dev/arkts-uitls/multi-thread-concurrency-overview.md
...tion-dev/arkts-uitls/multi-thread-concurrency-overview.md
+60
-0
zh-cn/application-dev/arkts-uitls/nonlinear-container.md
zh-cn/application-dev/arkts-uitls/nonlinear-container.md
+253
-0
zh-cn/application-dev/arkts-uitls/single-io-development.md
zh-cn/application-dev/arkts-uitls/single-io-development.md
+29
-0
zh-cn/application-dev/arkts-uitls/sync-task-development.md
zh-cn/application-dev/arkts-uitls/sync-task-development.md
+171
-0
zh-cn/application-dev/arkts-uitls/taskpool-vs-worker.md
zh-cn/application-dev/arkts-uitls/taskpool-vs-worker.md
+165
-0
zh-cn/application-dev/arkts-uitls/xml-conversion.md
zh-cn/application-dev/arkts-uitls/xml-conversion.md
+92
-0
zh-cn/application-dev/arkts-uitls/xml-generation.md
zh-cn/application-dev/arkts-uitls/xml-generation.md
+80
-0
zh-cn/application-dev/arkts-uitls/xml-overview.md
zh-cn/application-dev/arkts-uitls/xml-overview.md
+23
-0
zh-cn/application-dev/arkts-uitls/xml-parsing.md
zh-cn/application-dev/arkts-uitls/xml-parsing.md
+270
-0
zh-cn/application-dev/website.md
zh-cn/application-dev/website.md
+21
-0
未找到文件。
zh-cn/application-dev/Readme-CN.md
浏览文件 @
cb0d6c63
...
@@ -78,6 +78,7 @@
...
@@ -78,6 +78,7 @@
-
开发
-
开发
-
[
应用模型
](
application-models/Readme-CN.md
)
-
[
应用模型
](
application-models/Readme-CN.md
)
-
[
UI开发
](
ui/Readme-CN.md
)
-
[
UI开发
](
ui/Readme-CN.md
)
-
[
ArkTS语言基础类库
](
arkts-utils/Readme-CN.md
)
-
[
Web
](
web/Readme-CN.md
)
-
[
Web
](
web/Readme-CN.md
)
-
[
通知
](
notification/Readme-CN.md
)
-
[
通知
](
notification/Readme-CN.md
)
-
[
窗口管理
](
windowmanager/Readme-CN.md
)
-
[
窗口管理
](
windowmanager/Readme-CN.md
)
...
...
zh-cn/application-dev/application-dev-guide-for-gitee.md
浏览文件 @
cb0d6c63
...
@@ -25,7 +25,8 @@
...
@@ -25,7 +25,8 @@
在此基础上,还提供了如下功能的开发指导:
在此基础上,还提供了如下功能的开发指导:
-
[
Web
](
web/web-component-overview.md
)
-
[
ArkTS语言基础类库
](
arkts-utils/Readme-CN.md
)
-
[
Web
](
web/Readme-CN.md
)
-
[
通知
](
notification/Readme-CN.md
)
-
[
通知
](
notification/Readme-CN.md
)
-
[
窗口管理
](
windowmanager/Readme-CN.md
)
-
[
窗口管理
](
windowmanager/Readme-CN.md
)
-
[
WebGL
](
webgl/Readme-CN.md
)
-
[
WebGL
](
webgl/Readme-CN.md
)
...
...
zh-cn/application-dev/application-dev-guide.md
浏览文件 @
cb0d6c63
...
@@ -25,6 +25,7 @@
...
@@ -25,6 +25,7 @@
在此基础上,还提供了如下功能的开发指导:
在此基础上,还提供了如下功能的开发指导:
-
[
ArkTS语言基础类库
](
arkts-utils/arkts-commonlibrary-overview.md
)
-
[
Web
](
web/web-component-overview.md
)
-
[
Web
](
web/web-component-overview.md
)
-
[
通知
](
notification/notification-overview.md
)
-
[
通知
](
notification/notification-overview.md
)
-
[
窗口管理
](
windowmanager/window-overview.md
)
-
[
窗口管理
](
windowmanager/window-overview.md
)
...
...
zh-cn/application-dev/arkts-uitls/Readme-CN.md
0 → 100644
浏览文件 @
cb0d6c63
# ArkTS语言基础类库
-
[
ArkTS语言基础类库概述
](
arkts-commonlibrary-overview.md
)
-
并发
-
[
并发概述
](
concurrency-overview.md
)
-
使用异步并发能力进行开发
-
[
异步并发概述
](
async-concurrency-overview.md
)
-
[
单次I/O任务开发指导
](
single-io-development.md
)
-
使用多线程并发能力进行开发
-
[
多线程并发概述
](
multi-thread-concurrency-overview.md
)
-
[
TaskPool和Worker的对比
](
taskpool-vs-worker.md
)
-
[
CPU密集型任务开发指导
](
cpu-intensive-task-development.md
)
-
[
I/O密集型任务开发指导
](
io-intensive-task-development.md
)
-
[
同步任务开发指导
](
sync-task-development.md
)
-
容器类库
-
[
容器类库概述
](
container-overview.md
)
-
[
线性容器
](
linear-container.md
)
-
[
非线性容器
](
nonlinear-container.md
)
-
XML生成、解析与转换
-
[
XML概述
](
xml-overview.md
)
-
[
XML生成
](
xml-generation.md
)
-
[
XML解析
](
xml-parsing.md
)
-
[
XML转换
](
xml-conversion.md
)
zh-cn/application-dev/arkts-uitls/arkts-commonlibrary-overview.md
0 → 100644
浏览文件 @
cb0d6c63
# ArkTS语言基础类库概述
ArkTS语言基础类库是OpenHarmony系统上为应用开发者提供的常用基础能力,主要包含能力如下图所示。
**图1**
ArkTS语言基础类库能力示意图

-
提供
[
异步并发和多线程并发
](
concurrency-overview.md
)
的能力。
-
支持Promise和async/await等标准的JS异步并发能力。
-
TaskPool为应用程序提供一个多线程的运行环境,降低整体资源的消耗、提高系统的整体性能,开发者无需关心线程实例的生命周期。
-
Worker支持多线程并发,支持Worker线程和宿主线程之间进行通信,开发者需要主动创建和关闭Worker线程。
-
提供常见的
[
容器类库增、删、改、查
](
container-overview.md
)
的能力。
-
提供XML、URL、URI构造和解析的能力。
-
XML被设计用来传输和存储数据,是一种可扩展标记语言。语言基础类库提供了
[
XML生成、解析与转换
](
xml-overview.md
)
的能力。
-
URL、URI构造和解析能力:其中
[
URI
](
../reference/apis/js-apis-uri.md
)
是统一资源标识符,可以唯一标识一个资源。
[
URL
](
../reference/apis/js-apis-url.md
)
为统一资源定位符,可以提供找到该资源的路径。
-
提供常见的
[
字符串和二进制数据处理
](
../reference/apis/js-apis-util.md
)
的能力,以及
[
控制台打印
](
../reference/apis/js-apis-logs.md
)
的相关能力。
-
字符串编解码功能。
-
基于Base64的字节编码和解码功能。
-
提供常见的有理数操作支持,包括有理数的比较、获取分子分母等功能。
-
提供Scope接口用于描述一个字段的有效范围。
-
提供二进制数据处理的能力,常见于TCP流或文件系统操作等场景中用于处理二进制数据流。
-
console提供控制台打印的能力。
-
提供
[
获取进程信息和操作进程
](
../reference/apis/js-apis-process.md
)
的能力。
## 相关实例
针对语言基础类库的开发,有以下相关实例可供参考:
-
[
LanguageBaseClassLibrary:语言基础类库
](
https://gitee.com/openharmony/applications_app_samples/tree/master/code/LaunguageBaseClassLibrary/LanguageBaseClassLibrary
)
zh-cn/application-dev/arkts-uitls/async-concurrency-overview.md
0 → 100644
浏览文件 @
cb0d6c63
# 异步并发概述
Promise和async/await提供异步并发能力,是标准的JS异步语法。异步代码会被挂起并在之后继续执行,同一时间只有一段代码执行,适用于单次I/O任务的场景开发,例如一次网络请求、一次文件读写等操作。
异步语法是一种编程语言的特性,允许程序在执行某些操作时不必等待其完成,而是可以继续执行其他操作。
## Promise
Promise是一种用于处理异步操作的对象,可以将异步操作转换为类似于同步操作的风格,以方便代码编写和维护。Promise提供了一个状态机制来管理异步操作的不同阶段,并提供了一些方法来注册回调函数以处理异步操作的成功或失败的结果。
Promise有三种状态:pending(进行中)、fulfilled(已完成)和rejected(已拒绝)。Promise对象创建后处于pending状态,并在异步操作完成后转换为fulfilled或rejected状态。
最基本的用法是通过构造函数实例化一个Promise对象,同时传入一个带有两个参数的函数,通常称为executor函数。executor函数接收两个参数:resolve和reject,分别表示异步操作成功和失败时的回调函数。例如,以下代码创建了一个Promise对象并模拟了一个异步操作:
```
js
const
promise
=
new
Promise
((
resolve
,
reject
)
=>
{
setTimeout
(()
=>
{
const
randomNumber
=
Math
.
random
();
if
(
randomNumber
>
0.5
)
{
resolve
(
randomNumber
);
}
else
{
reject
(
new
Error
(
'
Random number is too small
'
));
}
},
1000
);
});
```
上述代码中,setTimeout函数模拟了一个异步操作,并在1秒钟后随机生成一个数字。如果随机数大于0.5,则执行resolve回调函数并将随机数作为参数传递;否则执行reject回调函数并传递一个错误对象作为参数。
Promise对象创建后,可以使用then方法和catch方法指定resolved状态和rejected状态的回调函数。then方法可接受两个参数,一个处理resolved状态的函数,另一个处理rejected状态的函数。只传一个参数则表示状态改变就执行,不区分状态结果。使用catch方法注册一个回调函数,用于处理“失败”的结果,即捕获Promise的状态改变为rejected状态或操作失败抛出的异常。例如:
```
js
promise
.
then
(
result
=>
{
console
.
info
(
`Random number is
${
result
}
`
);
}).
catch
(
error
=>
{
console
.
error
(
error
.
message
);
});
```
上述代码中,then方法的回调函数接收Promise对象的成功结果作为参数,并将其输出到控制台上。如果Promise对象进入rejected状态,则catch方法的回调函数接收错误对象作为参数,并将其输出到控制台上。
## async/await
async/await是一种用于处理异步操作的Promise语法糖,使得编写异步代码变得更加简单和易读。通过使用async关键字声明一个函数为异步函数,并使用await关键字等待Promise的解析(完成或拒绝),以同步的方式编写异步操作的代码。
async函数是一个返回Promise对象的函数,用于表示一个异步操作。在async函数内部,可以使用await关键字等待一个Promise对象的解析,并返回其解析值。如果一个async函数抛出异常,那么该函数返回的Promise对象将被拒绝,并且异常信息会被传递给Promise对象的onRejected()方法。
下面是一个使用async/await的例子,其中模拟了一个异步操作,该操作会在3秒钟后返回一个字符串。
```
js
async
function
myAsyncFunction
()
{
const
result
=
await
new
Promise
((
resolve
)
=>
{
setTimeout
(()
=>
{
resolve
(
'
Hello, world!
'
);
},
3000
);
});
console
.
info
(
String
(
result
));
// 输出: Hello, world!
}
myAsyncFunction
();
```
在上述示例代码中,使用了await关键字来等待Promise对象的解析,并将其解析值存储在result变量中。
需要注意的是,由于要等待异步操作完成,因此需要将整个操作包在async函数中。除了在async函数中使用await外,还可以使用try/catch块来捕获异步操作中的异常。
```
js
async
function
myAsyncFunction
()
{
try
{
const
result
=
await
new
Promise
((
resolve
)
=>
{
resolve
(
'
Hello, world!
'
);
});
}
catch
(
e
)
{
console
.
error
(
`Get exception:
${
e
}
`
);
}
}
myAsyncFunction
();
```
zh-cn/application-dev/arkts-uitls/concurrency-overview.md
0 → 100644
浏览文件 @
cb0d6c63
# 并发概述
并发是指在同一时间段内,能够处理多个任务的能力。为了提升应用的响应速度与帧率,以及防止耗时任务对主线程的干扰,OpenHarmony系统提供了异步并发和多线程并发两种处理策略。
-
异步并发是指异步代码在执行到一定程度后会被暂停,以便在未来某个时间点继续执行,这种情况下,同一时间只有一段代码在执行。
-
多线程并发允许在同一时间段内同时执行多段代码。在主线程继续响应用户操作和更新UI的同时,后台也能执行耗时操作,从而避免应用出现卡顿。
并发能力在多种场景中都有应用,其中包括单次I/O任务、CPU密集型任务、I/O密集型任务和同步任务等。开发者可以根据不同的场景,需要选择相应的并发策略进行优化和开发。
ArkTS支持异步并发和多线程并发。
-
Promise和async/await提供异步并发能力,适用于单次I/O任务的开发场景。详细请参见
[
异步并发概述
](
async-concurrency-overview.md
)
。
-
TaskPool和Worker提供多线程并发能力,适用于CPU密集型任务、I/O密集型任务和同步任务等并发场景。详细请参见
[
多线程并发概述
](
multi-thread-concurrency-overview.md
)
。
zh-cn/application-dev/arkts-uitls/container-overview.md
0 → 100644
浏览文件 @
cb0d6c63
# 容器类库概述
容器类库,用于存储各种数据类型的元素,并具备一系列处理数据元素的方法。
在方舟开发框架中,容器类采用了类似静态语言的方式来实现,并通过napi框架对外提供,并通过对存储位置以及属性的限制,让每种类型的数据都能在完成自身功能的基础上去除冗余逻辑,保证了数据的高效访问,提升了应用的性能。
在方舟开发框架中,提供了线性和非线性两类容器类,共14种。每种容器都有自身的特性及使用场景,详情请见下文介绍。
zh-cn/application-dev/arkts-uitls/cpu-intensive-task-development.md
0 → 100644
浏览文件 @
cb0d6c63
# CPU密集型任务开发指导
CPU密集型任务是指需要占用系统资源处理大量计算能力的任务,需要长时间运行,这段时间会阻塞线程其它事件的处理,不适宜放在主线程进行。例如图像处理、视频编码、数据分析等。
基于多线程并发机制处理CPU密集型任务可以提高CPU利用率,提升应用程序响应速度。
当任务不需要长时间(3分钟)占据后台线程,而是一个个独立的任务时,推荐使用TaskPool,反之推荐使用Worker。接下来将以图像直方图处理以及后台长时间的模型预测任务分别进行举例。
## 使用TaskPool进行图像直方图处理
1.
实现图像处理的业务逻辑。
2.
数据分段,通过任务组发起关联任务调度。
创建
[
TaskGroup
](
../reference/apis/js-apis-taskpool.md#taskgroup10
)
并通过
[
addTask()
](
../reference/apis/js-apis-taskpool.md#addtask10
)
添加对应的任务,通过
[
execute()
](
../apis/js-apis-taskpool.md#taskpoolexecute10
)
执行任务组,并指定为
[
高优先级
](
../reference/apis/js-apis-taskpool.md#priority
)
,在当前任务组所有任务结束后,会将直方图处理结果同时返回。
3.
结果数组汇总处理。
```
ts
import
taskpool
from
'
@ohos.taskpool
'
;
@
Concurrent
function
imageProcessing
(
dataSlice
:
ArrayBuffer
)
{
// 步骤1: 具体的图像处理操作及其他耗时操作
return
dataSlice
;
}
function
histogramStatistic
(
pixelBuffer
:
ArrayBuffer
)
{
// 步骤2: 分成三段并发调度
let
number
=
pixelBuffer
.
byteLength
/
3
;
let
buffer1
=
pixelBuffer
.
slice
(
0
,
number
);
let
buffer2
=
pixelBuffer
.
slice
(
number
,
number
*
2
);
let
buffer3
=
pixelBuffer
.
slice
(
number
*
2
);
let
group
=
new
taskpool
.
TaskGroup
();
group
.
addTask
(
imageProcessing
,
buffer1
);
group
.
addTask
(
imageProcessing
,
buffer2
);
group
.
addTask
(
imageProcessing
,
buffer3
);
taskpool
.
execute
(
group
,
taskpool
.
Priority
.
HIGH
).
then
((
ret
:
ArrayBuffer
[])
=>
{
// 步骤3: 结果数组汇总处理
})
}
@
Entry
@
Component
struct
Index
{
@
State
message
:
string
=
'
Hello World
'
build
()
{
Row
()
{
Column
()
{
Text
(
this
.
message
)
.
fontSize
(
50
)
.
fontWeight
(
FontWeight
.
Bold
)
.
onClick
(()
=>
{
let
data
:
ArrayBuffer
;
histogramStatistic
(
data
);
})
}
.
width
(
'
100%
'
)
}
.
height
(
'
100%
'
)
}
}
```
## 使用Worker进行长时间数据分析
本文通过某地区提供的房价数据训练一个简易的房价预测模型,该模型支持通过输入房屋面积和房间数量去预测该区域的房价,模型需要长时间运行,房价预测需要使用前面的模型运行结果,因此需要使用Worker。
1.
DevEco Studio提供了Worker创建的模板,新建一个Worker线程,例如命名为“MyWorker”。
!
[
newWorker
](
figures/newWorker.png
)
2.
在主线程中通过调用
[
ThreadWorker()
](
../apis/js-apis-worker.md#threadworker9
)
方法创建Worker对象,当前线程为宿主线程。
```
js
import
worker
from
'
@ohos.worker
'
;
const
workerInstance
=
new
worker
.
ThreadWorker
(
'
entry/ets/workers/MyWorker.ts
'
);
```
3.
在宿主线程中通过调用
[
onmessage()
](
../apis/js-apis-worker.md#onmessage9
)
方法接收Worker线程发送过来的消息,以及通过调用
[
postMessage()
](
../apis/js-apis-worker.md#postmessage9
)
方法向Worker线程发送消息。
例如向Worker线程发送训练和预测的消息,同时接收Worker线程发送回来的消息。
```
js
// 接收Worker子线程的结果
workerInstance
.
onmessage
=
function
(
e
)
{
// data:主线程发送的信息
let
data
=
e
.
data
;
console
.
info
(
'
MyWorker.ts onmessage
'
);
// 在Worker线程中进行耗时操作
}
workerInstance
.
onerror
=
function
(
d
)
{
// 接收Worker子线程的错误信息
}
// 向Worker子线程发送训练消息
workerInstance
.
postMessage
({
'
type
'
:
0
});
// 向Worker子线程发送预测消息
workerInstance
.
postMessage
({
'
type
'
:
1
,
'
value
'
:
[
90
,
5
]
});
```
4.
在MyWorker.ts文件中绑定Worker对象,当前线程为Worker线程。
```
js
import
worker
,
{
ThreadWorkerGlobalScope
,
MessageEvents
,
ErrorEvent
}
from
'
@ohos.worker
'
;
let
workerPort
:
ThreadWorkerGlobalScope
=
worker
.
workerPort
;
```
5.
在Worker线程中通过调用
[
onmessage()
](
../apis/js-apis-worker.md#onmessage9-1
)
方法接收宿主线程发送的消息内容,以及通过调用
[
postMessage()
](
../apis/js-apis-worker.md#postmessage9-2
)
方法向宿主线程发送消息。
例如在Worker线程中定义预测模型及其训练过程,同时与主线程进行信息交互。
```
js
import
worker
,
{
ThreadWorkerGlobalScope
,
MessageEvents
,
ErrorEvent
}
from
'
@ohos.worker
'
;
let
workerPort
:
ThreadWorkerGlobalScope
=
worker
.
workerPort
;
// 定义训练模型及结果
let
result
;
// 定义预测函数
function
predict
(
x
)
{
return
result
[
x
];
}
// 定义优化器训练过程
function
optimize
()
{
result
=
{};
}
// Worker线程的onmessage逻辑
workerPort
.
onmessage
=
function
(
e
:
MessageEvents
)
{
let
data
=
e
.
data
// 根据传输的数据的type选择进行操作
switch
(
data
.
type
)
{
case
0
:
// 进行训练
optimize
();
// 训练之后发送主线程训练成功的消息
workerPort
.
postMessage
({
type
:
'
message
'
,
value
:
'
train success.
'
});
break
;
case
1
:
// 执行预测
const
output
=
predict
(
data
.
value
);
// 发送主线程预测的结果
workerPort
.
postMessage
({
type
:
'
predict
'
,
value
:
output
});
break
;
default
:
workerPort
.
postMessage
({
type
:
'
message
'
,
value
:
'
send message is invalid
'
});
break
;
}
}
```
6.
在Worker线程中完成任务之后,执行Worker线程销毁操作。根据需要可以在宿主线程中对Worker线程进行销毁,也可以在Worker线程中主动销毁Worker线程。
在宿主线程中通过调用
[
onexit()
](
../apis/js-apis-worker.md#onexit9
)
方法定义Worker现成销毁后的处理逻辑。
```
js
// Worker线程销毁后,执行onexit回调方法
workerInstance
.
onexit
=
function
()
{
console
.
info
(
"
main thread terminate
"
);
}
```
在宿主线程中通过调用
[
terminate()
](
../apis/js-apis-worker.md#terminate9
)
方法销毁Worker线程,并终止Worker接收消息。
```
js
// 销毁Worker线程
workerInstance
.
terminate
();
```
在Worker线程中通过调用[close()](../apis/js-apis-worker.md#close9)方法主动销毁Worker线程,并终止Worker接收消息。
```
js
// 销毁线程
workerPort
.
close
();
```
zh-cn/application-dev/arkts-uitls/figures/arkts-commonlibrary.png
0 → 100644
浏览文件 @
cb0d6c63
69.7 KB
zh-cn/application-dev/arkts-uitls/figures/newWorker.png
0 → 100644
浏览文件 @
cb0d6c63
148.2 KB
zh-cn/application-dev/arkts-uitls/figures/taskpool.png
0 → 100644
浏览文件 @
cb0d6c63
32.5 KB
zh-cn/application-dev/arkts-uitls/figures/worker.png
0 → 100644
浏览文件 @
cb0d6c63
27.3 KB
zh-cn/application-dev/arkts-uitls/io-intensive-task-development.md
0 → 100644
浏览文件 @
cb0d6c63
# I/O密集型任务开发指导
使用异步并发可以解决单次I/O任务阻塞的问题,但是如果遇到I/O密集型任务,同样会阻塞线程中其它任务的执行,这时需要使用多线程并发能力来进行解决。
I/O密集型任务的性能重点通常不在于CPU的处理能力,而在于I/O操作的速度和效率。这种任务通常需要频繁地进行磁盘读写、网络通信等操作。此处以频繁读写系统文件来模拟I/O密集型并发任务的处理。
1.
定义并发函数,内部密集调用I/O能力。
```
ts
import
fs
from
'
@ohos.file.fs
'
;
// 定义并发函数,内部密集调用I/O能力
@
Concurrent
async
function
concurrentTest
(
fileList
:
string
[])
{
// 写入文件的实现
async
function
write
(
data
,
filePath
)
{
let
file
=
await
fs
.
open
(
filePath
,
fs
.
OpenMode
.
READ_WRITE
);
await
fs
.
write
(
file
.
fd
,
data
);
fs
.
close
(
file
);
}
// 循环写文件操作
for
(
let
i
=
0
;
i
<
fileList
.
length
;
i
++
)
{
write
(
'
Hello World!
'
,
fileList
[
i
]).
then
(()
=>
{
console
.
info
(
`Succeeded in writing the file. FileList:
${
fileList
[
i
]}
`
);
}).
catch
((
err
)
=>
{
console
.
error
(
`Failed to write the file. Code is
${
err
.
code
}
, message is
${
err
.
message
}
`
)
return
false
;
})
}
return
true
;
}
```
2.
使用TaskPool执行包含密集I/O的并发函数:通过调用
[
execute()
](
../reference/apis/js-apis-taskpool.md#taskpoolexecute
)
方法执行任务,并在回调中进行调度结果处理。示例中的filePath1和filePath2的获取方式请参见
[
获取应用文件路径
](
../application-models/application-context-stage.md#获取应用文件路径
)
。
```
ts
import
taskpool
from
'
@ohos.taskpool
'
;
let
filePath1
=
...;
// 应用文件路径
let
filePath2
=
...;
// 使用TaskPool执行包含密集I/O的并发函数
// 数组较大时,I/O密集型任务任务分发也会抢占主线程,需要使用多线程能力
taskpool
.
execute
(
concurrentTest
,
[
filePath1
,
filePath2
]).
then
((
ret
)
=>
{
// 步骤3: 调度结果处理
console
.
info
(
`The result:
${
ret
}
`
);
})
```
zh-cn/application-dev/arkts-uitls/linear-container.md
0 → 100644
浏览文件 @
cb0d6c63
# 线性容器
线性容器实现能按顺序访问的数据结构,其底层主要通过数组实现,包括ArrayList、Vector、List、LinkedList、Deque、Queue、Stack七种。
线性容器,充分考虑了数据访问的速度,运行时(Runtime)通过一条字节码指令就可以完成增、删、改、查等操作。
## ArrayList
[
ArrayList
](
../reference/apis/js-apis-list.md
)
即动态数组,可用来构造全局的数组对象。 当需要频繁读取集合中的元素时,推荐使用ArrayList。
ArrayList依据泛型定义,要求存储位置是一片连续的内存空间,初始容量大小为10,并支持动态扩容,每次扩容大小为原始容量的1.5倍。
ArrayList进行增、删、改、查操作的相关API如下:
| 操作 | 描述 |
| -------- | -------- |
| 增加元素 | 通过add(element: T)函数每次在数组尾部增加一个元素。 |
| 增加元素 | 通过insert(element: T, index: number)在指定位置插入一个元素。 |
| 访问元素 | 通过arr
\[
index]获取指定index对应的value值,通过指令获取保证访问速度。 |
| 访问元素 | 通过forEach(callbackFn: (value: T, index?: number, vector?: Vector
<
T
>
) =
>
void, thisArg?: Object): void访问整个ArrayList容器的元素。 |
| 访问元素 | 通过
\[
Symbol.iterator]()Iterableterator
<
T
>
迭代器进行数据访问。 |
| 修改元素 | 通过arr
\[
index] = xxx修改指定index位置对应的value值。 |
| 删除元素 | 通过remove(element: T)删除第一个匹配到的元素。 |
| 删除元素 | 通过removeByRange(fromIndex: number, toIndex:number)删除指定范围内的元素。 |
## Vector
[
Vector
](
../reference/apis/js-apis-vector.md
)
是指连续存储结构,可用来构造全局的数组对象。Vector依据泛型定义,要求存储位置是一片连续的内存空间,初始容量大小为10,并支持动态扩容,每次扩容大小为原始容量的2倍。
Vector和
[
ArrayList
](
../reference/apis/js-apis-arraylist.md
)
相似,都是基于数组实现,但Vector提供了更多操作数组的接口。Vector在支持操作符访问的基础上,还增加了get/set接口,提供更为完善的校验及容错机制,满足用户不同场景下的需求。
API version 9开始,该接口不再维护,推荐使用
[
ArrayList
](
../reference/apis/js-apis-arraylist.md
)
。
Vector进行增、删、改、查操作的相关API如下:
| 操作 | 描述 |
| -------- | -------- |
| 增加元素 | 通过add(element: T)函数每次在数组尾部增加一个元素。 |
| 增加元素 | 通过insert(element: T, index: number)在指定位置插入一个元素。 |
| 访问元素 | 通过vec
\[
index]获取指定index对应的value值,通过指令获取保证访问速度。 |
| 访问元素 | 通过get(index: number)获取指定index位置对应的元素。 |
| 访问元素 | 通过getLastElement()获取最后一个元素。 |
| 访问元素 | 通过getlndexOf(element:T)获取第一个匹配到元素的位置。 |
| 访问元素 | 通过getLastlndexOf(element:T)获取最后一个匹配到元素的位置。 |
| 访问元素 | 通过forEach(callbackfn: (value: T, index?: number, Vector?: Vector
<
T
>
) =
>
thisArg?: Object)访问整个Vector的元素。 |
| 访问元素 | 通过
\[
Symbol.iterator]():Iterablelterator
<
T
>
选代器进行数据访问。 |
| 修改元素 | 通过vec
\[
index]=xxx修改指定index位置对应的value值。 |
| 修改元素 | 通过set(index:number,element:T)修改指定index位置的元素值为element。 |
| 修改元素 | 通过setLength(newSize:number)设置Vector的长度大小。 |
| 删除元素 | 通过removeBylndex(index:number)删除index位置对应的value值。 |
| 删除元素 | 通过remove(element:T)删除第一个匹配到的元素。 |
| 删除元素 | 通过removeByRange(fromlndex:number,tolndex:number)删除指定范围内的元素。 |
## List
[
List
](
../reference/apis/js-apis-list.md
)
可用来构造一个单向链表对象,即只能通过头结点开始访问到尾节点。List依据泛型定义,在内存中的存储位置可以是不连续的。
List和
[
LinkedList
](
../reference/apis/js-apis-linkedlist.md
)
相比,LinkedList是双向链表,可以快速地在头尾进行增删,而List是单向链表,无法双向操作。
当需要频繁的插入删除时,推荐使用List高效操作。
可以通过get/set等接口对存储的元素进行修改,List进行增、删、改、查操作的相关API如下:
| 操作 | 描述 |
| -------- | -------- |
| 增加元素 | 通过add(element: T)函数每次在数组尾部增加一个元素。 |
| 增加元素 | 通过insert(element: T, index: number)在指定位置插入一个元素。 |
| 访问元素 | 通过list
\[
index]获取指定index对应的value值,通过指令获取保证访问速度。 |
| 访问元素 | 通过get(index: number)获取指定index位置对应的元素。 |
| 访问元素 | 通过getFirst()获取第一个元素。 |
| 访问元素 | 通过getLast()获取最后一个元素。 |
| 访问元素 | 通过getlndexOf(element: T)获取第一个匹配到元素的位置。 |
| 访问元素 | 通过getLastlndexOf(element: T)获取最后一个匹配到元素的位置。 |
| 访问元素 | 通过forEach(callbackfn: (value:T, index?: number, list?: List
<
T
>
)=
>
void,thisArg?: Object)访问整个List的元素。 |
| 修改元素 | 通过list
\[
index] = xxx修改指定index位置对应的value值。 |
| 修改元素 | 通过set(index:number, element: T)修改指定index位置的元素值为element。 |
| 修改元素 | 通过replaceAllElements(callbackfn:(value: T,index?: number,list?: List
<
T
>
)=
>
T,thisArg?: Object)对List内元素进行替换操作。 |
| 删除元素 | 通过removeBylndex(index:number)删除index位置对应的value值。 |
| 删除元素 | 通过remove(element:T)删除第一个匹配到的元素。 |
| 删除元素 | 通过removeByRange(fromlndex:number,tolndex:number)删除指定范围内的元素。 |
## LinkedList
[
LinkedList
](
../reference/apis/js-apis-linkedlist.md
)
可用来构造一个双向链表对象,可以在某一节点向前或者向后遍历List。LinkedList依据泛型定义,在内存中的存储位置可以是不连续的。
LinkedList和
[
List
](
../reference/apis/js-apis-list.md
)
相比,LinkedList是双向链表,可以快速地在头尾进行增删,而List是单向链表,无法双向操作。
LinkedList和
[
ArrayList
](
../reference/apis/js-apis-arraylist.md
)
相比,插入数据效率LinkedList优于ArrayList,而查询效率ArrayList优于LinkedList。
当需要频繁的插入删除时,推荐使用LinkedList高效操作。
可以通过get/set等接口对存储的元素进行修改,LinkedList进行增、删、改、查操作的相关API如下:
| 操作 | 描述 |
| -------- | -------- |
| 增加元素 | 通过add(element: T)函数每次在数组尾部增加一个元素。 |
| 增加元素 | 通过insert(element: T, index: number)在指定位置插入一个元素。 |
| 访问元素 | 通过list
\[
index]获取指定index对应的value值,通过指令获取保证访问速度。 |
| 访问元素 | 通过get(index: number)获取指定index位置对应的元素。 |
| 访问元素 | 通过getFirst()获取第一个元素。 |
| 访问元素 | 通过getLast()获取最后一个元素。 |
| 访问元素 | 通过getlndexOf(element: T)获取第一个匹配到元素的位置。 |
| 访问元素 | 通过getLastlndexOf(element: T)获取最后一个匹配到元素的位置 |
| 访问元素 | 通过forEach(callbackfn: (value: T, index?: number, list?: LinkedList
<
T
>
) =
>
void,thisArg?: Object)访问整个LinkedList的元素。 |
| 修改元素 | 通过list
\[
index]=xxx修改指定index位置对应的value值。 |
| 修改元素 | 通过set(index: number,element: T)修改指定index位置的元素值为element。 |
| 修改元素 | 通过replaceAllElements(callbackfn:(value: T,index?: number,list?: LinkedList
<
T
>
)=
>
T,thisArg?: Object)对List内元素进行替换操作。 |
| 删除元素 | 通过removeBylndex(index: number)删除index位置对应的value值。 |
| 删除元素 | 通过remove(element: T)删除第一个匹配到的元素。 |
## Deque
[
Deque
](
../reference/apis/js-apis-deque.md
)
可用来构造双端队列对象,存储元素遵循先进先出的规则,双端队列可以分别从队头或者队尾进行访问。
Deque依据泛型定义,要求存储位置是一片连续的内存空间,其初始容量大小为8,并支持动态扩容,每次扩容大小为原始容量的2倍。Deque底层采用循环队列实现,入队及出队操作效率都比较高。
Deque和
[
Deque
](
../reference/apis/js-apis-deque.md
)
相比,Queue的特点是先进先出,只能在头部删除元素,尾部增加元素。
Deque和
[
Vector
](
../reference/apis/js-apis-vector.md
)
相比,它们都支持在两端增删元素,但Deque不能进行中间插入的操作。对头部元素的插入删除效率高于Vector,而Vector访问元素的效率高于Deque。
需要频繁在集合两端进行增删元素的操作时,推荐使用Deque。
Deque进行增、删、改、查操作的相关API如下:
| 操作 | 描述 |
| -------- | -------- |
| 增加元素 | 通过insertFront(element: T)函数每次在队头增加一个元素。 |
| 增加元素 | 通过insertEnd(element: T)函数每次在队尾增加一个元素。 |
| 访问元素 | 通过getFirst()获取队首元素的value值,但是不进行出队操作。 |
| 访问元素 | 通过getLast()获取队尾元素的value值,但是不进行出队操作。 |
| 访问元素 | 通过popFirst()获取队首元素的value值,并进行出队操作。 |
| 访问元素 | 通过popLast()获取队尾元素的value值,并进行出队操作。 |
| 访问元素 | 通过forEach(callbackfn:(value: T, index?: number, deque?: Deque
<
T
>
) =
>
void,thisArg?: Object)访问整个Deque的元素。 |
| 访问元素 | 通过
\[
Symbol.iterator]():Iterablelterator
<
T
>
选代器进行数据访问。 |
| 修改元素 | 通过forEach(callbackfn:(value: T, index?: number, deque?: Deque
<
T
>
)=
>
void,thisArg?: Object)对队列进行修改操作。 |
| 删除元素 | 通过popFirst()对队首元素进行出队操作并删除。 |
| 删除元素 | 通过popLast()对队尾元素进行出队操作并删除。 |
## Queue
[
Queue
](
../reference/apis/js-apis-queue.md
)
可用来构造队列对象,存储元素遵循先进先出的规则。
Queue依据泛型定义,要求存储位置是一片连续的内存空间,初始容量大小为8,并支持动态扩容,每次扩容大小为原始容量的2倍。
Queue底层采用循环队列实现,入队及出队操作效率都比较高。
Queue和
[
Deque
](
../reference/apis/js-apis-deque.md
)
相比,Queue只能在一端删除一端增加,Deque可以两端增删。
一般符合先进先出的场景可以使用Queue。
Queue进行增、删、改、查操作的相关API如下:
| 操作 | 描述 |
| -------- | -------- |
| 增加元素 | 通过add(element: T)函数每次在队尾增加一个元素。 |
| 访问元素 | 通过getFirst()获取队首元素的value值,但是不进行出队操作。 |
| 访问元素 | 通过pop()获取队首元素的value值,并进行出队操作。 |
| 访问元素 | 通过forEach(callbackfn: (value: T, index?: number, queue?: Queue
<
T
>
) =
>
void,thisArg?: Object)访问整个Queue的元素。 |
| 访问元素 | 通过
\[
Symbol.iterator]():Iterablelterator
<
T
>
选代器进行数据访问。 |
| 修改元素 | 通过forEach(callbackfn:(value: T, index?: number, queue?: Queue
<
T
>
) =
>
void,thisArg?: Object)对队列进行修改操作。 |
| 删除元素 | 通过pop()对队首进行出队操作并删除。 |
## Stack
Stack可用来构造栈对象,存储元素遵循后进先出的规则。
Stack依据泛型定义,要求存储位置是一片连续的内存空间,初始容量大小为8,并支持动态扩容,每次扩容大小为原始容量的1.5倍。Stack底层基于数组实现,入栈出栈均从数组的一端操作。
Stack和
[
Queue
](
../reference/apis/js-apis-queue.md
)
相比,Queue基于循环队列实现,只能在一端删除,另一端插入,而Stack都在一端操作。
一般符合先进后出的场景可以使用Stack。
Stack进行增、删、改、查操作的相关API如下:
| 操作 | 描述 |
| -------- | -------- |
| 增加元素 | 通过push(item:T)函数每次在栈顶增加一个元素。 |
| 访问元素 | 通过peek()获取栈顶元素的value值,但是不进行出栈操作。 |
| 访问元素 | 通过pop()获取栈顶的value值,并进行出栈操作。 |
| 访问元素 | 通过forEach(callbackfn: (value: T, index?: number, stack?: Stack
<
T
>
) =
>
void, thisArg?: Object)访问整个Stack的元素。 |
| 访问元素 | 通过
\[
Symbol.iterator]():Iterablelterator
<
T
>
选代器进行数据访问。 |
| 访问元素 | 通过locate(element: T)获取元素对应的位置。 |
| 修改元素 | 通过forEach(callbackfn:(value: T, index?: number, stack?: Stack
<
T
>
) =
>
void,thisArg?: Object)对栈内元素进行修改操作。 |
| 删除元素 | 通过pop()对栈顶进行出栈操作并删除。 |
## 线性容器的使用
此处列举常用的线性容器ArrayList、Vector、Deque、Stack、List的使用示例,包括导入模块、增加元素、访问元素及修改等操作。示例代码如下所示:
```
js
// ArrayList
import
ArrayList
from
'
@ohos.util.ArrayList
'
;
// 导入ArrayList模块
let
arrayList
=
new
ArrayList
();
arrayList
.
add
(
'
a
'
);
arrayList
.
add
(
1
);
// 增加元素
console
.
info
(
`result:
${
arrayList
[
0
]}
`
);
// 访问元素
arrayList
[
0
]
=
'
one
'
;
// 修改元素
console
.
info
(
`result:
${
arrayList
[
0
]}
`
);
// Vector
import
Vector
from
'
@ohos.util.Vector
'
;
// 导入Vector模块
let
vector
=
new
Vector
();
vector
.
add
(
'
a
'
);
let
b1
=
[
1
,
2
,
3
];
vector
.
add
(
b1
);
vector
.
add
(
false
);
// 增加元素
console
.
info
(
`result:
${
vector
[
0
]}
`
);
// 访问元素
console
.
info
(
`result:
${
vector
.
getFirstElement
()}
`
);
// 访问元素
// Deque
import
Deque
from
'
@ohos.util.Deque
'
;
// 导入Deque模块
let
deque
=
new
Deque
;
deque
.
insertFront
(
'
a
'
);
deque
.
insertFront
(
1
);
// 增加元素
console
.
info
(
`result:
${
deque
[
0
]}
`
);
// 访问元素
deque
[
0
]
=
'
one
'
;
// 修改元素
console
.
info
(
`result:
${
deque
[
0
]}
`
);
// Stack
import
Stack
from
'
@ohos.util.Stack
'
;
// 导入Stack模块
let
stack
=
new
Stack
();
stack
.
push
(
'
a
'
);
stack
.
push
(
1
);
// 增加元素
console
.
info
(
`result:
${
stack
[
0
]}
`
);
// 访问元素
stack
.
pop
();
// 弹出元素
console
.
info
(
`result:
${
stack
.
length
}
`
);
// List
import
List
from
'
@ohos.util.List
'
;
// 导入List模块
let
list
=
new
List
;
list
.
add
(
'
a
'
);
list
.
add
(
1
);
let
b2
=
[
1
,
2
,
3
];
list
.
add
(
b2
);
// 增加元素
console
.
info
(
`result:
${
list
[
0
]}
`
);
// 访问元素
console
.
info
(
`result:
${
list
.
get
(
0
)}
`
);
// 访问元素
```
zh-cn/application-dev/arkts-uitls/multi-thread-concurrency-overview.md
0 → 100644
浏览文件 @
cb0d6c63
# 多线程并发概述
## 简介
并发模型是用来实现不同应用场景中并发任务的编程模型,常见的并发模型分为基于内存共享的并发模型和基于消息通信的并发模型。
Actor并发模型作为基于消息通信并发模型的典型代表,不需要开发者去面对锁带来的一系列复杂偶发的问题,同时并发度也相对较高,得到了广泛的支持和使用,也是当前ArkTS语言选择的并发模型。
由于Actor模型的内存隔离特性,因此需要进行跨线程的数据序列化传输。
## 数据传输对象
目前支持传输的数据对象可以分为
[
普通对象
](
#普通对象
)
、
[
可转移对象
](
#可转移对象
)
、
[
可共享对象
](
#可共享对象
)
三种。
### 普通对象
普通对象传输采用标准的结构化克隆算法(Structured Clone)进行序列化,此算法可以通过递归的方式拷贝传输对象,相较于其他序列化的算法,支持的对象类型更加丰富。
序列化支持的类型包括:除Symbol之外的基础类型、Date、String、RegExp、Array、Map、Set、Object(仅限简单对象,比如通过“{}”或者“new Object”创建,普通对象仅支持传递属性,不支持传递其原型及方法)、ArrayBuffer、TypedArray。
### 可转移对象
可转移对象(Transferable object)传输采用地址转移进行序列化,不需要内容拷贝,会将ArrayBuffer的所有权转移给接收该ArrayBuffer的线程,转移后该ArrayBuffer在发送它的线程中变为不可用,不允许再访问。
```
js
// 定义可转移对象
let
buffer
=
new
ArrayBuffer
(
100
);
```
### 可共享对象
共享对象SharedArrayBuffer,拥有固定长度,可以存储任何类型的数据,包括数字、字符串等。
共享对象传输指SharedArrayBuffer支持在多线程之间传递,传递之后的SharedArrayBuffer对象和原始的SharedArrayBuffer对象可以指向同一块内存,进而达到内存共享的目的。
SharedArrayBuffer对象存储的数据在同时被修改时,需要通过原子操作保证其同步性,即下个操作开始之前务必需要等到上个操作已经结束。
```
js
// 定义可共享对象,可以使用Atomics进行操作
let
sharedBuffer
=
new
SharedArrayBuffer
(
1024
);
```
## TaskPool和Worker
ArkTS提供了TaskPool和Worker两种并发能力供开发者选择,其具体的实现特点和各自的适用场景存在差异,详细请参见
[
TaskPool和Worker的对比
](
taskpool-vs-worker.md
)
。
## 相关实例
针对多线程开发,有以下相关实例可供参考:
-
[
ConcurrentModule:多线程任务
](
https://gitee.com/openharmony/applications_app_samples/tree/master/code/LaunguageBaseClassLibrary/ConcurrentModule
)
zh-cn/application-dev/arkts-uitls/nonlinear-container.md
0 → 100644
浏览文件 @
cb0d6c63
# 非线性容器
非线性容器实现能快速查找的数据结构,其底层通过hash或者红黑树实现,包括HashMap、HashSet、TreeMap、TreeSet、LightWeightMap、LightWeightSet、PlainArray七种。非线性容器中的key及value的类型均满足ECMA标准。
## HashMap
[
HashMap
](
../reference/apis/js-apis-hashmap.md
)
可用来存储具有关联关系的key-value键值对集合,存储元素中key是唯一的,每个key会对应一个value值。
HashMap依据泛型定义,集合中通过key的hash值确定其存储位置,从而快速找到键值对。HashMap的初始容量大小为16,并支持动态扩容,每次扩容大小为原始容量的2倍。HashMap底层基于HashTable实现,冲突策略采用链地址法。
HashMap和
[
TreeMap
](
../reference/apis/js-apis-treemap.md
)
相比,HashMap依据键的hashCode存取数据,访问速度较快。而TreeMap是有序存取,效率较低。
[
HashSet
](
../reference/apis/js-apis-hashset.md
)
基于HashMap实现。HashMap的输入参数由key、value两个值组成。在HashSet中,只对value对象进行处理。
需要快速存取、删除以及插入键值对数据时,推荐使用HashMap。
HashMap进行增、删、改、查操作的相关API如下:
| 操作 | 描述 |
| -------- | -------- |
| 增加元素 | 通过set(key: K, value: V)函数每次在HashMap增加一个键值对。 |
| 访问元素 | 通过get(key: K)获取key对应的value值。 |
| 访问元素 | 通过keys()返回一个选代器对象,包含map中的所有key值。 |
| 访问元素 | 通过value()返回一个迭代器对象,包含map中的所有value值。 |
| 访问元素 | 通过entries()返回一个迭代器对象,包含map中的所有键值对。 |
| 访问元素 | forEach(callbackfn: (value: T, index?: number, map?: HashMap
<
K,V
>
) =
>
void,thisArg?: Object)访问整个map的元素。 |
| 访问元素 | 通过
\[
Symbol.iterator]():Iterablelterator
<
[K,V]
>
选代器进行数据访问。 |
| 修改元素 | 通过replace(key: K, newValue: V)对指定key对应的value值进行修改操作。 |
| 修改元素 | 通过forEach(callbackfn: (value: T, index?: number, map?: HashMap
<
K, V
>
) =
>
void,thisArg?: Object)对map中元素进行修改操作。 |
| 删除元素 | 通过remove(key: K)对map中匹配到的键值对进行删除操作。 |
| 通过clear()清空整个map集合。 |
## HashSet
[
HashSet
](
../reference/apis/js-apis-hashset.md
)
可用来存储一系列值的集合,存储元素中value是唯一的。
HashSet依据泛型定义,集合中通过value的hash值确定其存储位置,从而快速找到该值。HashSet初始容量大小为16,支持动态扩容,每次扩容大小为原始容量的2倍。value的类型满足ECMA标准中要求的类型。HashSet底层数据结构基于HashTable实现,冲突策略采用链地址法。
HashSet基于
[
HashMap
](
../reference/apis/js-apis-hashmap.md
)
实现。在HashSet中,只对value对象进行处理。
HashSet和
[
TreeSet
](
/reference/apis/js-apis-treeset.md
)
相比,HashSet中的数据无序存放,即存放元素的顺序和取出的顺序不一致,而TreeSet是有序存放。它们集合中的元素都不允许重复,但HashSet允许放入null值,TreeSet不允许。
可以利用HashSet不重复的特性,当需要不重复的集合或需要去重某个集合的时候使用。
HashSet进行增、删、改、查操作的相关API如下:
| 操作 | 描述 |
| -------- | -------- |
| 增加元素 | 通过add(value: T)函数每次在HashSet增加一个键值对。 |
| 访问元素 | 通过value()返回一个选代器对象,包含set中的所有value值。 |
| 访问元素 | 通过entries()返回一个选代器对象,包含类似键值对的数组,键值都是value。 |
| 访问元素 | 通过forEach(callbackfn: (value: T, index?: number, set?: HashSet
<
T
>
) =
>
void, thisArg?: Object)访问整个set的元素。 |
| 访问元素 | 通过
\[
Symbol.iterator]():lterablelterator
<
T
>
选代器进行数据访问。 |
| 修改元素 | 通过forEach(callbackfn:(value: T, index?: number, set?: HashSet
<
T
>
) =
>
void,thisArg?: Object)对set中value进行修改操作。 |
| 删除元素 | 通过remove(value: T)对set中匹配到的值进行删除操作。 |
| 通过clear()清空整个set集合。 |
## TreeMap
[
TreeMap
](
../reference/apis/js-apis-treemap.md
)
可用来存储具有关联关系的key-value键值对集合,存储元素中key是唯一的,每个key会对应一个value值。
TreeMap依据泛型定义,集合中的key值是有序的,TreeMap的底层是一棵二叉树,可以通过树的二叉查找快速的找到键值对。key的类型满足ECMA标准中要求的类型。TreeMap中的键值是有序存储的。TreeMap底层基于红黑树实现,可以进行快速的插入和删除。
TreeMap和
[
HashMap
](
../reference/apis/js-apis-hashmap.md
)
相比,HashMap依据键的hashCode存取数据,访问速度较快。而TreeMap是有序存取,效率较低。
一般需要存储有序键值对的场景,可以使用TreeMap。
TreeMap进行增、删、改、查操作的相关API如下:
| 操作 | 描述 |
| -------- | -------- |
| 增加元素 | 通过set(key: K,value: V)函数每次在TreeMap增加一个键值对。 |
| 访问元素 | 通过get(key: K)获取key对应的value值。 |
| 访问元素 | 通过getFirstKey()获取map中排在首位的key值。 |
| 访问元素 | 通过getLastKey()获取map中排在未位的key值。 |
| 访问元素 | 通过keys()返回一个迭代器对象,包含map中的所有key值。 |
| 访问元素 | 通过value()返回一个迭代器对象,包含map中的所有value值。 |
| 访问元素 | 通过entries()返回一个选代器对象,包含map中的所有键值对。 |
| 访问元素 | 通过forEach(callbackfn: (value: T, index?: number, map?: TreeMap
<
K, V
>
) =
>
void, thisArg?: Object)访问整个map的元素。 |
| 访问元素 | 通过
\[
Symbol.iterator]():Iterablelterator
<
[K,V]
>
选代器进行数据访问。 |
| 修改元素 | 通过replace(key: K,newValue: V)对指定key对应的value值进行修改操作。 |
| 修改元素 | 通过forEach(callbackfn: (value: T, index?: number, map?: TreeMap
<
K, V
>
) =
>
void, thisArg?: Object)对map中元素进行修改操作。 |
| 删除元素 | 通过remove(key: K)对map中匹配到的键值对进行删除操作。 |
| 删除元素 | 通过clear()清空整个map集合。 |
## TreeSet
[
TreeSet
](
../reference/apis/js-apis-treemap.md
)
可用来存储一系列值的集合,存储元素中value是唯一的。
TreeSet依据泛型定义,集合中的value值是有序的,TreeSet的底层是一棵二叉树,可以通过树的二叉查找快速的找到该value值,value的类型满足ECMA标准中要求的类型。TreeSet中的值是有序存储的。TreeSet底层基于红黑树实现,可以进行快速的插入和删除。
TreeSet基于
[
TreeMap
](
../reference/apis/js-apis-treemap.md
)
实现,在TreeSet中,只对value对象进行处理。TreeSet可用于存储一系列值的集合,元素中value唯一且有序。
TreeSet和
[
HashSet
](
../reference/apis/js-apis-hashset.md
)
相比,HashSet中的数据无序存放,而TreeSet是有序存放。它们集合中的元素都不允许重复,但HashSet允许放入null值,TreeSet不允许。
一般需要存储有序集合的场景,可以使用TreeSet。
TreeSet进行增、删、改、查操作的相关API如下:
| 操作 | 描述 |
| -------- | -------- |
| 增加元素 | 通过add(value: T)函数每次在HashSet增加一个键值对。 |
| 访问元素 | 通过value()返回一个选代器对象,包含set中的所有value值。 |
| 访问元素 | 通过entries()返回一个选代器对象,包含类似键值对的数组,键值都是value。 |
| 访问元素 | 通过getFirstValue()获取set中排在首位的value值。 |
| 访问元素 | 通过getLastValue()获取set中排在未位的value值。 |
| 访问元素 | 通过forEach(callbackfn: (value: T, index?: number, set?: TreeSet
<
T
>
) =
>
void, thisArg?: Object)访问整个set的元素。 |
| 访问元素 | 通过
\[
Symbol.iterator]():Iterablelterator
<
T
>
选代器进行数据访问。 |
| 修改元素 | 通过forEach(callbackfn: (value: T, index?: number, set?: TreeSet
<
T
>
) =
>
void,thisArg?: Object)对set中value进行修改操作。 |
| 删除元素 | 通过remove(value: T)对set中匹配到的值进行删除操作。 |
| 删除元素 | 通过clear()清空整个set集合。 |
## LightWeightMap
[
LigthWeightMap
](
../reference/apis/js-apis-lightweightmap.md
)
可用来存储具有关联关系的key-value键值对集合,存储元素中key是唯一的,每个key会对应一个value值。LigthWeightMap依据泛型定义,采用更加轻量级的结构,集合中的key值的查找依赖于hash值以及二分查找算法,通过一个数组存储hash值,然后映射到其他数组中的key值以及value值,key的类型满足ECMA标准中要求的类型。
初始默认容量大小为8,每次扩容大小为原始容量的2倍。LigthWeightMap底层标识唯一key通过hash实现,其冲突策略为线性探测法,查找策略基于二分查找法。
LightWeightMap和
[
HashMap
](
../reference/apis/js-apis-hashmap.md
)
都是用来存储键值对的集合,LightWeightMap占用内存更小。
当需要存取key-value键值对时,推荐使用占用内存更小的LightWeightMap。
LigthWeightMap进行增、删、改、查操作的相关API如下:
| 操作 | 描述 |
| -------- | -------- |
| 增加元素 | 通过set(key: K,value: V)函数每次在LigthWeightMap增加一个键值对。 |
| 访问元素 | 通过get(key: K)获取key对应的value值。 |
| 访问元素 | 通过getlndexOfKey(key: K)获取map中指定key的index。 |
| 访问元素 | 通过getindexOfValue(value: V)获取map中指定value的index。 |
| 访问元素 | 通过keys()返回一个选代器对象,包含map中的所有key值。 |
| 访问元素 | 通过value()返回一个选代器对象,包含map中的所有value值。 |
| 访问元素 | 通过entries()返回一个选代器对象,包含map中的所有键值对。 |
| 访问元素 | 通过getKeyAt(index: number)获取指定index对应的key值。 |
| 访问元素 | 通过getValueAt(index:number)获取指定index对应的value值。 |
| 访问元素 | 通过forEach(callbackfn: (value: T, index?: number, map?: LigthWeightMap
<
K, V
>
) =
>
void,thisArg? Object)访问整个map的元素。 |
| 访问元素 | 通过
\[
Symbol.iterator]():Iterablelterator
<
[K,V]
>
迭代器进行数据访问。 |
| 修改元素 | 通过setValueAt(key: K,newValue: V)对指定key对应的value值进行修改操作。 |
| 修改元素 | 通过forEach(callbackfn: (value: T, index?: number, map?: LigthWeightMap
<
K, V
>
) =
>
void,thisArg?: Object)对map中元素进行修改操作。 |
| 删除元素 | 通过remove(key: K)对map中匹配到的键值对进行删除操作。 |
| 删除元素 | 通过removeAt(index: number)对map中指定index的位置进行删除操作。 |
| 删除元素 | 通过clear()清空整个map集合。 |
## LightWeightSet
[
LigthWeightSet
](
../reference/apis/js-apis-lightweightset.md
)
可用来存储一系列值的集合,存储元素中value是唯一的。
LigthWeightSet依据泛型定义,采用更加轻量级的结构,初始默认容量大小为8,每次扩容大小为原始容量的2倍。集合中的value值的查找依赖于hash以及二分查找算法,通过一个数组存储hash值,然后映射到其他数组中的value值,value的类型满足ECMA标准中要求的类型。
LigthWeightSet底层标识唯一value基于hash实现,其冲突策略为线性探测法,查找策略基于二分查找法。
LightWeightSet和
[
HashSet
](
../reference/apis/js-apis-hashset.md
)
都是用来存储键值的集合,LightWeightSet的占用内存更小。
当需要存取某个集合或是对某个集合去重时,推荐使用占用内存更小的LightWeightSet。
LigthWeightSet进行增、删、改、查操作的相关API如下:
| 操作 | 描述 |
| -------- | -------- |
| 增加元素 | 通过add(obj: T)函数每次在LigthWeightSet增加一个键值对。 |
| 访问元素 | 通过getlndexOf(key: T)获取对应的index值。 |
| 访问元素 | 通过value()返回一个迭代器对象,包含map中的所有value值。 |
| 访问元素 | 通过entries()返回一个选代器对象,包含map中的所有键值对。 |
| 访问元素 | 通过getValueAt(index: number)获取指定index对应的value值。 |
| 访问元素 | 通过forEach(callbackfn: (value: T, index?: number, set?: LigthWeightSet
<
T
>
) =
>
void,thisArg?: Object)访问整个set的元素。 |
| 访问元素 | 通过
\[
Symbol.iterator]():Iterablelterator
<
T
>
选代器进行数据访问。 |
| 修改元素 | 通过forEach(callbackfn: (value: T, index?: number, set?: LigthWeightSet
<
T
>
) =
>
void,thisArg?: Object)对set中元素进行修改操作。 |
| 删除元素 | 通过remove(key: K)对set中匹配到的键值对进行删除操作。 |
| 删除元素 | 通过removeAt(index: number)对set中指定index的位置进行删除操作。 |
| 删除元素 | 通过clear()清空整个set集合。 |
## PlainArray
[
PlainArray
](
../reference/apis/js-apis-plainarray.md
)
可用来存储具有关联关系的键值对集合,存储元素中key是唯一的,并且对于PlainArray来说,其key的类型为number类型。每个key会对应一个value值,类型依据泛型的定义,PlainArray采用更加轻量级的结构,集合中的key值的查找依赖于二分查找算法,然后映射到其他数组中的value值。
初始默认容量大小为16,每次扩容大小为原始容量的2倍。PlainArray的查找策略基于二分查找法。
PlainArray和
[
LightWeightMap
](
../reference/apis/js-apis-lightweightmap.md
)
都是用来存储键值对,且均采用轻量级结构,但PlainArray的key值类型只能为number类型。
当需要存储key值为number类型的键值对时,可以使用PlainArray。
PlainArray进行增、删、改、查操作的相关API如下:
| 操作 | 描述 |
| -------- | -------- |
| 增加元素 | 通过add(key: number,value: T)函数每次在PlainArray增加一个键值对。 |
| 访问元素 | 通过get(key: number)获取key对应的value值。 |
| 访问元素 | 通过getlndexOfKey(key: number)获取PlainArray中指定key的index。 |
| 访问元素 | 通过getlndexOfValue(value: T)获取PlainArray中指定value的index。 |
| 访问元素 | 通过getKeyAt(index: number)获取指定index对应的key值。 |
| 访问元素 | 通过getValueAt(index: number)获取指定index对应的value值。 |
| 访问元素 | 通过forEach(callbackfn: (value: T, index?: number, PlainArray?: PlainArray
<
T
>
) =
>
void, thisArg?: Object)访问整个plainarray的元素。 |
| 访问元素 | 通过
\[
Symbol.iterator]():Iterablelterator
<
[number, T]
>
选代器进行数据访问。 |
| 修改元素 | 通过setValueAt(index:number, value: T)对指定index对应的value值进行修改操作。 |
| 修改元素 | 通过forEach(callbackfn: (value: T, index?: number, PlainArray?: PlainArray
<
T
>
) =
>
void,thisArg?: Object)对plainarray中元素进行修改操作。 |
| 删除元素 | 通过remove(key: number)对plainarray中匹配到的键值对进行删除操作。 |
| 删除元素 | 通过removeAt(index: number)对plainarray中指定index的位置进行删除操作。 |
| 删除元素 | 通过removeRangeFrom(index: number, size: number)对plainarray中指定范围内的元素进行删除操作。 |
| 删除元素 | 通过clear()清空整个PlainArray集合。 |
## 非线性容器的使用
此处列举常用的非线性容器HashMap、TreeMap、LightWeightMap、PlainArray的使用示例,包括导入模块、增加元素、访问元素及修改等操作,示例代码如下所示:
```
js
// HashMap
import
HashMap
from
'
@ohos.util.HashMap
'
;
// 导入HashMap模块
let
hashMap
=
new
HashMap
();
hashMap
.
set
(
'
a
'
,
123
);
hashMap
.
set
(
4
,
123
);
// 增加元素
console
.
info
(
`result:
${
hashMap
.
hasKey
(
4
)}
`
);
// 判断是否含有某元素
console
.
info
(
`result:
${
hashMap
.
get
(
'
a
'
)}
`
);
// 访问元素
// TreeMap
import
TreeMap
from
'
@ohos.util.TreeMap
'
;
// 导入TreeMap模块
let
treeMap
=
new
TreeMap
();
treeMap
.
set
(
'
a
'
,
123
);
treeMap
.
set
(
'
6
'
,
356
);
// 增加元素
console
.
info
(
`result:
${
treeMap
.
get
(
'
a
'
)}
`
);
// 访问元素
console
.
info
(
`result:
${
treeMap
.
getFirstKey
()}
`
);
// 访问首元素
console
.
info
(
`result:
${
treeMap
.
getLastKey
()}
`
);
// 访问尾元素
// LightWeightMap
import
LightWeightMap
from
'
@ohos.util.LightWeightMap
'
;
// 导入LightWeightMap模块
let
lightWeightMap
=
new
LightWeightMap
();
lightWeightMap
.
set
(
'
x
'
,
123
);
lightWeightMap
.
set
(
'
8
'
,
356
);
// 增加元素
console
.
info
(
`result:
${
lightWeightMap
.
get
(
'
a
'
)}
`
);
// 访问元素
console
.
info
(
`result:
${
lightWeightMap
.
get
(
'
x
'
)}
`
);
// 访问元素
console
.
info
(
`result:
${
lightWeightMap
.
getIndexOfKey
(
'
8
'
)}
`
);
// 访问元素
// PlainArray
import
PlainArray
from
'
@ohos.util.PlainArray
'
// 导入PlainArray模块
let
plainArray
=
new
PlainArray
();
plainArray
.
add
(
1
,
'
sdd
'
);
plainArray
.
add
(
2
,
'
sff
'
);
// 增加元素
console
.
info
(
`result:
${
plainArray
.
get
(
1
)}
`
);
// 访问元素
console
.
info
(
`result:
${
plainArray
.
getKeyAt
(
1
)}
`
);
// 访问元素
```
zh-cn/application-dev/arkts-uitls/single-io-development.md
0 → 100644
浏览文件 @
cb0d6c63
# 单次I/O任务开发指导
Promise和async/await提供异步并发能力,适用于单次I/O任务的场景开发,本文以使用异步进行单次文件写入为例来提供指导。
1.
实现单次I/O任务逻辑。
```
js
import
fs
from
'
@ohos.file.fs
'
;
async
function
write
(
data
:
string
,
filePath
:
string
)
{
let
file
=
await
fs
.
open
(
filePath
,
fs
.
OpenMode
.
READ_WRITE
);
fs
.
write
(
file
.
fd
,
data
).
then
((
writeLen
)
=>
{
fs
.
close
(
file
);
}).
catch
((
err
)
=>
{
console
.
error
(
`Failed to write data. Code is
${
err
.
code
}
, message is
${
err
.
message
}
`
);
})
}
```
2.
采用异步能力调用单次I/O任务。示例中的filePath的获取方式请参见
[
获取应用文件路径
](
../application-models/application-context-stage.md#获取应用文件路径
)
。
```
js
let
filePath
=
...;
// 应用文件路径
write
(
'
Hello World!
'
,
filePath
).
then
(()
=>
{
console
.
info
(
'
Succeeded in writing data.
'
);
})
```
zh-cn/application-dev/arkts-uitls/sync-task-development.md
0 → 100644
浏览文件 @
cb0d6c63
# 同步任务开发指导
同步任务是指在多个线程之间协调执行的任务,其目的是确保多个任务按照一定的顺序和规则执行,例如使用锁来防止数据竞争。
同步任务的实现需要考虑多个线程之间的协作和同步,以确保数据的正确性和程序的正确执行。由于TaskPool偏向于单个独立的任务,因此当各个同步任务之间相对独立时推荐使用TaskPool,例如一系列导入的静态方法,或者单例实现的方法;反之,如果同步任务之间有关联性,则需要使用Worker,例如无法单例创建的类对象实现的方法。
## 使用TaskPool处理同步任务
当调度独立的同步任务,或者一系列同步任务为静态方法实现,或者可以通过单例构造唯一的句柄或类对象,可在不同任务池之间使用时,推荐使用TaskPool。
1.
定义并发函数,内部调用同步方法。
2.
创建任务,并通过TaskPool执行,再对异步结果进行操作。创建
[
Task
](
../reference/apis/js-apis-taskpool.md#task
)
,并通过
[
execute()
](
../reference/apis/js-apis-taskpool.md#taskpoolexecute-1
)
接口执行同步任务。
3.
执行并发操作。
模拟一个包含同步调用的单实例类。
```
ts
// Handle.ts 代码
export
default
class
Handle
{
static
getInstance
()
{
// 返回单例对象
}
static
syncGet
()
{
// 同步Get方法
return
;
}
static
syncSet
(
num
:
number
)
{
// 同步Set方法
return
;
}
}
```
业务使用TaskPool调用相关同步方法的代码。
```
ts
// Index.ets代码
import
taskpool
from
'
@ohos.taskpool
'
;
import
Handle
from
'
./Handle
'
;
// 返回静态句柄
// 步骤1: 定义并发函数,内部调用同步方法
@
Concurrent
function
func
(
num
:
number
)
{
// 调用静态类对象中实现的同步等待调用
Handle
.
syncSet
(
num
);
// 或者调用单例对象中实现的同步等待调用
Handle
.
getInstance
().
syncGet
();
return
true
;
}
// 步骤2: 创建任务并执行
async
function
asyncGet
()
{
// 创建task并传入函数func
let
task
=
new
taskpool
.
Task
(
func
,
1
);
// 执行task任务,获取结果res
let
res
=
await
taskpool
.
execute
(
task
);
// 对同步逻辑后的结果进行操作
console
.
info
(
String
(
res
));
}
@
Entry
@
Component
struct
Index
{
@
State
message
:
string
=
'
Hello World
'
;
build
()
{
Row
()
{
Column
()
{
Text
(
this
.
message
)
.
fontSize
(
50
)
.
fontWeight
(
FontWeight
.
Bold
)
.
onClick
(()
=>
{
// 步骤3: 执行并发操作
asyncGet
();
})
}
.
width
(
'
100%
'
)
.
height
(
'
100%
'
)
}
}
}
```
## 使用Worker处理关联的同步任务
当一系列同步任务需要使用同一个句柄调度,或者需要依赖某个类对象调度,无法在不同任务池之间共享时,需要使用Worker。
1.
在主线程中创建Worker对象,同时接收Worker线程发送回来的消息。
```
js
import
worker
from
'
@ohos.worker
'
;
@
Entry
@
Component
struct
Index
{
@
State
message
:
string
=
'
Hello World
'
;
build
()
{
Row
()
{
Column
()
{
Text
(
this
.
message
)
.
fontSize
(
50
)
.
fontWeight
(
FontWeight
.
Bold
)
.
onClick
(()
=>
{
let
w
=
new
worker
.
ThreadWorker
(
'
entry/ets/workers/MyWorker.ts
'
);
w
.
onmessage
=
function
(
d
)
{
// 接收Worker子线程的结果
}
w
.
onerror
=
function
(
d
)
{
// 接收Worker子线程的错误信息
}
// 向Worker子线程发送Set消息
w
.
postMessage
({
'
type
'
:
0
,
'
data
'
:
'
data
'
})
// 向Worker子线程发送Get消息
w
.
postMessage
({
'
type
'
:
1
})
// 销毁线程
w
.
terminate
()
})
}
.
width
(
'
100%
'
)
}
.
height
(
'
100%
'
)
}
}
```
2.
在Worker线程中绑定Worker对象,同时处理同步任务逻辑。
```
js
// handle.ts代码
export
default
class
Handle
{
syncGet
()
{
return
;
}
syncSet
(
num
:
number
)
{
return
;
}
}
// Worker.ts代码
import
worker
,
{
ThreadWorkerGlobalScope
,
MessageEvents
}
from
'
@ohos.worker
'
;
import
Handle
from
'
./handle.ts
'
// 返回句柄
var
workerPort
:
ThreadWorkerGlobalScope
=
worker
.
workerPort
;
// 无法传输的句柄,所有操作依赖此句柄
var
handler
=
new
Handle
()
// Worker线程的onmessage逻辑
workerPort
.
onmessage
=
function
(
e
:
MessageEvents
)
{
switch
(
e
.
data
.
type
)
{
case
0
:
handler
.
syncSet
(
e
.
data
.
data
);
workerPort
.
postMessage
(
'
success set
'
);
case
1
:
handler
.
syncGet
();
workerPort
.
postMessage
(
'
success get
'
);
}
}
```
zh-cn/application-dev/arkts-uitls/taskpool-vs-worker.md
0 → 100644
浏览文件 @
cb0d6c63
# TaskPool和Worker的对比
TaskPool(任务池)和Worker的作用是为应用程序提供一个多线程的运行环境,用于处理耗时的计算任务或其他密集型任务。可以有效地避免这些任务阻塞主线程,从而最大化系统的利用率,降低整体资源消耗,并提高系统的整体性能。
本文将从
[
实现特点
](
#实现特点对比
)
和
[
适用场景
](
#适用场景对比
)
两个方面来进行TaskPool与Worker的比较,同时提供了各自运作机制和注意事项的相关说明。
## 实现特点对比
**表1**
TaskPool和Worker的实现特点对比
| 实现 | TaskPool | Worker |
| -------- | -------- | -------- |
| 内存模型 | 线程间隔离,内存不共享。 | 线程间隔离,内存不共享。 |
| 参数传递机制 | 采用标准的结构化克隆算法(Structured Clone)进行序列化、反序列化,完成参数传递。
<br/>
支持ArrayBuffer转移和SharedArrayBuffer共享。 | 采用标准的结构化克隆算法(Structured Clone)进行序列化、反序列化,完成参数传递。
<br/>
支持ArrayBuffer转移和SharedArrayBuffer共享。 |
| 参数传递 | 直接传递,无需封装,默认进行transfer。 | 消息对象唯一参数,需要自己封装。 |
| 方法调用 | 直接将方法传入调用。 | 消息解析并在Worker.ts中实现对应方法。 |
| 返回值 | 异步调用后默认返回。 | 主动发送消息,需在onmessage解析赋值。 |
| 生命周期 | TaskPool自行管理生命周期,无需关心任务负载高低。 | 开发者自行管理Worker的数量及生命周期。 |
| 任务池个数上限 | 自动管理,无需配置。 | 最多开启8个Worker。 |
| 任务执行时长上限 | 3分钟(不包含Promise和async/await异步调用的耗时,例如网络下载、文件读写等I/O任务的耗时)。 | 无限制。 |
| 设置任务的优先级 | 支持配置任务优先级。 | 不支持。 |
| 执行任务的取消 | 支持取消已经发起的任务。 | 不支持。 |
## 适用场景对比
TaskPool和Worker均支持多线程并发能力。由于TaskPool的工作线程会绑定系统的调度优先级,并且支持负载均衡(自动扩缩容),而Worker需要开发者自行创建,存在创建耗时以及不支持设置调度优先级,在性能方面使用TaskPool会优于Worker,因此大多数场景推荐使用TaskPool。
TaskPool偏向独立任务(线程级)维度,超长任务(大于3分钟)会被系统自动回收;而Worker偏向线程的维度,支持长时间占据线程执行。
-
运行时间超过3分钟(不包含Promise和async/await异步调用的耗时,例如网络下载、文件读写等I/O任务的耗时)的任务。例如后台进行1小时的预测算法训练等CPU密集型任务,需要使用Worker。
-
有关联的一系列同步任务。例如某数据库操作时,要用创建的句柄操作,包含增、删、改、查多个任务,要保证同一个句柄,需要使用Worker。
-
需要设置优先级的任务。例如图库直方图绘制场景,后台计算的直方图数据会用于前台界面的显示,影响用户体验,需要高优先级处理,需要使用TaskPool。
-
需要频繁取消的任务。例如图库大图浏览场景,为提升体验,会同时缓存当前图片左右侧各2张图片,往一侧滑动跳到下一张图片时,要取消另一侧的一个缓存任务,需要使用TaskPool。
-
大量或者调度点较分散的任务。例如大型应用的多个模块包含多个耗时任务,不方便使用8个Worker去做负载管理,推荐采用TaskPool。
## TaskPool运作机制
**图1**
TaskPool运作机制示意图

TaskPool支持开发者在主线程封装任务抛给任务队列,系统选择合适的工作线程,进行任务的分发及执行,再将结果返回给主线程。接口直观易用,支持任务的执行、取消,以及指定优先级的能力,同时通过系统统一线程管理,结合动态调度及负载均衡算法,可以节约系统资源。系统默认会启动一个任务工作线程,当任务较多时会扩容,工作线程数量上限跟当前设备的物理核数相关,为max(3, 物理核数-1)个,长时间没有任务分发时会缩容,减少工作线程数量。
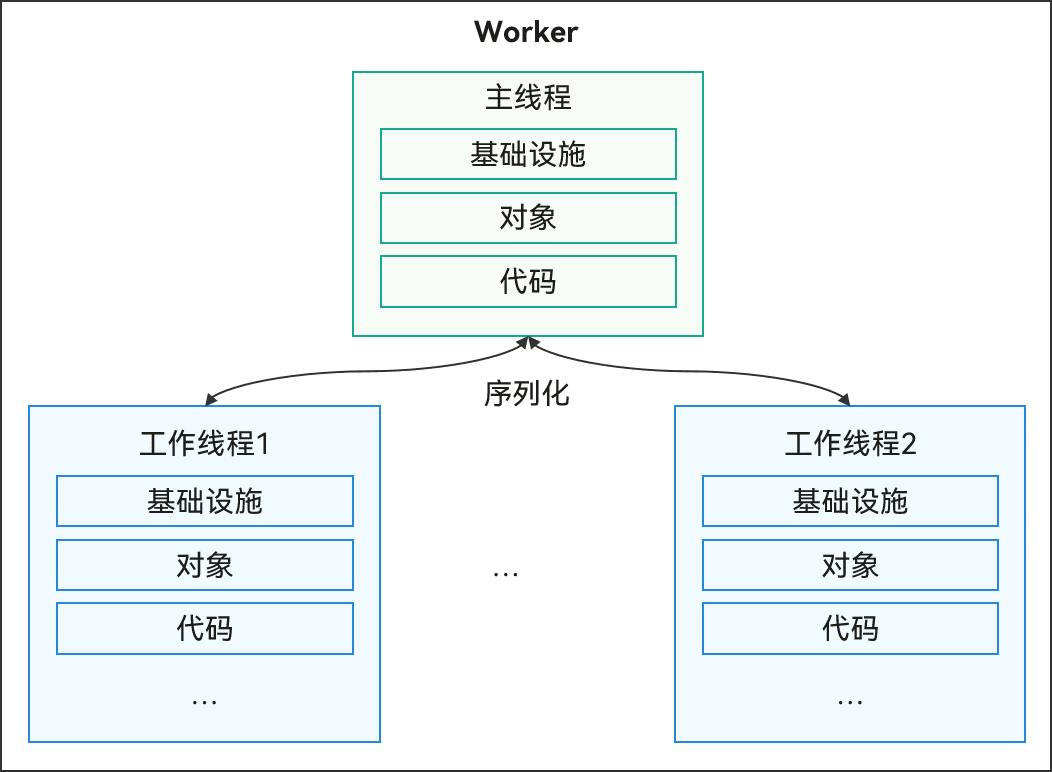
## Worker运作机制
**图2**
Worker运作机制示意图

创建Worker的线程称为宿主线程(不一定是主线程,工作线程也支持创建Worker子线程),Worker自身的线程称为Worker子线程(或Actor线程、工作线程)。每个Worker子线程与宿主线程拥有独立的实例,包含基础设施、对象、代码段等。Worker子线程和宿主线程之间的通信是基于消息传递的,Worker通过序列化机制与宿主线程之间相互通信,完成命令及数据交互。
## TaskPool注意事项
-
实现任务的函数需要使用装饰器
\@
Concurrent标注,且仅支持在.ets文件中使用。
-
实现任务的函数只支持普通函数或者async函数,不支持类成员函数或者匿名函数。
-
实现任务的函数仅支持在Stage模型的工程中使用import的变量和入参变量,否则只能使用入参变量。
-
任务函数在TaskPool工作线程的执行耗时不能超过3分钟(不包含Promise和async/await异步调用的耗时,例如网络下载、文件读写等I/O任务的耗时),否则会被强制退出。
-
实现任务的函数入参需满足序列化支持的类型,详情请参见
[
普通对象传输
](
multi-thread-concurrency-overview.md#普通对象
)
。
-
ArrayBuffer参数在TaskPool中默认转移,需要设置转移列表的话可通过接口
[
setTransferList()
](
../reference/apis/js-apis-taskpool.md#settransferlist10
)
设置。
-
由于不同线程中上下文对象是不同的,因此TaskPool工作线程只能使用线程安全的库,例如UI相关的非线程安全库不能使用。
-
序列化传输的数据量大小限制为16MB。
## Worker注意事项
-
创建Worker时,传入的Worker.ts路径在不同版本有不同的规则,详情请参见
[
文件路径注意事项
](
#文件路径注意事项
)
。
-
Worker创建后需要手动管理生命周期,且最多同时运行的Worker子线程数量为8个,详情请参见
[
生命周期注意事项
](
#生命周期注意事项
)
。
-
[
Ability类型
](
../quick-start/application-package-structure-stage.md
)
的Module支持使用Worker,
[
Library类型
](
../quick-start/application-package-structure-stage.md
)
的Module不支持使用Worker。
-
创建Worker不支持使用其他Module的Worker.ts文件,即不支持跨模块调用Worker。
-
由于不同线程中上下文对象是不同的,因此Worker线程只能使用线程安全的库,例如UI相关的非线程安全库不能使用。
-
序列化传输的数据量大小限制为16MB。
### 文件路径注意事项
当使用Worker模块具体功能时,均需先构造Worker实例对象,其构造函数与API版本相关。
```
js
// API 9及之后版本使用:
const
worker1
=
new
worker
.
ThreadWorker
(
scriptURL
);
// API 8及之前版本使用:
const
worker1
=
new
worker
.
Worker
(
scriptURL
);
```
构造函数需要传入Worker的路径(scriptURL),Worker文件存放位置默认路径为Worker文件所在目录与pages目录属于同级。
**Stage模型**
构造函数中的scriptURL示例如下:
```
js
// 写法一
// Stage模型-目录同级(entry模块下,workers目录与pages目录同级)
const
worker1
=
new
worker
.
ThreadWorker
(
'
entry/ets/workers/MyWorker.ts
'
,
{
name
:
"
first worker in Stage model
"
});
// Stage模型-目录不同级(entry模块下,workers目录是pages目录的子目录)
const
worker2
=
new
worker
.
ThreadWorker
(
'
entry/ets/pages/workers/MyWorker.ts
'
);
// 写法二
// Stage模型-目录同级(entry模块下,workers目录与pages目录同级),假设bundlename是com.example.workerdemo
const
worker3
=
new
worker
.
ThreadWorker
(
'
@bundle:com.example.workerdemo/entry/ets/workers/worker
'
);
// Stage模型-目录不同级(entry模块下,workers目录是pages目录的子目录),假设bundlename是com.example.workerdemo
const
worker4
=
new
worker
.
ThreadWorker
(
'
@bundle:com.example.workerdemo/entry/ets/pages/workers/worker
'
);
```
-
基于Stage模型工程目录结构,写法一的路径含义:
-
entry:module.json5文件中module的name属性对应值。
-
ets:用于存放ets源码,固定目录。
-
workers/MyWorker.ts:worker源文件在ets目录下的路径。
-
基于Stage模型工程目录结构,写法二的路径含义:
-
\@
bundle:固定标签。
-
bundlename:当前应用包名。
-
entryname:module.json5文件中module的name属性对应值。
-
ets:用于存放ets源码,固定目录。
-
workerdir/workerfile:worker源文件在ets目录下的路径,可不带文件后缀名。
**FA模型**
构造函数中的scriptURL示例如下:
```
js
// FA模型-目录同级(entry模块下,workers目录与pages目录同级)
const
worker1
=
new
worker
.
ThreadWorker
(
'
workers/worker.js
'
,
{
name
:
'
first worker in FA model
'
});
// FA模型-目录不同级(entry模块下,workers目录与pages目录的父目录同级)
const
worker2
=
new
worker
.
ThreadWorker
(
'
../workers/worker.js
'
);
```
### 生命周期注意事项
-
Worker的创建和销毁耗费性能,建议开发者合理管理已创建的Worker并重复使用。Worker空闲时也会一直运行,因此当不需要Worker时,可以调用
[
terminate()
](
../reference/apis/js-apis-worker.md#terminate9
)
接口或
[
parentPort.close()
](
../reference/apis/js-apis-worker.md#close9
)
方法主动销毁Worker。若Worker处于已销毁或正在销毁等非运行状态时,调用其功能接口,会抛出相应的错误。
-
Worker存在数量限制,支持最多同时存在8个Worker。
-
在API version 8及之前的版本,当Worker数量超出限制时,会抛出“Too many workers, the number of workers exceeds the maximum.”错误。
-
从API version 9开始,当Worker数量超出限制时,会抛出“Worker initialization failure, the number of workers exceeds the maximum.”错误。
zh-cn/application-dev/arkts-uitls/xml-conversion.md
0 → 100644
浏览文件 @
cb0d6c63
# XML转换
将XML文本转换为JavaScript对象可以更轻松地处理和操作数据,并且更适合在JavaScript应用程序中使用。
语言基础类库提供ConvertXML类将xml文本转换为JavaScript对象,输入为待转换的XML字符串及转换选项,输出为转换后的JavaScript对象。具体转换选项可见
[
API参考@ohos.convertxml
](
../reference/apis/js-apis-convertxml.md
)
。
## 注意事项
XML解析及转换需要确认传入的XML数据符合标准格式。
## 开发步骤
此处以XML转为JavaScript对象后获取其标签值为例,说明转换效果。
1.
引入模块。
```
js
import
convertxml
from
'
@ohos.convertxml
'
;
```
2.
输入待转换XML,设置转换选项。
```
js
let
xml
=
'
<?xml version="1.0" encoding="utf-8"?>
'
+
'
<note importance="high" logged="true">
'
+
'
<title>Happy</title>
'
+
'
<todo>Work</todo>
'
+
'
<todo>Play</todo>
'
+
'
</note>
'
;
let
options
=
{
// trim: false 转换后是否删除文本前后的空格,否
// declarationKey: "_declaration" 转换后文件声明使用_declaration来标识
// instructionKey: "_instruction" 转换后指令使用_instruction标识
// attributesKey: "_attributes" 转换后属性使用_attributes标识
// textKey: "_text" 转换后标签值使用_text标识
// cdataKey: "_cdata" 转换后未解析数据使用_cdata标识
// docTypeKey: "_doctype" 转换后文档类型使用_doctype标识
// commentKey: "_comment" 转换后注释使用_comment标识
// parentKey: "_parent" 转换后父类使用_parent标识
// typeKey: "_type" 转换后元素类型使用_type标识
// nameKey: "_name" 转换后标签名称使用_name标识
// elementsKey: "_elements" 转换后元素使用_elements标识
trim
:
false
,
declarationKey
:
"
_declaration
"
,
instructionKey
:
"
_instruction
"
,
attributesKey
:
"
_attributes
"
,
textKey
:
"
_text
"
,
cdataKey
:
"
_cdata
"
,
docTypeKey
:
"
_doctype
"
,
commentKey
:
"
_comment
"
,
parentKey
:
"
_parent
"
,
typeKey
:
"
_type
"
,
nameKey
:
"
_name
"
,
elementsKey
:
"
_elements
"
}
```
3.
调用转换函数,打印结果。
```
js
let
conv
=
new
convertxml
.
ConvertXML
();
let
result
=
conv
.
convertToJSObject
(
xml
,
options
);
let
strRes
=
JSON
.
stringify
(
result
);
// 将js对象转换为json字符串,用于显式输出
console
.
info
(
strRes
);
// 也可以直接处理转换后的JS对象,获取标签值
let
title
=
result
[
'
_elements
'
][
0
][
'
_elements
'
][
0
][
'
_elements
'
][
0
][
'
_text
'
];
// 解析<title>标签对应的值
let
todo
=
result
[
'
_elements
'
][
0
][
'
_elements
'
][
1
][
'
_elements
'
][
0
][
'
_text
'
];
// 解析<todo>标签对应的值
let
todo2
=
result
[
'
_elements
'
][
0
][
'
_elements
'
][
2
][
'
_elements
'
][
0
][
'
_text
'
];
// 解析<todo>标签对应的值
console
.
info
(
title
);
// Happy
console
.
info
(
todo
);
// Work
console
.
info
(
todo2
);
// Play
```
输出结果如下所示:
```
js
strRes
:
{
"
_declaration
"
:{
"
_attributes
"
:{
"
version
"
:
"
1.0
"
,
"
encoding
"
:
"
utf-8
"
}},
"
_elements
"
:[{
"
_type
"
:
"
element
"
,
"
_name
"
:
"
note
"
,
"
_attributes
"
:{
"
importance
"
:
"
high
"
,
"
logged
"
:
"
true
"
},
"
_elements
"
:[{
"
_type
"
:
"
element
"
,
"
_name
"
:
"
title
"
,
"
_elements
"
:[{
"
_type
"
:
"
text
"
,
"
_text
"
:
"
Happy
"
}]},{
"
_type
"
:
"
element
"
,
"
_name
"
:
"
todo
"
,
"
_elements
"
:[{
"
_type
"
:
"
text
"
,
"
_text
"
:
"
Work
"
}]},{
"
_type
"
:
"
element
"
,
"
_name
"
:
"
todo
"
,
"
_elements
"
:[{
"
_type
"
:
"
text
"
,
"
_text
"
:
"
Play
"
}]}]}]}
title
:
Happy
todo
:
Work
todo2
:
Play
```
zh-cn/application-dev/arkts-uitls/xml-generation.md
0 → 100644
浏览文件 @
cb0d6c63
# XML生成
XML可以作为数据交换格式,被各种系统和应用程序所支持。例如Web服务,可以将结构化数据以XML格式进行传递。
XML还可以作为消息传递格式,在分布式系统中用于不同节点之间的通信与交互。
## 注意事项
-
XML标签必须成对出现,生成开始标签就要生成结束标签。
-
XML标签对大小写敏感,开始标签与结束标签大小写要一致。
## 开发步骤
XML模块提供XmlSerializer类来生成XML文件,输入为固定长度的Arraybuffer或DataView对象,该对象用于存放输出的XML数据。
通过调用不同的方法来写入不同的内容,如startElement(name: string)写入元素开始标记,setText(text: string)写入标签值。
XML模块的API接口可以参考
[
@ohos.xml
](
../reference/apis/js-apis-xml.md
)
的详细描述,按需求调用对应函数可以生成一份完整的XML文件。
1.
引入模块。
```
js
import
xml
from
'
@ohos.xml
'
;
import
util
from
'
@ohos.util
'
;
```
2.
创建缓冲区,构造XmlSerializer对象(可以基于Arraybuffer构造XmlSerializer对象, 也可以基于DataView构造XmlSerializer对象)。
```
js
// 1.基于Arraybuffer构造XmlSerializer对象
let
arrayBuffer
=
new
ArrayBuffer
(
2048
);
// 创建一个2048字节的缓冲区
let
thatSer
=
new
xml
.
XmlSerializer
(
arrayBuffer
);
// 基于Arraybuffer构造XmlSerializer对象
// 2.基于DataView构造XmlSerializer对象
let
arrayBuffer
=
new
ArrayBuffer
(
2048
);
// 创建一个2048字节的缓冲区
let
dataView
=
new
DataView
(
arrayBuffer
);
// 使用DataView对象操作ArrayBuffer对象
let
thatSer
=
new
xml
.
XmlSerializer
(
dataView
);
// 基于DataView构造XmlSerializer对象
```
3.
调用XML元素生成函数。
```
js
thatSer
.
setDeclaration
();
// 写入xml的声明
thatSer
.
startElement
(
'
bookstore
'
);
// 写入元素开始标记
thatSer
.
startElement
(
'
book
'
);
// 嵌套元素开始标记
thatSer
.
setAttributes
(
'
category
'
,
'
COOKING
'
);
// 写入属性及属性值
thatSer
.
startElement
(
'
title
'
);
thatSer
.
setAttributes
(
'
lang
'
,
'
en
'
);
thatSer
.
setText
(
'
Everyday
'
);
// 写入标签值
thatSer
.
endElement
();
// 写入结束标记
thatSer
.
startElement
(
'
author
'
);
thatSer
.
setText
(
'
Giada
'
);
thatSer
.
endElement
();
thatSer
.
startElement
(
'
year
'
);
thatSer
.
setText
(
'
2005
'
);
thatSer
.
endElement
();
thatSer
.
endElement
();
thatSer
.
endElement
();
```
4.
使用Uint8Array操作Arraybuffer,调用TextDecoder对Uint8Array解码后输出。
```
js
let
view
=
new
Uint8Array
(
arrayBuffer
);
// 使用Uint8Array读取arrayBuffer的数据
let
textDecoder
=
util
.
TextDecoder
.
create
();
// 调用util模块的TextDecoder类
let
res
=
textDecoder
.
decodeWithStream
(
view
);
// 对view解码
console
.
info
(
res
);
```
输出结果如下:
```
js
<
?
xml
version
=
\
"
1.0
\"
encoding=
\"
utf-8
\"
?><bookstore>
\r\n
<book category=
\"
COOKING
\"
>
\r\n
<title lang=
\"
en
\"
>Everyday</title>
\r\n
<author>Giada</author>
\r\n
<year>2005</year>
\r\n
</book>
\r\n
</bookstore>
```
zh-cn/application-dev/arkts-uitls/xml-overview.md
0 → 100644
浏览文件 @
cb0d6c63
# XML概述
XML(可扩展标记语言)是一种用于描述数据的标记语言,旨在提供一种通用的方式来传输和存储数据,特别是Web应用程序中经常使用的数据。XML并不预定义标记。因此,XML更加灵活,并且可以适用于广泛的应用领域。
XML文档由元素(element)、属性(attribute)和内容(content)组成。
-
元素指的是标记对,包含文本、属性或其他元素。
-
属性提供了有关元素的其他信息。
-
内容则是元素包含的数据或子元素。
XML还可以通过使用XML Schema或DTD(文档类型定义)来定义文档结构。这些机制允许开发人员创建自定义规则以验证XML文档是否符合其预期的格式。
XML还支持命名空间、实体引用、注释、处理指令等特性,使其能够灵活地适应各种数据需求。
语言基础类库提供了XML相关的基础能力,包括:
[
XML的生成
](
xml-generation.md
)
、
[
XML的解析
](
xml-parsing.md
)
和
[
XML的转换
](
xml-conversion.md
)
。
zh-cn/application-dev/arkts-uitls/xml-parsing.md
0 → 100644
浏览文件 @
cb0d6c63
# XML解析
对于以XML作为载体传递的数据,实际使用中需要对相关的节点进行解析,一般包括
[
解析XML标签和标签值
](
#解析xml标签和标签值
)
、
[
解析XML属性和属性值
](
#解析xml属性和属性值
)
、
[
解析XML事件类型和元素深度
](
#解析xml事件类型和元素深度
)
三类场景。
XML模块提供XmlPullParser类对XML文件解析,输入为含有XML文本的ArrayBufffer或DataView,输出为解析得到的信息。
**表1**
XML解析选项
| 名称 | 类型 | 必填 | 说明 |
| -------- | -------- | -------- | -------- |
| supportDoctype | boolean | 否 | 是否忽略文档类型。默认为false,表示对文档类型进行解析。 |
| ignoreNameSpace | boolean | 否 | 是否忽略命名空间。默认为false,表示对命名空间进行解析。 |
| tagValueCallbackFunction | (name: string, value: string) =
>
boolean | 否 | 获取tagValue回调函数,打印标签及标签值。默认为null,表示不进行XML标签和标签值的解析。 |
| attributeValueCallbackFunction | (name: string, value: string) =
>
boolean | 否 | 获取attributeValue回调函数, 打印属性及属性值。默认为null,表示不进行XML属性和属性值的解析。 |
| tokenValueCallbackFunction | (eventType: EventType, value: ParseInfo) =
>
boolean | 否 | 获取tokenValue回调函数,打印标签事件类型及parseInfo对应属性。默认为null,表示不进行XML事件类型解析。 |
## 注意事项
-
XML解析及转换需要确认传入的xml数据符合标准格式。
-
XML解析目前不支持按指定节点解析对应的节点值。
## 解析XML标签和标签值
1.
引入模块。
```
js
import
xml
from
'
@ohos.xml
'
;
import
util
from
'
@ohos.util
'
;
// 需要使用util模块函数对文件编码
```
2.
对XML文件编码后调用XmlPullParser。
可以基于Arraybuffer构造XmlPullParser对象, 也可以基于DataView构造XmlPullParser对象。
```
js
let
strXml
=
'
<?xml version="1.0" encoding="utf-8"?>
'
+
'
<note importance="high" logged="true">
'
+
'
<title>Play</title>
'
+
'
<lens>Work</lens>
'
+
'
</note>
'
;
let
textEncoder
=
new
util
.
TextEncoder
();
let
arrBuffer
=
textEncoder
.
encodeInto
(
strXml
);
// 对数据编码,防止包含中文字符乱码
// 1.基于Arraybuffer构造XmlPullParser对象
let
that
=
new
xml
.
XmlPullParser
(
arrBuffer
.
buffer
,
'
UTF-8
'
);
// 2.基于DataView构造XmlPullParser对象
let
dataView
=
new
DataView
(
arrBuffer
.
buffer
);
let
that
=
new
xml
.
XmlPullParser
(
dataView
,
'
UTF-8
'
);
```
3.
自定义回调函数,本例直接打印出标签及标签值。
```
js
let
str
=
''
;
function
func
(
name
,
value
){
str
=
name
+
value
;
console
.
info
(
str
);
return
true
;
//true:继续解析 flase:停止解析
}
```
4.
设置解析选项,调用parse函数。
```
js
let
options
=
{
supportDoctype
:
true
,
ignoreNameSpace
:
true
,
tagValueCallbackFunction
:
func
};
that
.
parse
(
options
);
```
输出结果如下所示:
```
js
note
title
Play
title
lens
Work
lens
note
```
## 解析XML属性和属性值
1.
引入模块。
```
js
import
xml
from
'
@ohos.xml
'
;
import
util
from
'
@ohos.util
'
;
// 需要使用util模块函数对文件编码
```
2.
对XML文件编码后调用XmlPullParser。
```
js
let
strXml
=
'
<?xml version="1.0" encoding="utf-8"?>
'
+
'
<note importance="high" logged="true">
'
+
'
<title>Play</title>
'
+
'
<title>Happy</title>
'
+
'
<lens>Work</lens>
'
+
'
</note>
'
;
let
textEncoder
=
new
util
.
TextEncoder
();
let
arrBuffer
=
textEncoder
.
encodeInto
(
strXml
);
// 对数据编码,防止包含中文字符乱码
let
that
=
new
xml
.
XmlPullParser
(
arrBuffer
.
buffer
,
'
UTF-8
'
);
```
3.
自定义回调函数,本例直接打印出属性及属性值。
```
js
let
str
=
''
;
function
func
(
name
,
value
){
str
+=
name
+
'
'
+
value
+
'
'
;
return
true
;
// true:继续解析 flase:停止解析
}
```
4.
设置解析选项,调用parse函数。
```
js
let
options
=
{
supportDoctype
:
true
,
ignoreNameSpace
:
true
,
attributeValueCallbackFunction
:
func
};
that
.
parse
(
options
);
console
.
info
(
str
);
// 一次打印出所有的属性及其值
```
输出结果如下所示:
```
js
importance
high
logged
true
// note节点的属性及属性值
```
## 解析XML事件类型和元素深度
1.
引入模块。
```
js
import
xml
from
'
@ohos.xml
'
;
import
util
from
'
@ohos.util
'
;
// 需要使用util模块函数对文件编码
```
2.
对XML文件编码后调用XmlPullParser。
```
js
let
strXml
=
'
<?xml version="1.0" encoding="utf-8"?>
'
+
'
<note importance="high" logged="true">
'
+
'
<title>Play</title>
'
+
'
</note>
'
;
let
textEncoder
=
new
util
.
TextEncoder
();
let
arrBuffer
=
textEncoder
.
encodeInto
(
strXml
);
// 对数据编码,防止包含中文字符乱码
let
that
=
new
xml
.
XmlPullParser
(
arrBuffer
.
buffer
,
'
UTF-8
'
);
```
3.
自定义回调函数,本例直接打印元素事件类型及元素深度。
```
js
let
str
=
''
;
function
func
(
name
,
value
){
str
=
name
+
'
'
+
value
.
getDepth
();
// getDepth 获取元素的当前深度
console
.
info
(
str
)
return
true
;
//true:继续解析 flase:停止解析
}
```
4.
设置解析选项,调用parse函数。
```
js
let
options
=
{
supportDoctype
:
true
,
ignoreNameSpace
:
true
,
tokenValueCallbackFunction
:
func
};
that
.
parse
(
options
);
```
输出结果如下所示:
```
js
0
0
// 0:<?xml version="1.0" encoding="utf-8"?> 对应事件类型START_DOCUMENT值为0 0:起始深度为0
2
1
// 2:<note importance="high" logged="true"> 对应事件类型START_TAG值为2 1:深度为1
2
2
// 2:<title>对应事件类型START_TAG值为2 2:深度为2
4
2
// 4:Play对应事件类型TEXT值为4 2:深度为2
3
2
// 3:</title>对应事件类型END_TAG值为3 2:深度为2
3
1
// 3:</note>对应事件类型END_TAG值为3 1:深度为1(与<note对应>)
1
0
// 1:对应事件类型END_DOCUMENT值为1 0:深度为0
```
## 场景示例
此处以调用所有解析选项为例,提供解析XML标签、属性和事件类型的开发示例。
```
js
import
xml
from
'
@ohos.xml
'
;
import
util
from
'
@ohos.util
'
;
let
strXml
=
'
<?xml version="1.0" encoding="UTF-8"?>
'
+
'
<book category="COOKING">
'
+
'
<title lang="en">Everyday</title>
'
+
'
<author>Giada</author>
'
+
'
</book>
'
;
let
textEncoder
=
new
util
.
TextEncoder
();
let
arrBuffer
=
textEncoder
.
encodeInto
(
strXml
);
let
that
=
new
xml
.
XmlPullParser
(
arrBuffer
.
buffer
,
'
UTF-8
'
);
let
str
=
''
;
function
tagFunc
(
name
,
value
)
{
str
=
name
+
value
;
console
.
info
(
'
tag-
'
+
str
);
return
true
;
}
function
attFunc
(
name
,
value
)
{
str
=
name
+
'
'
+
value
;
console
.
info
(
'
attri-
'
+
str
);
return
true
;
}
function
tokenFunc
(
name
,
value
)
{
str
=
name
+
'
'
+
value
.
getDepth
();
console
.
info
(
'
token-
'
+
str
);
return
true
;
}
let
options
=
{
supportDocType
:
true
,
ignoreNameSpace
:
true
,
tagValueCallbackFunction
:
tagFunc
,
attributeValueCallbackFunction
:
attFunc
,
tokenValueCallbackFunction
:
tokenFunc
};
that
.
parse
(
options
);
```
输出结果如下所示:
```
js
tag
-
token
-
0
0
tag
-
book
attri
-
category
COOKING
token
-
2
1
tag
-
title
attri
-
lang
en
token
-
2
2
tag
-
Everyday
token
-
4
2
tag
-
title
token
-
3
2
tag
-
author
token
-
2
2
tag
-
Giada
token
-
4
2
tag
-
author
token
-
3
2
tag
-
book
token
-
3
1
tag
-
token
-
1
0
```
zh-cn/application-dev/website.md
浏览文件 @
cb0d6c63
...
@@ -377,6 +377,27 @@
...
@@ -377,6 +377,27 @@
-
[
动画动效
](
ui/ui-js-animate-dynamic-effects.md
)
-
[
动画动效
](
ui/ui-js-animate-dynamic-effects.md
)
-
[
动画帧
](
ui/ui-js-animate-frame.md
)
-
[
动画帧
](
ui/ui-js-animate-frame.md
)
-
[
自定义组件
](
ui/ui-js-custom-components.md
)
-
[
自定义组件
](
ui/ui-js-custom-components.md
)
-
ArkTS语言基础类库
-
[
ArkTS语言基础类库概述
](
arkts-utils/arkts-commonlibrary-overview.md
)
-
并发
-
[
并发概述
](
arkts-utils/concurrency-overview.md
)
-
使用异步并发能力进行开发
-
[
异步并发概述
](
arkts-utils/async-concurrency-overview.md
)
-
[
单次I/O任务开发指导
](
arkts-utils/single-io-development.md
)
-
使用多线程并发能力进行开发
-
[
TaskPool和Worker的对比
](
arkts-utils/taskpool-vs-worker.md
)
-
[
CPU密集型任务开发指导
](
arkts-utils/cpu-intensive-task-development.md
)
-
[
I/O密集型任务开发指导
](
arkts-utils/io-intensive-task-development.md
)
-
[
同步任务开发指导
](
arkts-utils/sync-task-development.md
)
-
容器类库
-
[
容器类库概述
](
arkts-utils/container-overview.md
)
-
[
线性容器
](
arkts-utils/linear-container.md
)
-
[
非线性容器
](
arkts-utils/nonlinear-container.md
)
-
XML生成、解析与转换
-
[
XML概述
](
arkts-utils/xml-overview.md
)
-
[
XML生成
](
arkts-utils/xml-generation.md
)
-
[
XML解析
](
arkts-utils/xml-parsing.md
)
-
[
XML转换
](
arkts-utils/xml-conversion.md
)
-
Web
-
Web
-
[
Web组件概述
](
web/web-component-overview.md
)
-
[
Web组件概述
](
web/web-component-overview.md
)
-
[
使用Web组件加载页面
](
web/web-page-loading-with-web-components.md
)
-
[
使用Web组件加载页面
](
web/web-page-loading-with-web-components.md
)
...
...
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}
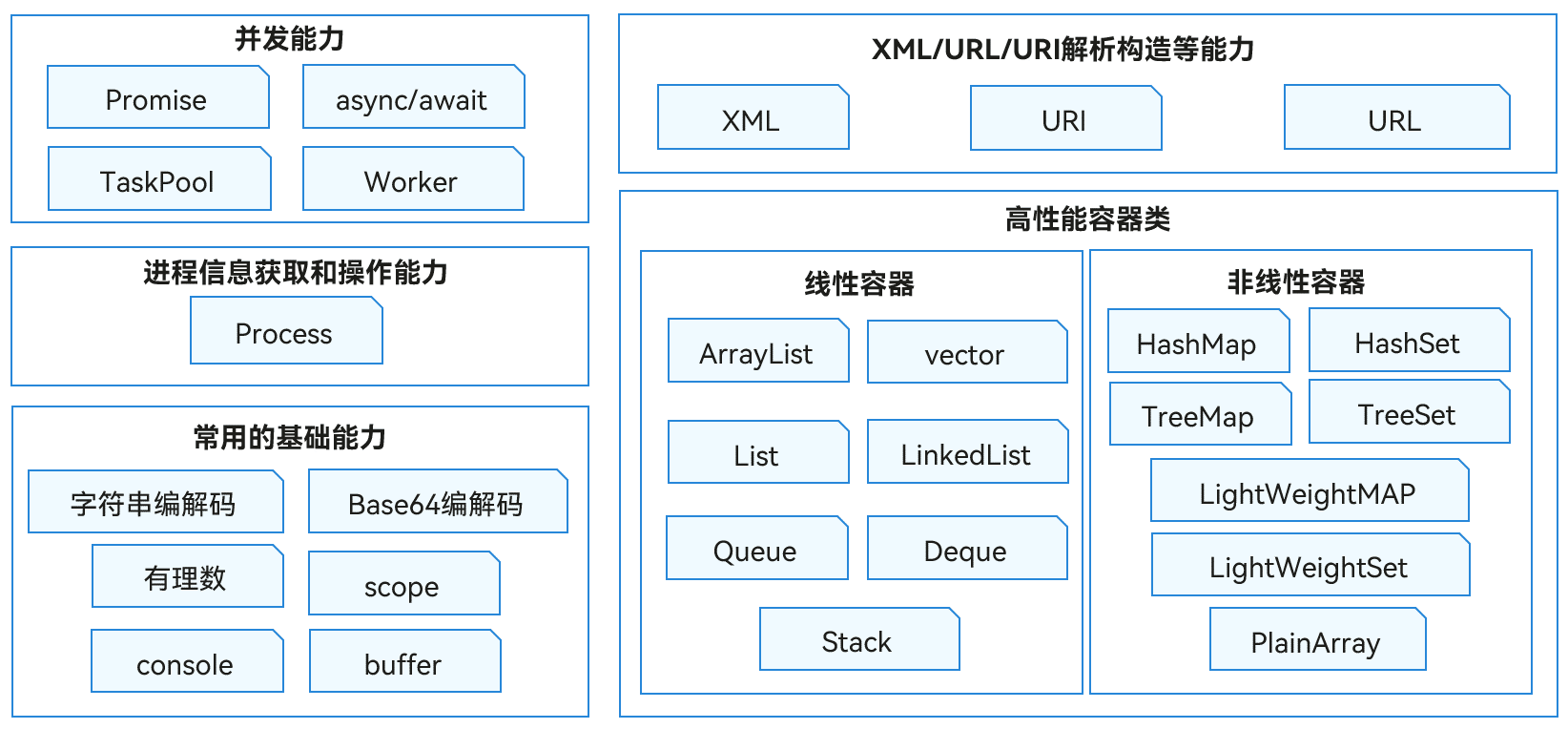
{kind=link}
{kind=link}
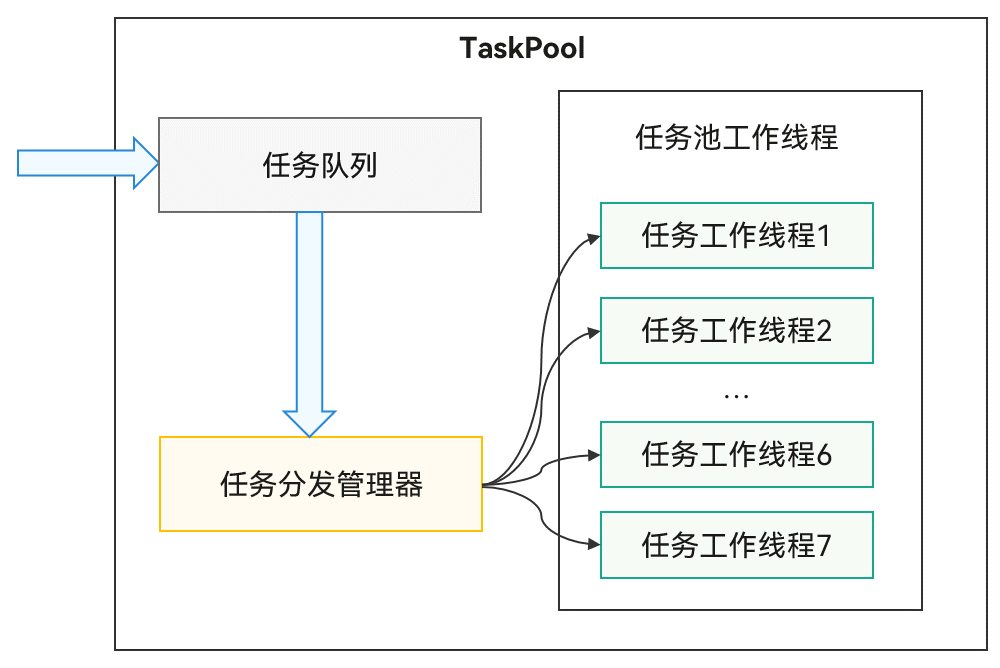
{kind=link}