- Supporting [asynchronous concurrency and multithread concurrency](concurrency-overview.md)
- Supports standard JavaScript asynchronous concurrency capabilities such as Promise and async/await.
- Uses **TaskPool** to provide a multithread running environment for applications. The use of **TaskPool** helps reduce resource consumption and improve system performance. It also frees you from caring about the lifecycle of thread instances.
- Uses **Worker** to support multithread concurrency. The worker thread can communicate with the host thread. You need to proactively create and close a worker thread.
- Providing common capabilities of [adding, deleting, modifying, and querying elements in containers](container-overview.md)
- Constructing and parsing XML files, URLs, and URIs
- Extensible Markup Language (XML) is designed for data transmission and storage. The common library provides APIs for [XML generation, parsing, and conversion](xml-overview.md).
-[URI](../reference/apis/js-apis-uri.md) is a uniform resource identifier that uniquely identifies a resource. [URL](../reference/apis/js-apis-url.md) is a uniform resource locator that provides a path for locating a resource.
- Supporting common [string and binary data processing](../reference/apis/js-apis-util.md) and [logging](../reference/apis/js-apis-logs.md)
- Provides APIs to encode and decode strings.
- Provides APIs to encode and decode Base64-encoded bytes.
- Supports common rational number operations, including comparing rational numbers and obtaining numerators and denominators.
- Provides **Scope** APIs to define the valid range of a field.
- Provides APIs to process binary data in scenarios such as TCP flows or file system operations.
- Supports logging using the console.
- Providing the capability of [obtaining process information and operating processes](../reference/apis/js-apis-process.md)
Promise and async/await are standard JavaScript syntax that provides asynchronous concurrency. Asynchronous code ensures that actions initiated now finish later. It allows the execution of only one segment of code at a time and is therefore applicable to the development of a single I/O task, for example, a network request or a file read/write operation.
Promise and async/await allow an application to perform other operations without waiting for the completion of certain actions.
## Promise
Promise is an object used to process asynchronous operations. It converts asynchronous operations into a style similar to synchronous operations for easier code writing and maintenance. Promise provides a state mechanism to manage different phases of asynchronous operations. It also provides methods to register callback functions to handle the success or failure of these operations.
Promise has three states: pending, fulfilled, and rejected. After being created, a Promise object is in the pending state and changes to the fulfilled or rejected state when the asynchronous operation is complete.
The most common usage for Promise is to instantiate a Promise object through a constructor and pass in a function (usually named **executor**) with two parameters. The **executor** function receives two parameters: **resolve** and **reject**, which represent the callback functions that should be called when the asynchronous operation succeeds and fails, respectively. The code snippet below creates a Promise object and simulates an asynchronous operation:
```js
constpromise=newPromise((resolve,reject)=>{
setTimeout(()=>{
constrandomNumber=Math.random();
if(randomNumber>0.5){
resolve(randomNumber);
}else{
reject(newError('Random number is too small'));
}
},1000);
});
```
In the preceding code, the **setTimeout** function simulates an asynchronous operation that randomly generates a number one second later. If the random number is greater than 0.5, the **resolve** callback function is executed and the generated random number is passed in as a parameter. Otherwise, the **reject** callback function is executed and an error object is passed in as a parameter.
After the Promise object is created, you can use the **then** and **catch** methods to register the callback functions for the fulfilled and rejected states. The **then** method can receive two parameters: one for processing the fulfilled state and the other for processing the rejected state. If only one parameter is passed in, the callback function is executed as long as the state changes. The **catch** method receives a callback function to process the failure result, that is, capture the exception thrown when the Promise state changes to **rejected** or the operation fails. The code snippet below shows the use of **then** and **catch** methods:
```js
promise.then(result=>{
console.info(`Random number is ${result}`);
}).catch(error=>{
console.error(error.message);
});
```
In the preceding code, the callback function of the **then** method receives the success result of the Promise object as a parameter and outputs it to the console. If the Promise object enters the rejected state, the callback function of the **catch** method receives the error object as a parameter and outputs it to the console.
## Async/Await
Async/Await is a Promise syntax sugar used to process asynchronous operations, making it easier to read and write asynchronous code. The async keyword is used to declare an asynchronous function, and the await keyword is used to wait for Promise parsing (fulfilled or rejected). In this way, the asynchronous operation logic is coded as a synchronous operation.
The **async** function returns a Promise object to represent an asynchronous operation. Inside the **async** function, you can use the await keyword to wait for the parsing of the Promise object and return its parsed value. If an **async** function throws an exception, the Promise object returned by the function is rejected, and the exception information is passed to the **onRejected()** method of the Promise object.
The code snippet below uses async/await to simulate an asynchronous operation that returns a string three seconds later.
In the preceding code, the await keyword is used to wait for the parsing of the Promise object and store its parsed value in the **result** variable.
Note that the entire operation must be packaged in the **async** function because the code needs to wait for the asynchronous operation to complete. In addition to **await**, you can use the try/catch block to capture exceptions in asynchronous operations.
Concurrency refers to the capability of processing multiple tasks in the same period. To improve the response speed and frame rate of applications and prevent time-consuming tasks from blocking the main thread, OpenHarmony provides two policies: asynchronous concurrency and multithread concurrency.
- Asynchronous concurrency means that an action in asynchronous code is suspended and will continue later. Only one segment of code is being executed at a time.
- Multithread concurrency allows multiple segments of code to be executed at a time. When the main thread continues to respond to user operations and update the UI, time-consuming operations are performed in the background to avoid application freezing.
Concurrency is used in a variety of scenarios, including a single I/O task, CPU intensive task, I/O intensive task, synchronous task, and the like. You can select a concurrency policy based on your scenario.
ArkTS provides the following mechanisms to support asynchronous concurrency and multithread concurrency:
- Promise and async/await: provide asynchronous concurrency and apply to the development of a single I/O task. For details, see [Asynchronous Concurrency Overview](async-concurrency-overview.md).
-**TaskPool** and **Worker**: provide multithread concurrency and apply to the development of CPU intensive tasks, I/O intensive tasks, and synchronous tasks. For details, see [Multithread Concurrency Overview](multi-thread-concurrency-overview.md).
The container classes provide a set of methods to process elements of various data types stored in containers.
The container classes are implemented in a way similar to static languages. By restricting storage locations and attributes, they remove redundant logic for each type of data while providing the complete functionalities, ensuring efficient data access and improving application performance.
Currently, OpenHarmony provides 14 types of linear and non-linear containers, each of which has its own features and uses cases. For details, see [Linear Containers](linear-container.md) and [Nonlinear Containers](nonlinear-container.md).
CPU intensive tasks occupy lots of system computing resources for a long period of time, during which other events of the thread are blocked. Example CPU intensive tasks are image processing, video encoding, and data analysis.
OpenHarmony uses multithread concurrency to process CPU intensive tasks. This improves CPU utilization and application response speed.
**Worker** is recommended for a series of synchronous tasks. When there are independent tasks with a huge number or scattered scheduling points, it is inconvenient to use eight worker threads to manage load. In this case, **TaskPool** is recommended. The following uses histogram processing and a time-consuming model prediction task in the background as examples.
## Using TaskPool to Process Histograms
1. Implement the logic of image processing.
2. Segment the data, and use one task to process a data segment.
Create a [task](../reference/apis/js-apis-taskpool.md#task), and call [execute()](../reference/apis/js-apis-taskpool.md#taskpoolexecute-1) to execute the task. After the task is complete, the histogram processing result is returned simultaneously.
3. Process the result.
```ts
importtaskpoolfrom'@ohos.taskpool';
@Concurrent
functionimageProcessing(dataSlice:ArrayBuffer){
// Step 1: Perform specific image processing operations and other time-consuming operations.
The following uses the training of a region-specific house price prediction model as an example. This model can be used to predict house prices in the region based on the house area and number of rooms. The model needs to run for a long time, and the prediction will use the previous running result. Due to these considerations, **Worker** is used for the development.
1. Add the worker creation template provided on DevEco Studio to your project, and name it **MyWorker**.

2. In the main thread, call [ThreadWorker()](../reference/apis/js-apis-worker.md#threadworker9) to create a **Worker** object. The calling thread is the host thread.
3. In the host thread, call [onmessage()](../reference/apis/js-apis-worker.md#onmessage9) to receive messages from the worker thread, and call [postMessage()](../reference/apis/js-apis-worker.md#postmessage9) to send messages to the worker thread.
For example, the host thread sends training and prediction messages to the worker thread, and receives messages sent back by the worker thread.
```js
// Receive the result of the worker thread.
workerInstance.onmessage=function(e){
// data carries the information sent by the main thread.
letdata=e.data;
console.info('MyWorker.ts onmessage');
// Perform time-consuming operations in the worker thread.
}
workerInstance.onerror=function(d){
// Receive error information of the worker thread.
}
// Send a training message to the worker thread.
workerInstance.postMessage({'type':0});
// Send a prediction message to the worker thread.
5. In the worker thread, call [onmessage()](../reference/apis/js-apis-worker.md#onmessage9-1) to receive messages sent by the host thread, and call [postMessage()](../reference/apis/js-apis-worker.md#postmessage9-2) to send messages to the host thread.
For example, the prediction model and its training process are defined in the worker thread, and messages are exchanged with the main thread.
workerPort.postMessage({type:'message',value:'send message is invalid'});
break;
}
}
```
6. After the task is completed in the worker thread, destroy the worker thread. The worker thread can be destroyed by itself or the host thread. Then, call [onexit()](../reference/apis/js-apis-worker.md#onexit9) in the host thread to define the processing logic after the worker thread is destroyed.
```js
// After the worker thread is destroyed, execute the onexit() callback.
workerInstance.onexit = function() {
console.info("main thread terminate");
}
```
In the host thread, call [terminate()](../reference/apis/js-apis-worker.md#terminate9) to destroy the worker thread and stop the worker thread from receiving messages.
```js
// Destroy the worker thread.
workerInstance.terminate();
```
In the worker thread, call [close()](../reference/apis/js-apis-worker.md#close9) to destroy the worker thread and stop the worker thread from receiving messages.
Asynchronous concurrency can solve the problem of a single blocking I/O operation. In the case of I/O intensive tasks, the execution of other tasks in the thread is still blocked. To resolve this issue, multithread concurrency is introduced.
The performance focus of I/O intensive tasks is not the CPU processing capability, but the speed and efficiency of I/O operations, since such a task usually requires frequent operations such as disk read/write and network communication. The following uses frequent read/write operations on a system file to simulate concurrency processing of I/O intensive tasks.
1. Define a concurrency function that internally calls I/O capabilities intensively.
```ts
importfsfrom'@ohos.file.fs';
// Define a concurrency function that internally calls I/O capabilities intensively.
console.info(`Succeeded in writing the file. FileList: ${fileList[i]}`);
}).catch((err)=>{
console.error(`Failed to write the file. Code is ${err.code}, message is ${err.message}`)
returnfalse;
})
}
returntrue;
}
```
2. Use **TaskPool** to execute the concurrency function that contains the intensive I/O operations. Specifically, call [execute()](../reference/apis/js-apis-taskpool.md#taskpoolexecute) to execute the tasks and process the scheduling result in a callback. For details about how to obtain **filePath1** and **filePath2** in the example, see [Obtaining Application File Paths](../application-models/application-context-stage.md#obtaining-application-file-paths).
```ts
importtaskpoolfrom'@ohos.taskpool';
letfilePath1=...;// Application file path
letfilePath2=...;
// Use TaskPool to execute the concurrency function that contains the intensive I/O operations.
// In the case of a large array, the distribution of I/O intensive tasks also preempts the main thread. Therefore, multiple threads are required.
Linear containers implement a data structure that enables sequential access. The bottom layer of linear containers is implemented through arrays. OpenHarmony provides the following linear containers: **ArrayList**, **Vector**, **List**, **LinkedList**, **Deque**, **Queue**, and **Stack**.
Fully considering the data access speed, linear containers support Create, Read, Update, and Delete (CRUD) through a bytecode instruction at runtime.
## ArrayList
[ArrayList](../reference/apis/js-apis-arraylist.md) is a dynamic array that can be used to construct a global array object. You are advised to use **ArrayList** when elements in a container need to be frequently read.
**ArrayList** uses generics and must be stored in a contiguous memory space. Its initial capacity is 10, and it increases capacity 1.5-fold in each dynamic expansion.
**ArrayList** provides the following CRUD APIs.
| Operation| Description|
| --------- | ------- |
| Adding elements| Use **add(element: T)** to add an element at the end of this container.|
| Adding elements| Use **insert(element: T, index: number)** to insert an element at a given position (specified by **index**).|
| Accessing elements| Use **arr\[index]** to obtain the value at a given position (specified by **index**).|
| Accessing elements| Use **forEach(callbackFn: (value: T, index?: number, arrlist?: ArrayList<T>) => void, thisArg?: Object): void** to traverse the elements in this container.|
| Accessing elements| Use **\[Symbol.iterator]():IterableIterator<T>** for data access.|
| Modifying elements| Use **arr\[index] = xxx** to change the value at a given position (specified by **index**).|
| Deleting elements| Use **remove(element: T)** to remove the first occurrence of the specified element.|
| Deleting elements| Use **removeByRange(fromIndex: number, toIndex: number)** to remove all of the elements within a range.|
## Vector
[Vector](../reference/apis/js-apis-vector.md) is a continuous storage structure that can be used to construct a global array object. **Vector** uses generics and must be stored in a contiguous memory space. Its initial capacity is 10, and it has capacity doubled in each dynamic expansion.
Both **Vector** and [ArrayList](../reference/apis/js-apis-arraylist.md) are implemented based on arrays, but **Vector** provides more interfaces for operating the arrays. In addition to operator access, **Vector** provides the getter and setter to provide a more complete verification and error tolerance mechanism.
The APIs provided by **Vector** are deprecated since API version 9. You are advised to use [ArrayList](../reference/apis/js-apis-arraylist.md).
**Vector** provides the following CRUD APIs.
| Operation| Description|
| --------- | ------- |
| Adding elements| Use **add(element: T)** to add an element at the end of this container.|
| Adding elements| Use **insert(element: T, index: number)** to insert an element at a given position (specified by **index**).|
| Accessing elements| Use **vec\[index]** to obtain the value at a given position (specified by **index**).|
| Accessing elements| Use **get(index: number)** to obtain the element at a given position (specified by **index**).|
| Accessing elements| Use **getLastElement()** to obtain the last element in this container.|
| Accessing elements| Use **getIndexOf(element: T)** to obtain the index of the first occurrence of the specified element.|
| Accessing elements| Use **getLastIndexOf(element: T)** to obtain the index of the last occurrence of the specified element.|
| Accessing elements| Use **forEach(callbackFn: (value: T, index?: number, Vector?: Vector<T>) => void, thisArg?: Object)** to traverse the elements in this container.|
| Accessing elements| Use **\[Symbol.iterator]():IterableIterator<T>** for data access.|
| Modifying elements| Use **vec\[index]=xxx** to change the value at a given position (specified by **index**).|
| Modifying elements| Use **set(index: number, element: T)** to replace an element at a given position (specified by **index**) with a given element.|
| Modifying elements| Use **setLength(newSize: number)** to set the size of this container.|
| Deleting elements| Use **removeByIndex(index: number)** to remove the value at a given position (specified by **index**).|
| Deleting elements| Use **remove(element: T)** to remove the first occurrence of the specified element.|
| Deleting elements| Use **removeByRange(fromIndex: number, toIndex: number)** to remove all of the elements within a range.|
## List
[List](../reference/apis/js-apis-list.md) can be used to construct a singly linked list, which supports access only through the head node to the tail node. **List** uses generics and can be stored in a non-contiguous memory space.
Unlike [LinkedList](../reference/apis/js-apis-linkedlist.md), which is a doubly linked list, **List** is a singly linked list that does not support insertion or removal at both ends.
You are advised to use **List** for frequent insertion and removal operations.
**List** provides the following CRUD APIs.
| Operation| Description|
| --------- | ------ |
| Adding elements| Use **add(element: T)** to add an element at the end of this container.|
| Adding elements| Use **insert(element: T, index: number)** to insert an element at a given position (specified by **index**).|
| Accessing elements| Use **list\[index]** to obtain the value at a given position (specified by **index**).|
| Accessing elements| Use **get(index: number)** to obtain the element at a given position (specified by **index**).|
| Accessing elements| Use **getFirst()** to obtain the first element in this container.|
| Accessing elements| Use **getLast()** to obtain the last element in this container.|
| Accessing elements| Use **getIndexOf(element: T)** to obtain the index of the first occurrence of the specified element.|
| Accessing elements| Use **getLastIndexOf(element: T)** to obtain the index of the last occurrence of the specified element.|
| Accessing elements| Use **forEach(callbackfn: (value: T, index?: number, list?: List<T>)=> void, thisArg?: Object)** to traverse the elements in this container.|
| Accessing elements| Use **\[Symbol.iterator]():IterableIterator<T>** for data access.|
| Modifying elements| Use **list\[index] = xxx** to change the value at a given position (specified by **index**).|
| Modifying elements| Use **set(index: number, element: T)** to replace an element at a given position (specified by **index**) with a given element.|
| Modifying elements| Use **replaceAllElements(callbackFn:(value: T,index?: number,list?: List<T>)=>T,thisArg?: Object)** to replace all elements in this container with new elements.|
| Deleting elements| Use **removeByIndex(index: number)** to remove the value at a given position (specified by **index**).|
| Deleting elements| Use **remove(element: T)** to remove the first occurrence of the specified element.|
## LinkedList
[LinkedList](../reference/apis/js-apis-linkedlist.md) can be used to construct a doubly linked list, which can be traversed at both ends. **LinkedList** uses generics and can be stored in a non-contiguous memory space.
Unlike [List](../reference/apis/js-apis-list.md), which is a singly linked list, **LinkedList** is a doubly linked list that supports insertion and removal at both ends.
**LinkedList** is more efficient in data insertion than [ArrayList](../reference/apis/js-apis-arraylist.md), but less efficient in data access.
You are advised to use **LinkedList** for frequent insertion and removal operations.
**LinkedList** provides the following CRUD APIs.
| Operation| Description|
| ---------- | ------ |
| Adding elements| Use **add(element: T)** to add an element at the end of this container.|
| Adding elements| Use **insert(index: number, element: T)** to insert an element at a given position (specified by **index**).|
| Accessing elements| Use **list\[index]** to obtain the value at a given position (specified by **index**).|
| Accessing elements| Use **get(index: number)** to obtain the element at a given position (specified by **index**).|
| Accessing elements| Use **getFirst()** to obtain the first element in this container.|
| Accessing elements| Use **getLast()** to obtain the last element in this container.|
| Accessing elements| Use **getIndexOf(element: T)** to obtain the index of the first occurrence of the specified element.|
| Accessing elements| Use **getLastIndexOf(element: T)** to obtain the index of the last occurrence of the specified element.|
| Accessing elements| Use **forEach(callbackFn: (value: T, index?: number, list?: LinkedList<T>) => void, thisArg?: Object)** to traverse the elements in this container.|
| Accessing elements| Use **\[Symbol.iterator]():IterableIterator<T>** for data access.|
| Modifying elements| Use **list\[index]=xxx** to change the value at a given position (specified by **index**).|
| Modifying elements| Use **set(index: number, element: T)** to replace an element at a given position (specified by **index**) with a given element.|
| Deleting elements| Use **removeByIndex(index: number)** to remove the value at a given position (specified by **index**).|
| Deleting elements| Use **remove(element: T)** to remove the first occurrence of the specified element.|
## Deque
[Deque](../reference/apis/js-apis-deque.md) can be used to construct a double-ended queue (deque) that follows the principles of First In First Out (FIFO) and Last In First Out (LIFO). It allows insertion and removal of elements at both the ends.
**Deque** uses generics and must be stored in a contiguous memory space. Its initial capacity is 8, and it has capacity doubled in each dynamic expansion. The bottom layer of **Deque** is implemented by cyclic queues, delivering a high efficiency in enqueuing and dequeuing.
[Queue](../reference/apis/js-apis-queue.md) follows the principle of FIFO only and allows element removal at the front and insertion at the rear.
[Vector](../reference/apis/js-apis-vector.md) supports insertion and deletion of elements in between, as well as at both the ends. When compared with **Vector**, **Deque** is more efficient in inserting and removing header elements, but less efficient in accessing elements.
You are advised to use **Deque** when you need to frequently insert or remove elements at both the ends of a container.
**Deque** provides the following CRUD APIs.
| Operation| Description|
| ---------- | ------ |
| Adding elements| Use **insertFront(element: T)** to insert an element at the front of this container.|
| Adding elements| Use **insertEnd(element: T)** to insert an element at the end of this container.|
| Accessing elements| Use **getFirst()** to obtain the value of the first element in this container, without removing it from the container.|
| Accessing elements| Use **getLast()** to obtain the value of the last element in this container, without removing it from the container.|
| Accessing elements| Use **popFirst()** to obtain the value of the first element in this container and remove it from the container.|
| Accessing elements| Use **popLast()** to obtain the value of the last element in this container and remove it from the container.|
| Accessing elements| Use **forEach(callbackFn:(value: T, index?: number, deque?: Deque<T>) => void, thisArg?: Object)** to traverse the elements in this container.|
| Accessing elements| Use **\[Symbol.iterator]():IterableIterator<T>** for data access.|
| Modifying elements| Use **forEach(callbackFn:(value: T, index?: number, deque?: Deque<T>)=> void, thisArg?: Object)** to modify an element in this container.|
| Deleting elements| Use **popFirst()** to remove the first element from this container.|
| Deleting elements| Use **popLast()** to remove the last element from this container.|
## Queue
[Queue](../reference/apis/js-apis-queue.md) can be used to construct a queue that follows the FIFO principle.
**Queue** uses generics and must be stored in a contiguous memory space. Its initial capacity is 8, and it has capacity doubled in each dynamic expansion.
The bottom layer of **Queue** is implemented by cyclic queues, delivering a high efficiency in enqueuing and dequeuing.
Unlike [Deque](../reference/apis/js-apis-deque.md), which supports insertion and removal at both the ends, **Queue** supports insertion at one end and removal at the other end.
You are advised to use **Queue** in FIFO scenarios.
**Queue** provides the following CRUD APIs.
| Operation| Description|
| ---------- | ------ |
| Adding elements| Use **add(element: T)** to add an element at the end of this container.|
| Accessing elements| Use **getFirst()** to obtain the value of the first element in this container, without removing it from the container.|
| Accessing elements| Use **pop()** to obtain the value of the first element in this container and remove it from the container.|
| Accessing elements| Use **forEach(callbackFn: (value: T, index?: number, queue?: Queue<T>) => void,thisArg?: Object)** to traverse the elements in this container.|
| Accessing elements| Use **\[Symbol.iterator]():IterableIterator<T>** for data access.|
| Modifying elements| Use **forEach(callbackFn:(value: T, index?: number, queue?: Queue<T>) => void,thisArg?: Object)** to modify an element in this container.|
| Deleting elements| Use **pop()** to remove the first element from this container.|
## Stack
[Stack](../reference/apis/js-apis-stack.md) can be used to construct a stack that follows the Last Out First In (LOFI) principle.
**Stack** uses generics and must be stored in a contiguous memory space. Its initial capacity is 8, and it increases capacity 1.5-fold in each dynamic expansion. The bottom layer of **Stack** is implemented based on arrays. It supports data insertion and removal at one end.
Unlike [Queue](../reference/apis/js-apis-queue.md), which is implemented based on the queue data structure and supports insertion at one end and removal at the other end, **Stack** supports insertion and removal at the same end.
You are advised to use **Stack** in LOFI scenarios.
**Stack** provides the following CRUD APIs.
| Operation| Description|
| ---------- | ------ |
| Adding elements| Use **push(item: T)** to add an element at the top of this container.|
| Accessing elements| Use **peek()** to obtain the value of the top element in this container, without removing it from the container.|
| Accessing elements| Use **pop()** to obtain the value of the top element in this container and remove it from the container.|
| Accessing elements| Use **forEach(callbackFn: (value: T, index?: number, stack?: Stack<T>) => void, thisArg?: Object)** to traverse the elements in this container.|
| Accessing elements| Use **\[Symbol.iterator]():IterableIterator<T>** for data access.|
| Accessing elements| Use **locate(element: T)** to obtain the index of the first occurrence of the specified element.|
| Modifying elements| Use **forEach(callbackFn:(value: T, index?: number, stack?: Stack<T>) => void, thisArg?: Object)** to modify an element in this container.|
| Deleting elements| Use **pop()** to remove the top element from this container.|
## Use of Linear Containers
Refer to the code snippet below to add, access, and modify elements in **ArrayList**, **Vector**, **Deque**, **Stack**, and **List**.
```js
// ArrayList
importArrayListfrom'@ohos.util.ArrayList';// Import the ArrayList module.
letarrayList=newArrayList();
arrayList.add('a');
arrayList.add(1);// Add an element.
console.info(`result: ${arrayList[0]}`);// Access an element.
arrayList[0]='one';// Modify an element.
console.info(`result: ${arrayList[0]}`);
// Vector
importVectorfrom'@ohos.util.Vector';// Import the Vector module.
letvector=newVector();
vector.add('a');
letb1=[1,2,3];
vector.add(b1);
vector.add(false);// Add an element.
console.info(`result: ${vector[0]}`);// Access an element.
console.info(`result: ${vector.getFirstElement()}`);// Access an element.
// Deque
importDequefrom'@ohos.util.Deque';// Import the Deque module.
letdeque=newDeque;
deque.insertFront('a');
deque.insertFront(1);// Add an element.
console.info(`result: ${deque[0]}`);// Access an element.
deque[0]='one';// Modify an element.
console.info(`result: ${deque[0]}`);
// Stack
importStackfrom'@ohos.util.Stack';// Import the Stack module.
letstack=newStack();
stack.push('a');
stack.push(1);// Add an element.
console.info(`result: ${stack[0]}`);// Access an element.
stack.pop();// Remove an element.
console.info(`result: ${stack.length}`);
// List
importListfrom'@ohos.util.List';// Import the List module.
letlist=newList;
list.add('a');
list.add(1);
letb2=[1,2,3];
list.add(b2);// Add an element.
console.info(`result: ${list[0]}`);// Access an element.
console.info(`result: ${list.get(0)}`);// Access an element.
Concurrency models are used to implement concurrent tasks in different scenarios. Common concurrency models are classified into shared memory models and message passing models.
A typical message passing model is actor. It provides a relatively high degree of concurrency while eliminating a series of complex and occasional issues caused by locks. For these reasons, ArkTS chooses the actor model.
Due to the memory isolation feature of the actor model, cross-thread serialization is required.
## Data Transfer Objects
Data objects that can be transferred are classified into the following types: [common objects](#common-objects), [transferable objects](#transferable-objects), [shared objects](#shared-objects), and [native binding objects](#native-binding-objects).
### Common Objects
The structured clone algorithm is used for serialization of common objects. This algorithm recursively transfers an object by clone. It supports more object types than other serialization algorithms.
The following object types are supported: basic types except Symbol, Date, String, RegExp, Array, Map, Set, Object (simple objects only, for example, objects created using **{}** or **new Object**), ArrayBuffer, and typedArray. (Note that only attributes can be transferred for common objects. Prototypes and methods cannot be transferred.)
### Transferable Objects
Transferable objects are serialized through address transfer. It transfers the ownership of an object of the ArrayBuffer type, rather than the content in it. After the ownership is transferred, the object becomes unavailable in the sender and can be used only in the receiver.
```js
// Define a transferable object.
letbuffer=newArrayBuffer(100);
```
### Shared Objects
A shared object is of the **SharedArrayBuffer** type, has a fixed length, and can store any type of data including numbers and strings.
An object of the SharedArrayBuffer type can be transferred between multiple threads. The objects before and after the transfer point to the same memory block, achieving memory sharing.
If multiple operations are simultaneously performed to modify data stored in an object of the SharedArrayBuffer type, you must use atomics to ensure data synchronization. Atomics ensure that the current operation is complete before the next operation starts.
```js
// Define a shared object, which uses atomics to ensure data synchronization.
letsharedBuffer=newSharedArrayBuffer(1024);
```
### Native Binding Objects
Native binding objects are provided by the system. They are bound to underlying system services and enables direct access to these services.
Currently, native bound objects that support serialization include [Context](../application-models/application-context-stage.md) and [RemoteObject](../reference/apis/js-apis-rpc.md#remoteobject).
The **Context** object provides the context information about an application component. It provides a way to access system services and resources so that the application component can interact with the system. For details about how to obtain context information, see [Context (Stage Model)](../application-models/application-context-stage.md).
The **RemoteObject** object implements remote communication. It transfers the reference of an object between processes so that these processes can share the status and methods of the object. The service provider must inherit this class. For details about how to create a **RemoteObject** object, see [RemoteObject](../reference/apis/js-apis-rpc.md#remoteobject).
## TaskPool and Worker
ArkTS provides two multithread concurrency capabilities: **TaskPool** and **Worker**, which differ in their implementation features and use cases. For details, see [Comparison Between TaskPool and Worker](taskpool-vs-worker.md).
Nonlinear containers implement a data structure that enables quick search. The bottom layer of nonlinear containers is implemented through hash tables or red-black trees. OpenHarmony provides the following nonlinear containers: **HashMap**, **HashSet**, **TreeMap**, **TreeSet**, **LightWeightMap**, **LightWeightSet**, and **PlainArray**. The types of **key** and **value** in nonlinear containers must meet the ECMA standard.
## HashMap
[HashMap](../reference/apis/js-apis-hashmap.md) is used to store a set of associated key-value (KV) pairs. In a hash map, each key is unique and corresponds to a value.
**HashMap** uses generics. In a hash map, a key is located based on its hash code. The initial capacity of a hash map is 16, and it has capacity doubled in each dynamic expansion. The bottom layer of **HashMap** is implemented based on a hash table. It uses chaining to avoid collisions in hash tables.
**HashMap** is faster in accessing data than [TreeMap](../reference/apis/js-apis-treemap.md), because the former accesses the keys based on the hash codes, whereas the latter stores and accesses the keys in sorted order.
[HashSet](../reference/apis/js-apis-hashset.md) is implemented based on **HashMap**. The input parameter of **HashMap** consists of **key** and **value**. In **HashSet**, only the **value** object is processed.
You are advised to use **HashMap** when you need to quickly access, remove, and insert KV pairs.
**HashMap** provides the following Create, Read, Update, and Delete (CRUD) APIs.
| Operation| Description|
| -------- | ------ |
| Adding elements| Use **set(key: K, value: V)** to add an element (a KV pair) to this container.|
| Accessing elements| Use **get(key: K)** to obtain the value of the specified key.|
| Accessing elements| Use **keys()** to return an iterator that contains all the keys in this container.|
| Accessing elements| Use **values()** to return an iterator that contains all the values in this container.|
| Accessing elements| Use **entries()** to return an iterator that contains all the elements in this container.|
| Accessing elements| Use **forEach(callbackFn: (value?: V, key?: K, map?: HashMap<K, V>) => void, thisArg?: Object)** to traverse the elements in this container.|
| Accessing elements| Use **\[Symbol.iterator]():IterableIterator<[K,V]>** for data access.|
| Modifying elements| Use **replace(key: K, newValue: V)** to change the value of the specified key.|
| Modifying elements| Use **forEach(callbackFn: (value?: V, key?: K, map?: HashMap<K, V>) => void, thisArg?: Object)** to modify an element in this container.|
| Deleting elements| Use **remove(key: K)** to remove an element with the specified key.|
| Deleting elements| Use **clear()** to clear this container.|
## HashSet
[HashSet](../reference/apis/js-apis-hashset.md) is used to store a set of values, each of which is unique in a hash set.
**HashSet** uses generics. In a hash set, a value is located based on its hash code. The initial capacity of a hash set is 16, and it has capacity doubled in each dynamic expansion. The type of **value** must comply with the ECMA standard. The bottom layer of **HashSet** is implemented based on a hash table. It uses chaining to avoid collisions in hash tables.
**HashSet** is implemented based on [HashMap](../reference/apis/js-apis-hashmap.md). In **HashSet**, only the **value** object is processed.
Unlike [TreeSet](../reference/apis/js-apis-treeset.md), which stores and accesses data in sorted order, **HashSet** stores data in a random order. This means that **HashSet** may use a different order when storing and accessing elements. Both of them allows only unique elements. However, null values are allowed in **HashSet**, but not allowed in **TreeSet**.
You are advised to use **HashSet** when you need a set that has only unique elements or need to deduplicate a set.
**HashSet** provides the following CRUD APIs.
| Operation| Description|
| -------- | ------ |
| Adding elements| Use **add(value: T)** to add a value to this container.|
| Accessing elements| Use **values()** to return an iterator that contains all the values in this container.|
| Accessing elements| Use **entries()** to return an iterator that contains all the elements in this container.|
| Accessing elements| Use **forEach(callbackFn: (value?: T, key?: T, set?: HashSet\<T>) => void, thisArg?: Object)** to traverse the elements in this container.|
| Accessing elements| Use **\[Symbol.iterator]():IterableIterator<T>** for data access.|
| Modifying elements| Use **forEach(callbackFn: (value?: T, key?: T, set?: HashSet\<T>) => void, thisArg?: Object)** to change a value in this container.|
| Deleting elements| Use **remove(value: T)** to remove a value.|
| Deleting elements| Use **clear()** to clear this container.|
## TreeMap
[TreeMap](../reference/apis/js-apis-treemap.md) is used to store a set of associated KV pairs. In a tree map, each key is unique and corresponds to a value.
**TreeMap** uses generics, and the keys in a tree map are ordered. The bottom layer of **TreeMap** is a binary tree, which supports quick search of KV pairs through the children (left child and right child) of the tree. The type of **key** must comply with the ECMA standard. Keys in a tree map are stored in order. The bottom layer of **TreeMap** is implemented based on the red-black tree and supports quick insertion and removal.
[HashMap](../reference/apis/js-apis-hashmap.md) is faster in accessing data than **TreeMap**, because the former accesses the keys based on the hash codes, whereas the latter stores and accesses the keys in sorted order.
You are advised to use **TreeMap** when you need to store KV pairs in sorted order.
**TreeMap** provides the following CRUD APIs.
| Operation| Description|
| ------- | ------ |
| Adding elements| Use **set(key: K, value: V)** to add an element (a KV pair) to this container.|
| Accessing elements| Use **get(key: K)** to obtain the value of the specified key.|
| Accessing elements| Use **getFirstKey()** to obtain the first key in this container.|
| Accessing elements| Use **getLastKey()** to obtain the last key in this container.|
| Accessing elements| Use **keys()** to return an iterator that contains all the keys in this container.|
| Accessing elements| Use **values()** to return an iterator that contains all the values in this container.|
| Accessing elements| Use **entries()** to return an iterator that contains all the elements in this container.|
| Accessing elements| Use **forEach(callbackFn: (value?: V, key?: K, map?: TreeMap<K, V>) => void, thisArg?: Object)** to traverse the elements in this container.|
| Accessing elements| Use **\[Symbol.iterator]():IterableIterator\<[K,V]>** for data access.|
| Modifying elements| Use **replace(key: K, newValue: V)** to change the value of the specified key.|
| Modifying elements| Use **forEach(callbackFn: (value?: V, key?: K, map?: TreeMap<K, V>) => void, thisArg?: Object)** to modify an element in this container.|
| Deleting elements| Use **remove(key: K)** to remove an element with the specified key.|
| Deleting elements| Use **clear()** to clear this container.|
## TreeSet
[TreeSet](../reference/apis/js-apis-treeset.md) is used to store a set of values, each of which is unique in a tree set.
**TreeSet** uses generics, and the values in a tree set are ordered. The bottom layer of **TreeSet** is a binary tree, which supports quick search of a value through the children (left child and right child) of the tree. The type of **value** must meet the ECMA standard. Values in a tree set are stored in order. The bottom layer of **TreeSet** is implemented based on the red-black tree and supports quick insertion and removal.
**TreeSet** is implemented based on [TreeMap](../reference/apis/js-apis-treemap.md). In **TreeSet**, only **value** objects are processed. **TreeSet** can be used to store values, each of which must be unique.
[HashSet](../reference/apis/js-apis-hashset.md) stores data in a random order, whereas **TreeSet** stores data in sorted order. Both of them allows only unique elements. However, null values are allowed in **HashSet**, but not allowed in **TreeSet**.
You are advised to use **TreeSet** when you need to store data in sorted order.
**TreeSet** provides the following CRUD APIs.
| Operation| Description|
| -------- | ------ |
| Adding elements| Use **add(value: T)** to add a value to this container.|
| Accessing elements| Use **values()** to return an iterator that contains all the values in this container.|
| Accessing elements| Use **entries()** to return an iterator that contains all the elements in this container.|
| Accessing elements| Use **getFirstValue()** to obtain the first value in this container.|
| Accessing elements| Use **getLastValue()** to obtain the last value in this container.|
| Accessing elements| Use **forEach(callbackFn: (value?: T, key?: T, set?: TreeSet\<T>) => void, thisArg?: Object)** to traverse the elements in this container.|
| Accessing elements| Use **\[Symbol.iterator]():IterableIterator<T>** for data access.|
| Modifying elements| Use **forEach(callbackFn: (value?: T, key?: T, set?: TreeSet\<T>) => void, thisArg?: Object)** to change a value in this container.|
| Deleting elements| Use **remove(value: T)** to remove a value.|
| Deleting elements| Use **clear()** to clear this container.|
## LightWeightMap
[LightWeightMap](../reference/apis/js-apis-lightweightmap.md) is used to store a set of associated KV pairs. In a lightweight map, each key is unique and corresponds to a value. **LightWeightMap** uses generics and a more lightweight structure. It uses the hash code to uniquely identify a key at the bottom layer. It uses linear probing to avoid collisions. In a lightweight map, a key is located by using the hash code and binary search algorithm. The hash code is stored in an array and mapped to a key and its value in another array. The type of **key** must comply with the ECMA standard.
The default initial capacity of a lightweight map is 8, and it has capacity doubled in each expansion.
Compared with [HashMap](../reference/apis/js-apis-hashmap.md), which can also store KV pairs, **LightWeightMap** occupies less memory.
You are advised to use **LightWeightMap** when you need to store and access **KV pairs**.
**LightWeightMap** provides the following CRUD APIs.
| Operation| Description|
| -------- | ------ |
| Adding elements| Use **set(key: K, value: V)** to add an element (a KV pair) to this container.|
| Accessing elements| Use **get(key: K)** to obtain the value of the specified key.|
| Accessing elements| Use **getIndexOfKey(key: K)** to obtain the index of the specified key.|
| Accessing elements| Use **getIndexOfValue(value: V)** to obtain the index of the first occurrence of the specified value.|
| Accessing elements| Use **keys()** to return an iterator that contains all the keys in this container.|
| Accessing elements| Use **values()** to return an iterator that contains all the values in this container.|
| Accessing elements| Use **entries()** to return an iterator that contains all the elements in this container.|
| Accessing elements| Use **getKeyAt(index: number)** to obtain the key of an element at a given position (specified by **index**).|
| Accessing elements| Use **getValueAt(index: number)** to obtain the value of an element at a given position (specified by **index**).|
| Accessing elements| Use **forEach(callbackFn: (value?: V, key?: K, map?: LightWeightMap<K, V>) => void, thisArg?: Object)** to traverse the elements in this container.|
| Accessing elements| Use **\[Symbol.iterator]():IterableIterator<[K,V]>** for data access.|
| Modifying elements| Use **setValueAt(index: number, newValue: V)** to change the value of an element at a given position (specified by **index**).|
| Modifying elements| Use **forEach(callbackFn: (value?: V, key?: K, map?: LightWeightMap<K, V>) => void, thisArg?: Object)** to modify an element in this container.|
| Deleting elements| Use **remove(key: K)** to remove an element with the specified key.|
| Deleting elements| Use **removeAt(index: number)** to remove an element at a given position (specified by **index**).|
| Deleting elements| Use **clear()** to clear this container.|
## LightWeightSet
[LightWeightSet](../reference/apis/js-apis-lightweightset.md) is used to store a set of values, each of which is unique in a lightweight set.
**LightWeightSet** uses generics and a lightweight structure. Its default initial capacity is 8, and it has capacity doubled in each expansion. In a lightweight set, a value is located by using the hash code and binary search algorithm. The hash code is stored in an array and mapped to a value in another array. The type of **value** must comply with the ECMA standard.
**LightWeightSet** uses the hash code to uniquely identify a value at the bottom layer. It uses linear probing to avoid collisions and adopts the binary search algorithm.
Compared with [HashSet](../reference/apis/js-apis-hashset.md), which can also store values, **LightWeightSet** occupies less memory.
You are advised to use **LightWeightSet** when you need a set that has only unique elements or need to deduplicate a set.
**LightWeightSet** provides the following CRUD APIs.
| Operation| Description|
| -------- | ------ |
| Adding elements| Use **add(obj: T)** to add a value to this container.|
| Accessing elements| Use **getIndexOf(key: T)** to obtain the index of a key.|
| Accessing elements| Use **values()** to return an iterator that contains all the values in this container.|
| Accessing elements| Use **entries()** to return an iterator that contains all the elements in this container.|
| Accessing elements| Use **getValueAt(index: number)** to obtain the value of an element at a given position (specified by **index**).|
| Accessing elements| Use **forEach(callbackFn: (value?: T, key?: T, set?: LightWeightSet\<T>) => void, thisArg?: Object)** to traverse the elements in this container.|
| Accessing elements| Use **\[Symbol.iterator]():IterableIterator<T>** for data access.|
| Modifying elements| Use **forEach(callbackFn: (value?: T, key?: T, set?: LightWeightSet\<T>) => void, thisArg?: Object)** to change a value in this container.|
| Deleting elements| Use **remove(key: K)** to remove an element with the specified key.|
| Deleting elements| Use **removeAt(index: number)** to remove an element at a given position (specified by **index**).|
| Deleting elements| Use **clear()** to clear this container.|
## PlainArray
[PlainArray](../reference/apis/js-apis-plainarray.md) is used to store a set of associated KV pairs. In a plain array, each key is unique, corresponds to a value, and is of the number type. **PlainArray** uses generics and a more lightweight structure. In a plain array, a key is located by using the binary search algorithm and is mapped to a value in another array.
The default initial capacity of a plain array is 16, and it has capacity doubled in each expansion.
Both **PlainArray** and [LightWeightMap](../reference/apis/js-apis-lightweightmap.md) are used to store KV pairs in the lightweight structure. However, the key type of **PlainArray** can only be **number**.
You are advised to use PlainArray when you need to store KV pairs whose keys are of the number type.
**PlainArray** provides the following CRUD APIs.
| Operation| Description|
| -------- | ------ |
| Adding elements| Use **add(key: number,value: T)** to add an element (a KV pair) to this container.|
| Accessing elements| Use **get(key: number)** to obtain the value of the specified key.|
| Accessing elements| Use **getIndexOfKey(key: number)** to obtain the index of the specified key.|
| Accessing elements| Use **getIndexOfValue(value: T)** to obtain the index of the specified value.|
| Accessing elements| Use **getKeyAt(index: number)** to obtain the key of an element at a given position (specified by **index**).|
| Accessing elements| Use **getValueAt(index: number)** to obtain the value of an element at a given position (specified by **index**).|
| Accessing elements| Use **forEach(callbackFn: (value: T, index?: number, PlainArray?: PlainArray\<T>) => void, thisArg?: Object)** to traverse the elements in this container.|
| Accessing elements| Use **\[Symbol.iterator]():IterableIterator<[number, T]>** for data access.|
| Modifying elements| Use **setValueAt(index:number, value: T)** to change the value of an element at a given position (specified by **index**).|
| Modifying elements| Use **forEach(callbackFn: (value: T, index?: number, PlainArray?: PlainArray\<T>) => void, thisArg?: Object)** to modify an element in this container.|
| Deleting elements| Use **remove(key: number)** to remove an element with the specified key.|
| Deleting elements| Use **removeAt(index: number)** to remove an element at a given position (specified by **index**).|
| Deleting elements| Use **removeRangeFrom(index: number, size: number)** to remove elements in a specified range.|
| Deleting elements| Use **clear()** to clear this container.|
## Use of Nonlinear Containers
Refer to the code snippet below to add, access, and modify elements in **HashMap**, **TreeMap**, **LightWeightMap**, **Stack**, and **PlainArray**.
```js
// HashMap
importHashMapfrom'@ohos.util.HashMap';// Import the HashMap module.
lethashMap=newHashMap();
hashMap.set('a',123);
hashMap.set(4,123);// Add an element.
console.info(`result: ${hashMap.hasKey(4)}`);// Check whether an element is contained.
console.info(`result: ${hashMap.get('a')}`);// Access an element.
// TreeMap
importTreeMapfrom'@ohos.util.TreeMap';// Import the TreeMap module.
lettreeMap=newTreeMap();
treeMap.set('a',123);
treeMap.set('6',356);// Add an element.
console.info(`result: ${treeMap.get('a')}`);// Access an element.
console.info(`result: ${treeMap.getFirstKey()}`);// Access the first element.
console.info(`result: ${treeMap.getLastKey()}`);// Access the last element.
// LightWeightMap
importLightWeightMapfrom'@ohos.util.LightWeightMap';// Import the LightWeightMap module.
letlightWeightMap=newLightWeightMap();
lightWeightMap.set('x',123);
lightWeightMap.set('8',356);// Add an element.
console.info(`result: ${lightWeightMap.get('a')}`);// Access an element.
console.info(`result: ${lightWeightMap.get('x')}`);// Access an element.
console.info(`result: ${lightWeightMap.getIndexOfKey('8')}`);// Access an element.
// PlainArray
importPlainArrayfrom'@ohos.util.PlainArray'// Import the PlainArray module.
letplainArray=newPlainArray();
plainArray.add(1,'sdd');
plainArray.add(2,'sff');// Add an element.
console.info(`result: ${plainArray.get(1)}`);// Access an element.
console.info(`result: ${plainArray.getKeyAt(1)}`);// Access an element.
Asynchronous concurrency provided by Promise and async/await is applicable to the development of a single I/O task. The following uses the asynchronous concurrency capability to write a file as an example.
console.error(`Failed to write data. Code is ${err.code}, message is ${err.message}`);
})
}
```
2. Use the asynchronous capability to invoke the single I/O task. For details about how to obtain **filePath** in the example, see [Obtaining Application File Paths](../application-models/application-context-stage.md#obtaining-application-file-paths).
Synchronous tasks are executed in order among multiple threads. For example, as a synchronization primitive, locks prevent data contention.
To implement synchronous tasks, you must consider the collaboration and synchronization between multiple threads and ensure the correctness of data and the correct execution of programs.
If synchronous tasks are independent of each other, you are advised to use **TaskPool**, since it focuses on single independent tasks. For example, a series of imported static methods or methods implemented in singletons are independent. If synchronous tasks are associated with each other, use **Worker**, for example, methods implemented in class objects (not singleton class objects).
## Using TaskPool to Process Independent Synchronous Tasks
**TaskPool** is recommended for scheduling independent synchronous tasks. Typical synchronous tasks are those using static methods. If a unique handle or class object constructed using a singleton points to multiple tasks and these tasks can be used between different worker threads, you can also use **TaskPool**.
1. Define a concurrency function that internally calls the synchronous methods.
2. Create a task, execute the task through **TaskPool**, and perform operations on the asynchronous result. Create a [task](../reference/apis/js-apis-taskpool.md#task) and call [execute()](../reference/apis/js-apis-taskpool.md#taskpoolexecute-1) to execute the task synchronously.
3. Perform concurrent operations.
Simulate a singleton class that contains synchronous calls.
```ts
// handle.ts code
exportdefaultclassHandle{
staticgetInstance(){
// Return a singleton object.
}
staticsyncGet(){
// Synchronous getter.
return;
}
staticsyncSet(num:number){
// Synchronous setter.
return;
}
}
```
Use **TaskPool** to call the related synchronous methods.
```ts
// Index.ets code
importtaskpoolfrom'@ohos.taskpool';
importHandlefrom'./Handle';// Return a static handle.
// Step 1: Define a concurrency function that internally calls the synchronous methods.
@Concurrent
functionfunc(num:number){
// Call the synchronous wait implemented in a static class object.
Handle.syncSet(num);
// Alternatively, call the synchronous wait implemented in a singleton object.
Handle.getInstance().syncGet();
returntrue;
}
// Step 2: Create and execute a task.
asyncfunctionasyncGet(){
// Create a task and pass in the function func.
lettask=newtaskpool.Task(func,1);
// Execute the task and obtain the result res.
letres=awaittaskpool.execute(task);
// Perform operations on the synchronous result.
console.info(String(res));
}
@Entry
@Component
structIndex{
@Statemessage:string='Hello World';
build(){
Row(){
Column(){
Text(this.message)
.fontSize(50)
.fontWeight(FontWeight.Bold)
.onClick(()=>{
// Step 3: Perform concurrent operations.
asyncGet();
})
}
.width('100%')
.height('100%')
}
}
}
```
## Using Worker to Process Associated Synchronous Tasks
Use **Worker** when you want to schedule a series of synchronous tasks using the same handle or depending on the same class object.
1. Create a **Worker** object in the main thread and receive messages from the worker thread.
**TaskPool** and **Worker** provide a multithread running environment for applications to process time-consuming computing tasks or resource intensive tasks, preventing these tasks from blocking the main thread. This maximizes system utilization, reduces overall resource consumption, and improves overall system performance.
This topic compares **TaskPool** with **Worker** from two aspects: [implementation features](#implementation-feature-comparison) and [use cases](#use-case-comparison). It also describes their operating mechanisms and precautions.
## Implementation Feature Comparison
**Table 1** Comparison between TaskPool and Worker in implementation features
| Item| TaskPool | Worker |
| -------- | -------- | -------- |
| Memory model| Threads are isolated from each other, and memory is not shared.| Threads are isolated from each other, and memory is not shared.|
| Parameter passing mechanism| The structured clone algorithm is used for serialization and deserialization.<br>ArrayBuffer and SharedArrayBuffer are used for parameter passing and sharing.| The structured clone algorithm is used for serialization and deserialization.<br>ArrayBuffer and SharedArrayBuffer are used for parameter passing and sharing.|
| Parameter passing| Parameters are directly passed in, without being encapsulated.| Only one parameter can be carried in a message object. Therefore, you must encapsulate excess parameters.|
| Method invocation| Methods are directly passed in and called.| Messages are passed in the worker thread and the corresponding methods are called.|
| Return value| A value is returned by default after asynchronous calling.| Messages proactively sent must be parsed and assigned by calling **onmessage()**.|
| Lifecycle| The task pool manages its own lifecycle, without considering the load.| You are required to manage the number and lifecycle of worker threads.|
| Maximum number of task pools| The number is automatically managed, rather than being manually configured.| A maximum of eight worker threads are supported.|
| Maximum task execution duration| There is no restriction.| There is no restriction.|
| Task priority setting| Setting the task priority is not supported.| Setting the task priority is not supported.|
| Task cancellation| Tasks waiting in the task queue can be canceled.| Tasks waiting in the task queue cannot be canceled.|
## Use Case Comparison
Both **TaskPool** and **Worker** support multithread concurrency. **TaskPool** is oriented to thread-level independent tasks. **Worker** is oriented to threads and supports thread execution for a long time.
Common use cases are as follows:
- Use **Worker** for a series of associated synchronous tasks. For example, use **Worker** for a series of database operations, since the same handle is required.
- Use **TaskPool** for a task that needs to be canceled frequently. For example, in the large image browsing scenario in Gallery, both images on the left and right sides of the current image are cached. When the user slides to the next image, a cache task on one side needs to be canceled. In this case, use **TaskPool**.
- Use **TaskPool** for a large number of tasks or tasks with scattered scheduling points. For example, a large-scale application with multiple modules has multiple time-consuming tasks, and it is inconvenient to use eight worker threads to manage load. In this case, **TaskPool** is recommended.
## TaskPool Operating Mechanism
**Figure 1** TaskPool operating mechanism

With **TaskPool**, you can encapsulate tasks in the main thread and throw the tasks to the task queue. The system selects proper worker threads to distribute and execute the tasks, and then returns the result to the main thread. **TaskPool** provides APIs to execute and cancel tasks. A maximum of 4 **TaskPool** worker threads are supported.
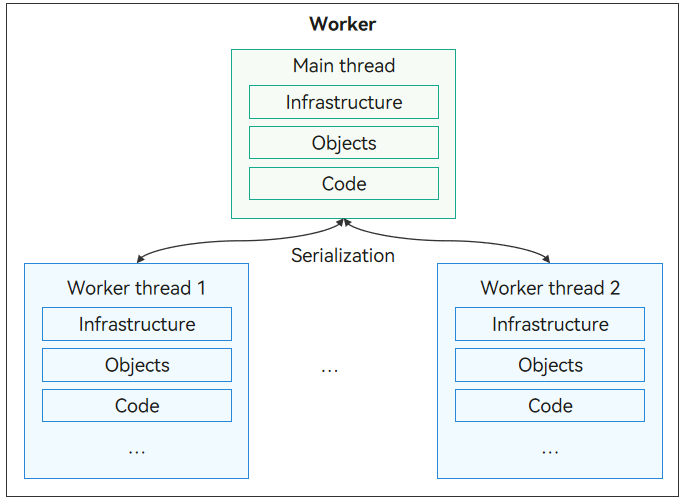
## Worker Operating Mechanism
**Figure 2** Worker operating mechanism

The thread that creates the worker thread is referred to as the host thread (not necessarily the main thread, since a worker thread can also create a worker subthread). A worker thread is also named an actor thread. Each worker thread has an independent instance from the host thread, including the infrastructure, object, and code segment. The worker thread communicates with the host thread by means of message exchange. They use the serialization technique to exchange commands and data.
## Precautions for TaskPool
- A task function must be decorated with **\@Concurrent** and can be used only in .ets files.
- A task function must be a common function or async function, but not a class member function or anonymous function.
- A task function can use imported variables and input parameter variables only in a project created on the stage model. In a project created on the FA model, it can use input parameter variables only.
- Input parameter types in a task function must be those supported by serialization. For details, see [Common Objects](multi-thread-concurrency-overview.md#common-objects).
- The context objects in different threads are different. Therefore, **TaskPool** worker threads can use only thread-safe libraries, rather than UI-related non-thread-safe libraries.
- A maximum of 16 MB data can be serialized at a time.
## Precautions for Worker
- The rules for passing in the **Worker.ts** path during the worker creation vary in different API versions. For details, see [Precautions for File Paths](#precautions-for-file-paths).
- After a worker thread is created, you must manually manage its lifecycle. A maximum of eight worker threads can run simultaneously. For details, see [Lifecycle Precautions](#lifecycle-precautions).
- Modules of the [ability type](../quick-start/application-package-structure-stage.md) support **Worker**, but modules of the [library type](../quick-start/application-package-structure-stage.md) do not support **Worker**.
- When creating a worker thread, the **Worker.ts** file of another module cannot be used. This means that a worker cannot be called across modules.
- The context objects in different threads are different. Therefore, **Worker** threads can use only thread-safe libraries, rather than UI-related non-thread-safe libraries.
- A maximum of 16 MB data can be serialized.
### Precautions for File Paths
Before calling an API of the **Worker** module, you must create a **Worker** instance. The constructor function varies in different API versions.
```js
// Use the following function in API version 9 and later versions:
constworker1=newworker.ThreadWorker(scriptURL);
// Use the following function in API version 8 and earlier versions:
constworker1=newworker.Worker(scriptURL);
```
The **Worker.ts** file path (specified by **scriptURL**) must be passed in the constructor function. By default, the **workers** directory (upper-level directory of the **Worker.ts** file) is at the same level as the **pages** directory.
**Stage Model**
The following is an example of **scriptURL** in the constructor function:
```js
// Method 1
// In the stage model, the workers directory is at the same level as the pages directory in the entry module.
constworker1=newworker.ThreadWorker('entry/ets/workers/MyWorker.ts',{name:"first worker in Stage model"});
// In the stage model, the workers directory is a child directory of the pages directory in the entry module.
// In the stage model, the workers directory is at the same level as the pages directory in the entry module, and bundlename is com.example.workerdemo.
// In the stage model, the workers directory is a child directory of the pages directory in the entry module, and bundlename is com.example.workerdemo.
- Creating and terminating worker threads consume performance. Therefore, you are advised to manage available workers and reuse them. The worker threads keep running even when they are idle. Therefore, when a worker thread is not required, call [terminate()](../reference/apis/js-apis-worker.md#terminate9) interface or [parentPort.close()](../reference/apis/js-apis-worker.md#close9) to destroy it. If a worker thread is destroyed or being destroyed, an error is thrown when it is called.
- A maximum of eight worker threads can co-exist.
- In API version 8 and earlier versions, when the number of worker threads exceeds the upper limit, the error "Too many workers, the number of workers exceeds the maximum." is thrown.
- Since API version 9, when the number of worker threads exceeds the upper limit, the error "Worker initialization failure, the number of workers exceeds the maximum." is thrown.
Converting XML text into JavaScript objects makes it easier to process and manipulate data. In addition, JavaScript objects are more suitable than XML text for JavaScript applications.
The common library provides the **ConvertXML** class to convert XML text into JavaScript objects. The input is XML strings and conversion options, and the output is a JavaScript object. For details about the conversion options, see the API reference [@ohos.convertxml (XML-to-JavaScript Conversion)](../reference/apis/js-apis-convertxml.md).
## Precautions
To ensure successful XML parsing and conversion, the input XML data must comply with the standard format.
## How to Develop
The following steps walk you through on how to convert an XML file into a JavaScript object to obtain the tag values.
1. Import the **convertxml** module.
```js
importconvertxmlfrom'@ohos.convertxml';
```
2. Pass in an XML file to be converted and set conversion options.
```js
letxml=
'<?xml version="1.0" encoding="utf-8"?>'+
'<note importance="high" logged="true">'+
' <title>Happy</title>'+
' <todo>Work</todo>'+
' <todo>Play</todo>'+
'</note>';
letoptions={
// trim: false, indicating that spaces before and after the text are not deleted after conversion.
// declarationKey: "_declaration", indicating that _declaration is used to identify the file declaration after conversion.
// instructionKey: "_instruction", indicating that _instruction is used to identify instructions after conversion.
// attributesKey: "_attributes", indicating that _attributes is used to identify attributes after conversion.
// textKey: "_text", indicating that _text is used to identify tag values after conversion.
// cdataKey: "_cdata", indicating that _cdata is used to identify unparsed data after conversion.
// docTypeKey: "_doctype", indicating that _doctype is used to identify documents after conversion.
// commentKey: "_comment", indicating that _comment is used to identify comments after conversion.
// parentKey: "_parent", indicating that _parent is used to identify parent classes after conversion.
// typeKey: "_type", indicating that _type is used to identify types after conversion.
// nameKey: "_name", indicating that _name is used to identify tag names after conversion.
// elementsKey: "_elements", indicating that _elements is used to identify elements after conversion.
trim:false,
declarationKey:"_declaration",
instructionKey:"_instruction",
attributesKey:"_attributes",
textKey:"_text",
cdataKey:"_cdata",
docTypeKey:"_doctype",
commentKey:"_comment",
parentKey:"_parent",
typeKey:"_type",
nameKey:"_name",
elementsKey:"_elements"
}
```
3. Call the conversion function and print the result.
```js
letconv=newconvertxml.ConvertXML();
letresult=conv.convertToJSObject(xml,options);
letstrRes=JSON.stringify(result);// Convert the JavaScript object into a JSON string for explicit output.
console.info(strRes);
// Alternatively, directly process the JavaScript object to obtain the tag values.
lettitle=result['_elements'][0]['_elements'][0]['_elements'][0]['_text'];// Parse the value of the <title> tag.
lettodo=result['_elements'][0]['_elements'][1]['_elements'][0]['_text'];// Parse the value of the <todo> tag.
lettodo2=result['_elements'][0]['_elements'][2]['_elements'][0]['_text'];// Parse the value of the <todo> tag.
XML can be used as a data exchange format, which is supported by a wealth of systems and applications. For example, web services can transfer structured data in XML format.
XML can also be used as a message passing format for communication between nodes in a distributed system.
## Precautions
- XML tags must appear in pairs: one start tag and one end tag.
- XML tags are case sensitive. The start tag and end tag must use the same case.
## How to Develop
The **xml** module provides the **XmlSerializer** class to generate XML files. The input is an object of the ArrayBuffer or DataView type with a fixed length, which is used to store the output XML data.
You can call different to write different types of content. For example, call **startElement(name: string)** to write the start tag and **setText(text: string)** to write a tag value.
For details about the APIs of the **XML** module, see [@ohos.xml (XML Parsing and Generation)](../reference/apis/js-apis-xml.md).
The following steps walk you through on how to generate an XML file.
1. Import the modules.
```js
importxmlfrom'@ohos.xml';
importutilfrom'@ohos.util';
```
2. Create a buffer and create an **XmlSerializer** object, either based on an object of the ArrayBuffer or DataView type.
```js
// 1. Create an XmlSerializer object based on an object of the ArrayBuffer type.
letarrayBuffer=newArrayBuffer(2048);// Create a 2048-byte object of the ArrayBuffer type.
letthatSer=newxml.XmlSerializer(arrayBuffer);// Create an XmlSerializer object based on the object of the ArrayBuffer type.
// 2. Create an XmlSerializer object based on an object of the DataView type.
letarrayBuffer=newArrayBuffer(2048);// Create a 2048-byte object of the ArrayBuffer type.
letdataView=newDataView(arrayBuffer);// Use an object of the DataView type to operate the object of the ArrayBuffer type.
letthatSer=newxml.XmlSerializer(dataView);// Create an XmlSerializer object based on the object of the DataView type.
```
3. Call the functions to generate an XML file.
```js
thatSer.setDeclaration();// Write the XML file declaration.
thatSer.startElement('bookstore');// Write the start flag.
thatSer.startElement('book');// Write the start tag of a nested element.
thatSer.setAttributes('category','COOKING');// Write the attributes and attribute values.
thatSer.startElement('title');
thatSer.setAttributes('lang','en');
thatSer.setText('Everyday');// Write the tag value.
thatSer.endElement();// Write the end flag.
thatSer.startElement('author');
thatSer.setText('Giada');
thatSer.endElement();
thatSer.startElement('year');
thatSer.setText('2005');
thatSer.endElement();
thatSer.endElement();
thatSer.endElement();
```
4. Use **Uint8Array** to operate the object of the ArrayBuffer type, and use **TextDecoder** to decode the Uint8Array.
```js
letview=newUint8Array(arrayBuffer);// Use Uint8Array to read data from the object of the ArrayBuffer type.
lettextDecoder=util.TextDecoder.create();// Call the TextDecoder class of the util module.
letres=textDecoder.decodeWithStream(view);// Decode the view.
Extensible Markup Language (XML) is a markup language used to describe data. It aims to provide a common way to transmit and store data, especially data frequently used in web applications. XML does not predefine tags. As a result, it is more flexible and widely used.
An XML file consists of elements, attributes, and content.
- An element refers to a tag pair that contains text, attributes, or other elements.
- Attributes provide additional information about an element.
- Content is the data or sub-element contained in an element.
XML supports the use of XML Schema Definition (XSD) or Document Type Definition (DTD) for defining the document structure. This allows you to customize rules to verify whether an XML document is in the expected format.
XML also supports features such as namespaces, entity references, comments, and processing instructions, making it easy to adapt to diverse data requirements.
The common library provides XML-related basic capabilities, including [XML generation](xml-generation.md), [XML parsing](xml-parsing.md), and [XML conversion](xml-conversion.md).
Data transferred in XML format must be parsed in actual use. Generally, three types of elements need to be parsed, as described in [Parsing XML Tags and Tag Values](#parsing-xml-tags-and-tag-values), [Parsing XML Attributes and Attribute Values](#parsing-xml-attributes-and-attribute-values), and [Parsing XML Event Types and Element Depths](#parsing-xml-event-types-and-element-depths).
The **xml** module provides the **XmlPullParser** class to parse XML files. The input is an object of the ArrayBuffer or DataView type containing XML text, and the output is the parsed information.
**Table 1** XML parsing options
| Name| Type| Mandatory| Description|
| -------- | -------- | -------- | -------- |
| supportDoctype | boolean | No| Whether to ignore the document type. The default value is **false**, indicating that the document type is parsed.|
| ignoreNameSpace | boolean | No| Whether to ignore the namespace. The default value is **false**, indicating that the namespace is parsed.|
| tagValueCallbackFunction | (name: string, value: string) => boolean | No| Callback used to return **tagValue**, which consists of a tag and its value. The default value is **null**, indicating that XML tags and tag values are not parsed.|
| attributeValueCallbackFunction | (name: string, value: string) => boolean | No| Callback used to return **attributeValue**, which consists of an attribute and its value. The default value is **null**, indicating that XML attributes and attribute values are not parsed.|
| tokenValueCallbackFunction | (eventType: EventType, value: ParseInfo) => boolean | No| Callback used to return **tokenValue**, which consists of the event type and the attributes of **parseInfo**. The default value is **null**, indicating that the event type and the attributes of **parseInfo** are not parsed.|
## Precautions
- To ensure successful XML parsing and conversion, the input XML data must comply with the standard format.
- Currently, parsing a given node is not supported.
## Parsing XML Tags and Tag Values
1. Import the modules.
```js
importxmlfrom'@ohos.xml';
importutilfrom'@ohos.util';// Use the API provided by the util module to encode the file.
```
2. Create an **XmlPullParser** object.
The **XmlPullParser** object can be created based on an object of the ArrayBuffer or DataView type.
```js
letstrXml=
'<?xml version="1.0" encoding="utf-8"?>'+
'<note importance="high" logged="true">'+
'<title>Play</title>'+
'<lens>Work</lens>'+
'</note>';
lettextEncoder=newutil.TextEncoder();
letarrBuffer=textEncoder.encodeInto(strXml);// Encode the data to prevent garbled characters.
// 1. Create an XmlPullParser object based on an object of the ArrayBuffer type.
{kind=link}
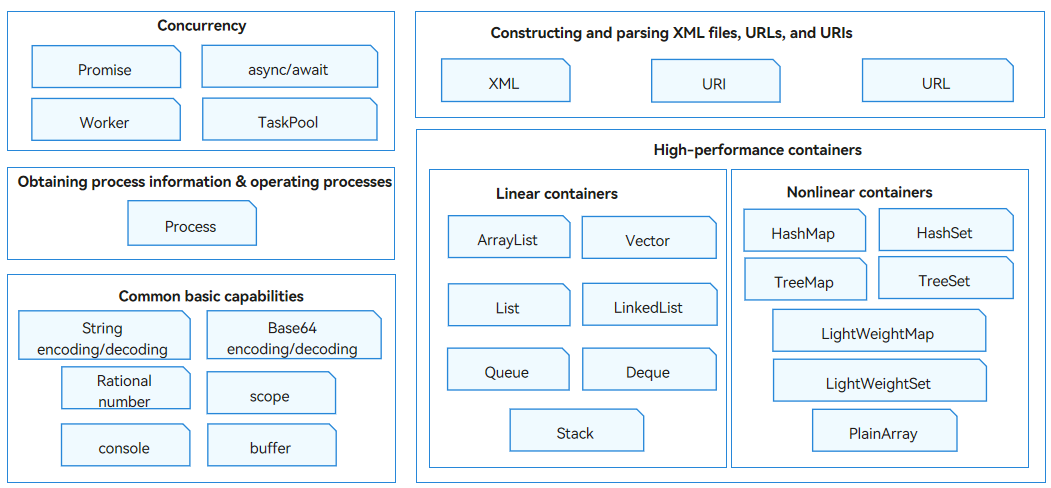
{kind=link}
{kind=link}

{kind=link}