!15868 添加AppFreeze日志分析文档
Merge pull request !15868 from mgceshuang/master
Showing
{kind=link}
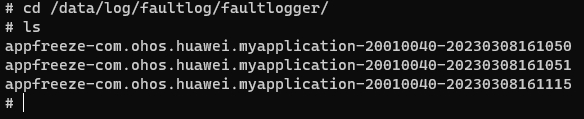
35.9 KB
{kind=link}
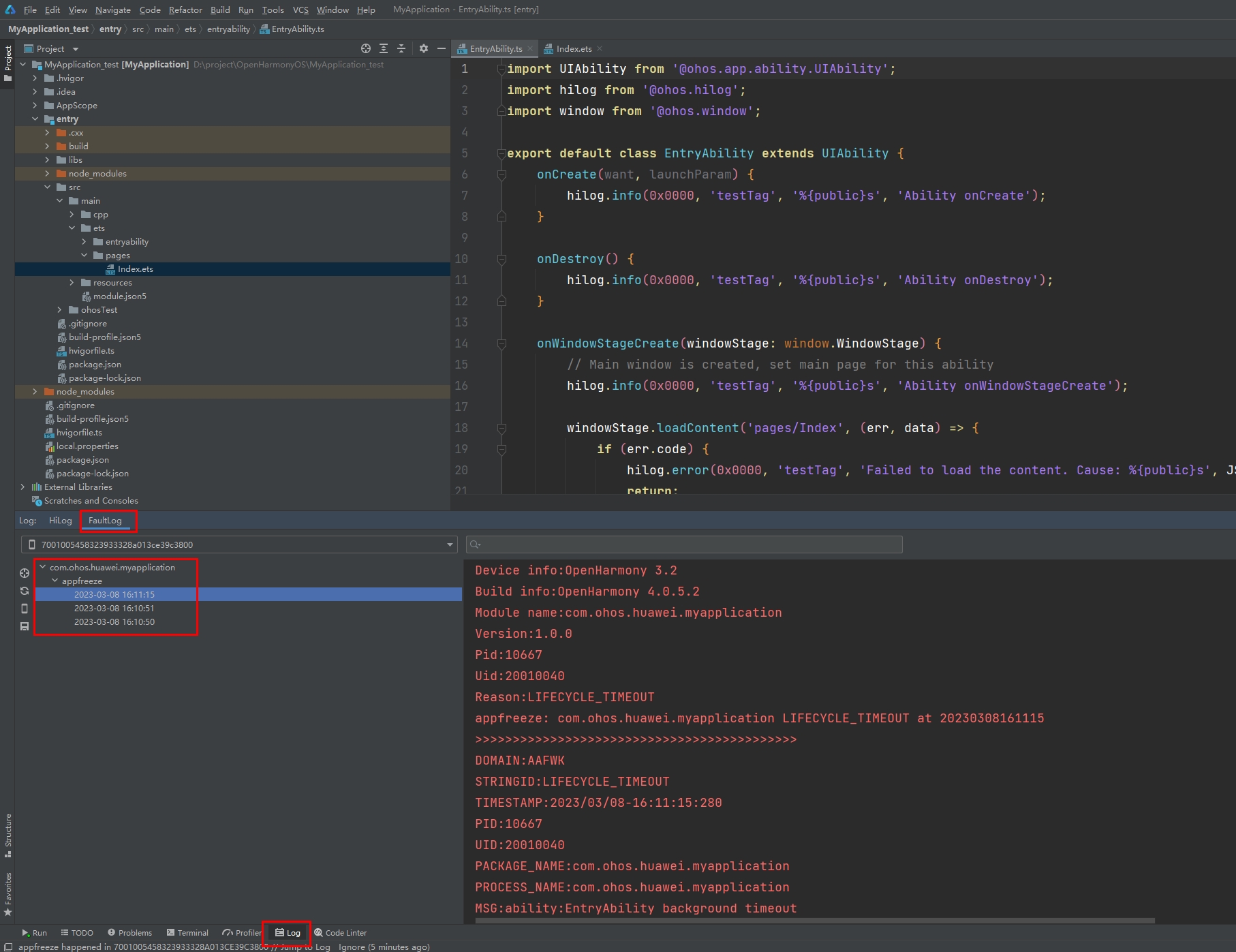
581.7 KB
{kind=link}

70.2 KB
{kind=link}
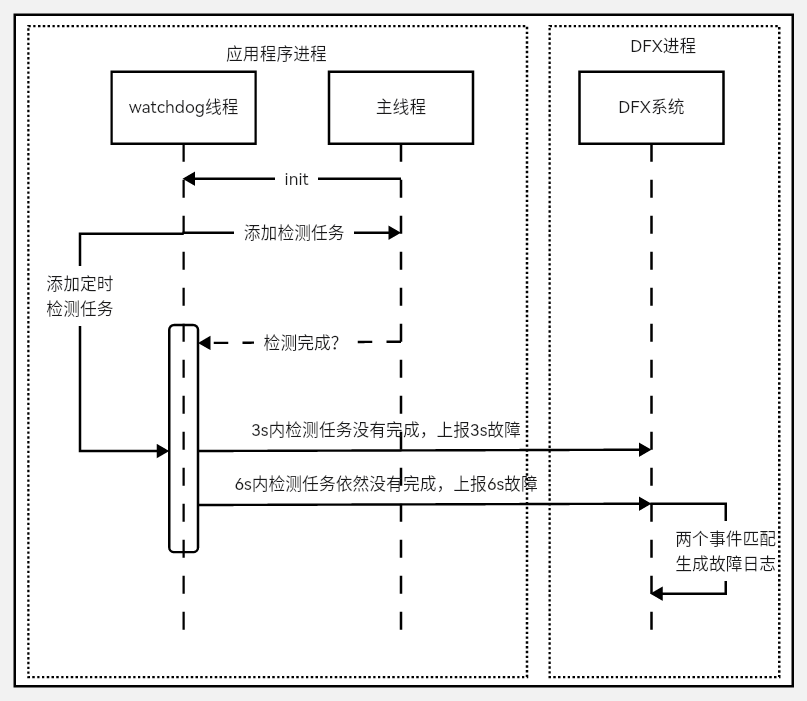
64.1 KB
{kind=link}
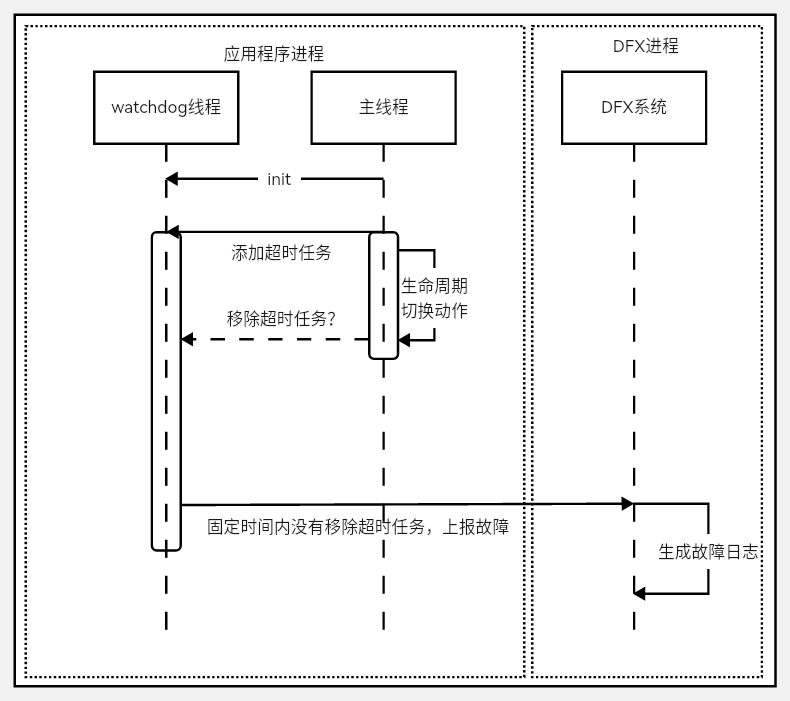
52.2 KB
{kind=link}
153.9 KB
{kind=link}
541.9 KB
{kind=link}
534.4 KB
{kind=link}
225.1 KB
{kind=link}

503.6 KB
{kind=link}
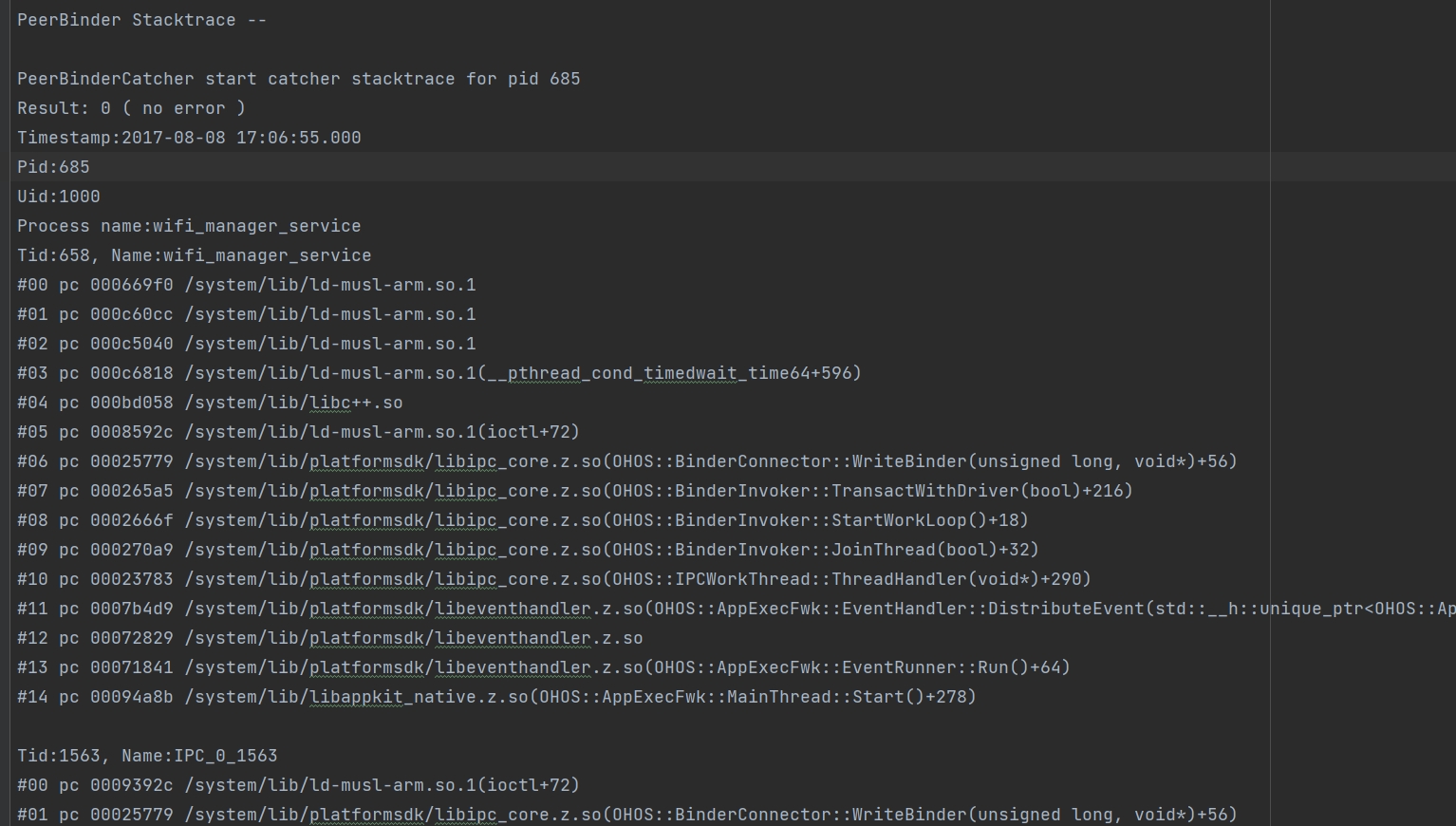
459.9 KB
{kind=link}
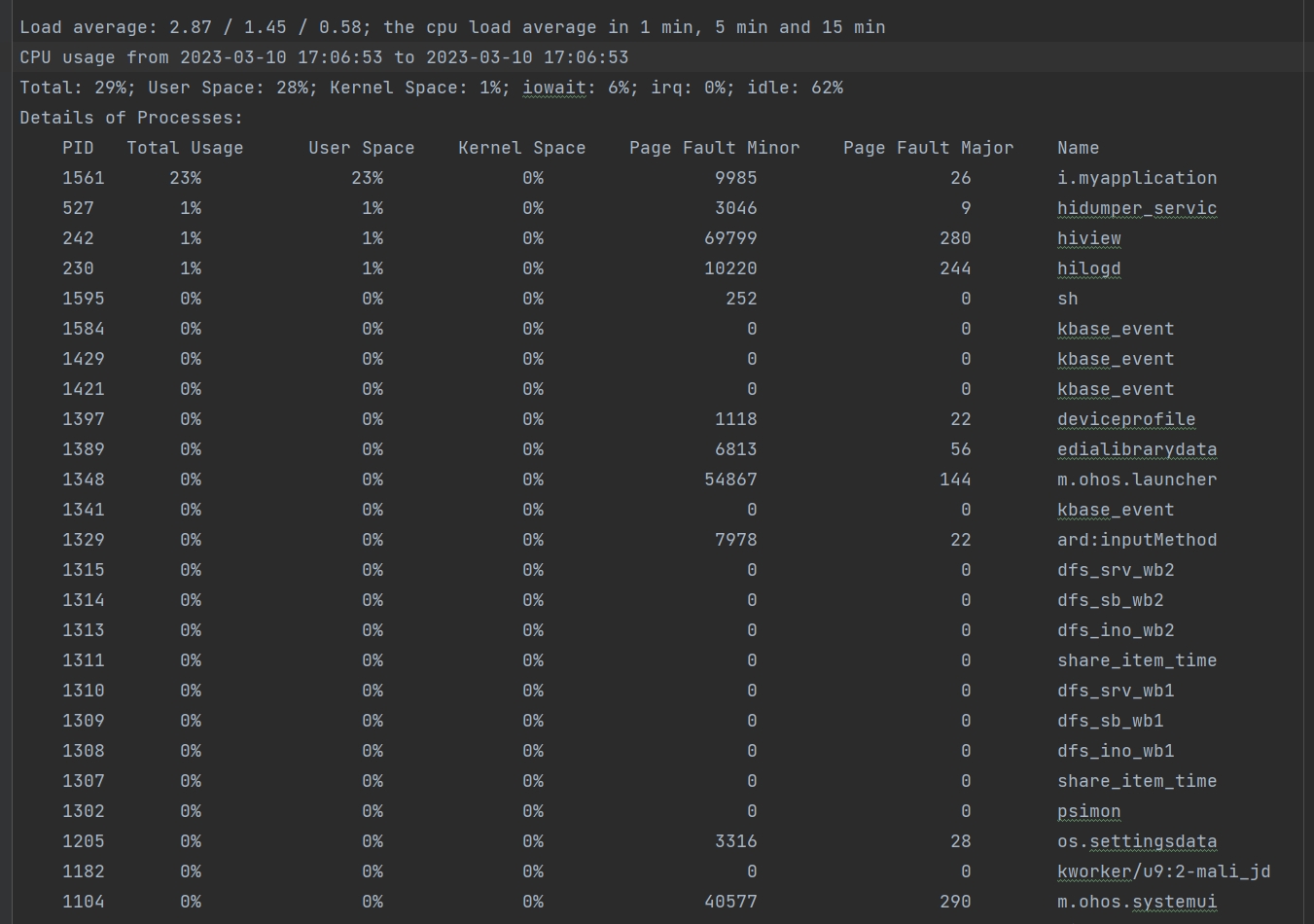
305.9 KB
{kind=link}
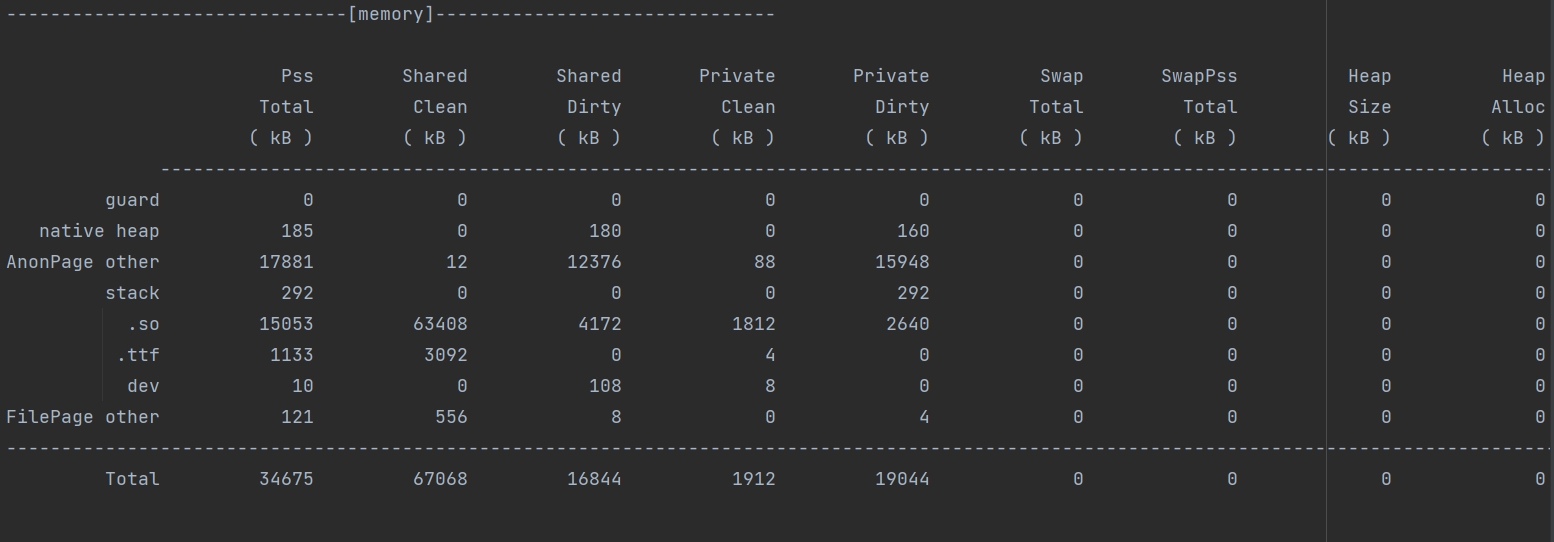
176.6 KB
{kind=link}
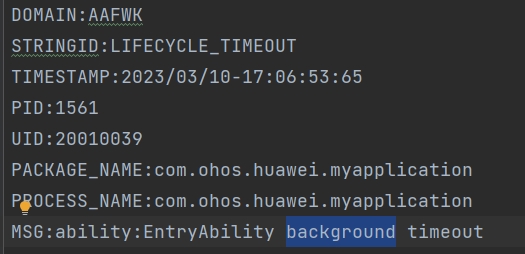
61.9 KB
{kind=link}
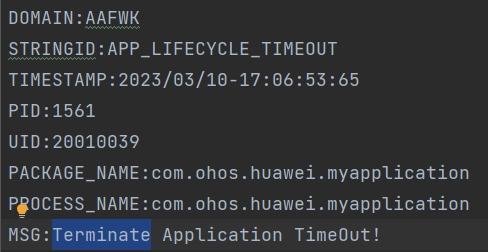
64.7 KB
Merge pull request !15868 from mgceshuang/master
35.9 KB
581.7 KB
70.2 KB
64.1 KB
52.2 KB
153.9 KB
541.9 KB
534.4 KB
225.1 KB
503.6 KB
459.9 KB
305.9 KB
176.6 KB
61.9 KB
64.7 KB