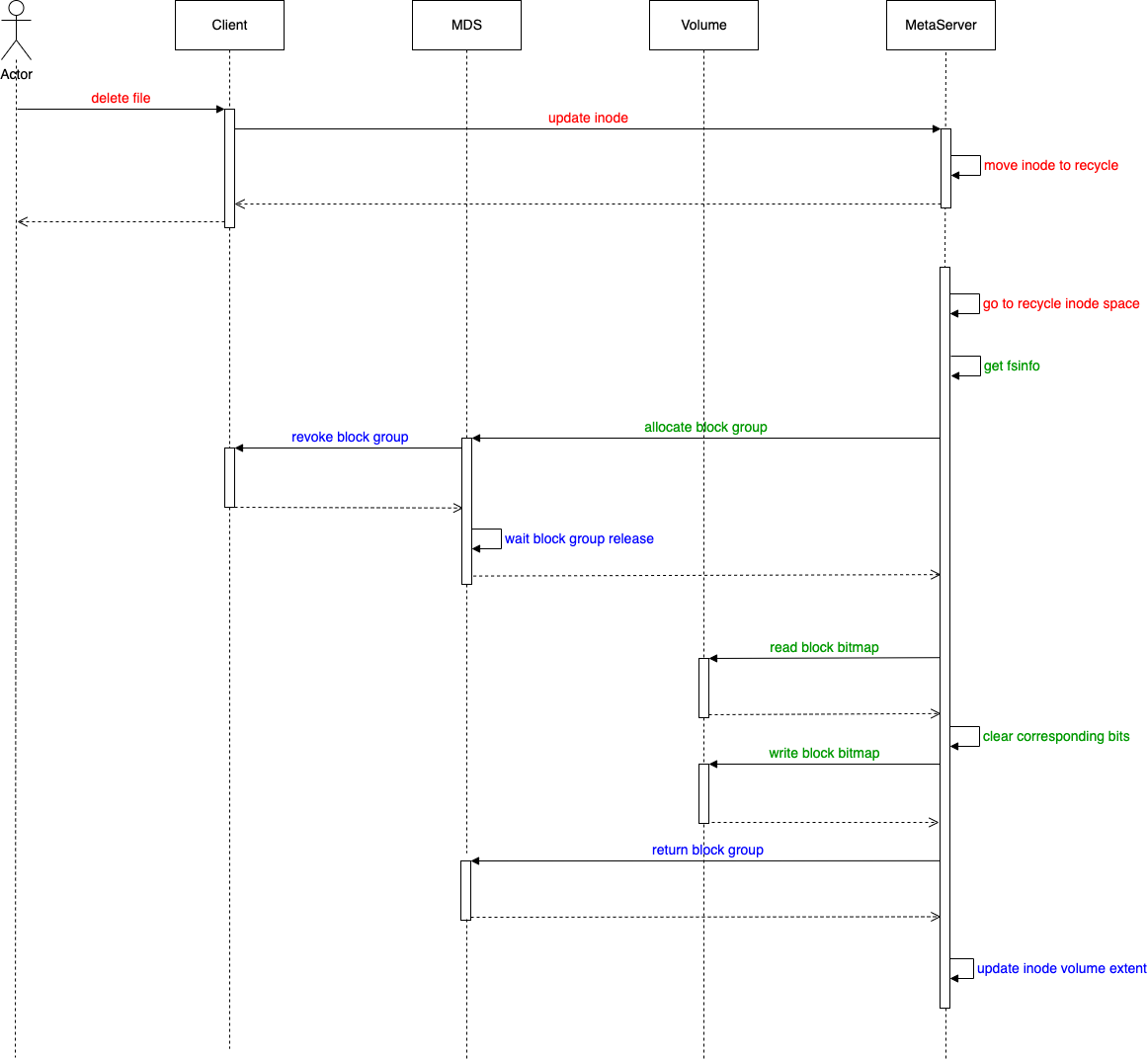
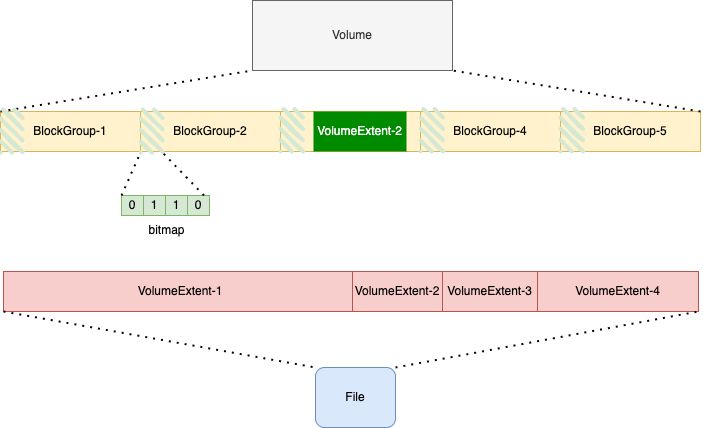
doc: add space manage of curvefs with volume backend
Signed-off-by: Nilixiaocui <ilixiaocui@163.com>
Showing
docs/cn/Curve文件系统Volume后端空间管理.md
0 → 100644
{kind=link}
87.4 KB
docs/images/volume-space.png
0 → 100644
{kind=link}
44.7 KB