
Update depthai_blazepose/BlazeposeDepthai.py,...
Update depthai_blazepose/BlazeposeDepthai.py, depthai_blazepose/BlazeposeDepthaiEdge.py, depthai_blazepose/demo.py, depthai_blazepose/BlazeposeRenderer.py, depthai_blazepose/docker_tflite2tensorflow.sh, depthai_blazepose/FPS.py, depthai_blazepose/LICENSE.txt, depthai_blazepose/mediapipe_utils.py, depthai_blazepose/o3d_utils.py, depthai_blazepose/README.md, depthai_blazepose/requirements.txt, depthai_blazepose/template_manager_script.py, depthai_blazepose/.idea/.gitignore, depthai_blazepose/.idea/.name, depthai_blazepose/.idea/depthai_blazepose-main.iml, depthai_blazepose/.idea/misc.xml, depthai_blazepose/.idea/modules.xml, depthai_blazepose/.idea/workspace.xml, depthai_blazepose/.idea/inspectionProfiles/profiles_settings.xml, depthai_blazepose/.idea/inspectionProfiles/Project_Default.xml, depthai_blazepose/__pycache__/BlazeposeDepthaiEdge.cpython-38.pyc, depthai_blazepose/__pycache__/FPS.cpython-38.pyc, depthai_blazepose/__pycache__/BlazeposeRenderer.cpython-38.pyc, depthai_blazepose/__pycache__/mediapipe_utils.cpython-38.pyc, depthai_blazepose/__pycache__/o3d_utils.cpython-38.pyc, depthai_blazepose/custom_models/DetectionBestCandidate_sh1.blob, depthai_blazepose/custom_models/DivideBy255_sh1.blob, depthai_blazepose/custom_models/convert_model.sh, depthai_blazepose/custom_models/DetectionBestCandidate.py, depthai_blazepose/custom_models/DivideBy255.py, depthai_blazepose/custom_models/README.md, depthai_blazepose/examples/semaphore_alphabet/medias/video.mp4, depthai_blazepose/examples/semaphore_alphabet/medias/semaphore.gif, depthai_blazepose/examples/semaphore_alphabet/medias/semaphore.mp4, depthai_blazepose/examples/semaphore_alphabet/demo.py, depthai_blazepose/examples/semaphore_alphabet/README.md, depthai_blazepose/img/pipeline_edge_mode.png, depthai_blazepose/img/full_body_landmarks.png, depthai_blazepose/img/pipeline_host_mode.png, depthai_blazepose/img/3d_visualizations.gif, depthai_blazepose/img/taichi.gif, depthai_blazepose/img/3d_world_visualization.gif, depthai_blazepose/models/convert_models.sh, depthai_blazepose/models/gen_blob_shave.sh, depthai_blazepose/models/pose_landmark_lite_sh4.blob, depthai_blazepose/models/pose_detection_sh4.blob, depthai_blazepose/models/pose_landmark_full_sh4.blob, depthai_blazepose/models/pose_landmark_heavy_sh4.blob files Deleted depthai_blazepose/.gitkeep
Showing
depthai_blazepose/.gitkeep
已删除
100644 → 0
depthai_blazepose/.idea/.name
0 → 100644
depthai_blazepose/.idea/misc.xml
0 → 100644
此差异已折叠。
此差异已折叠。
depthai_blazepose/FPS.py
0 → 100644
depthai_blazepose/LICENSE.txt
0 → 100644
depthai_blazepose/README.md
0 → 100644
文件已添加
文件已添加
文件已添加
depthai_blazepose/demo.py
0 → 100644
{kind=link}
因为 它太大了无法显示 image diff 。你可以改为 查看blob。
{kind=link}

5.1 MB
{kind=link}
因为 它太大了无法显示 image diff 。你可以改为 查看blob。
{kind=link}
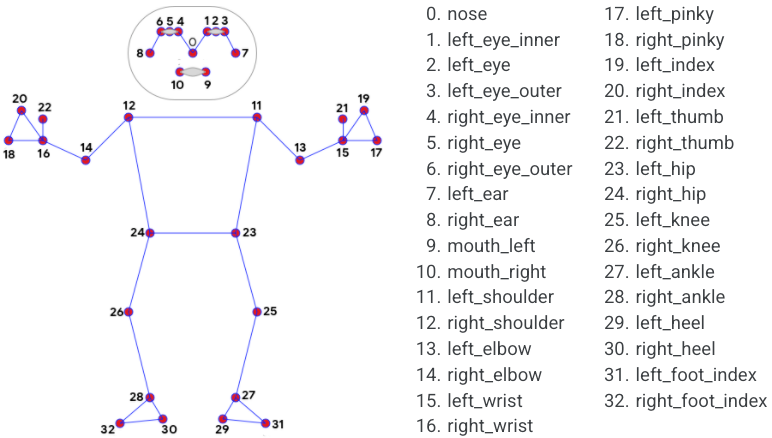
120.1 KB
{kind=link}
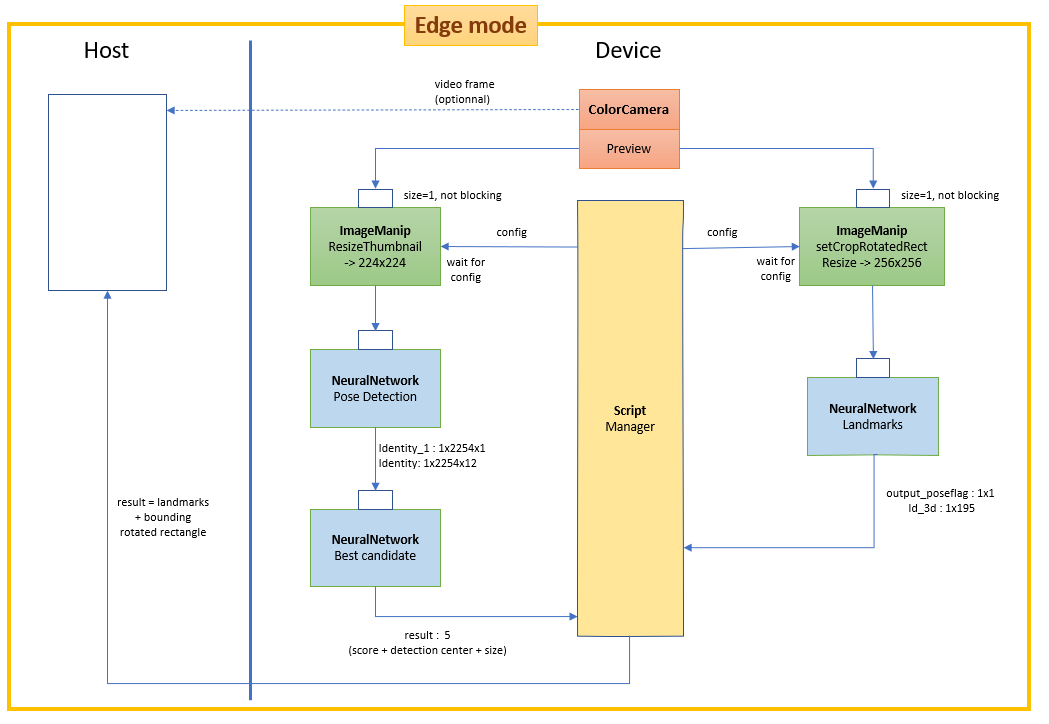
45.2 KB
{kind=link}
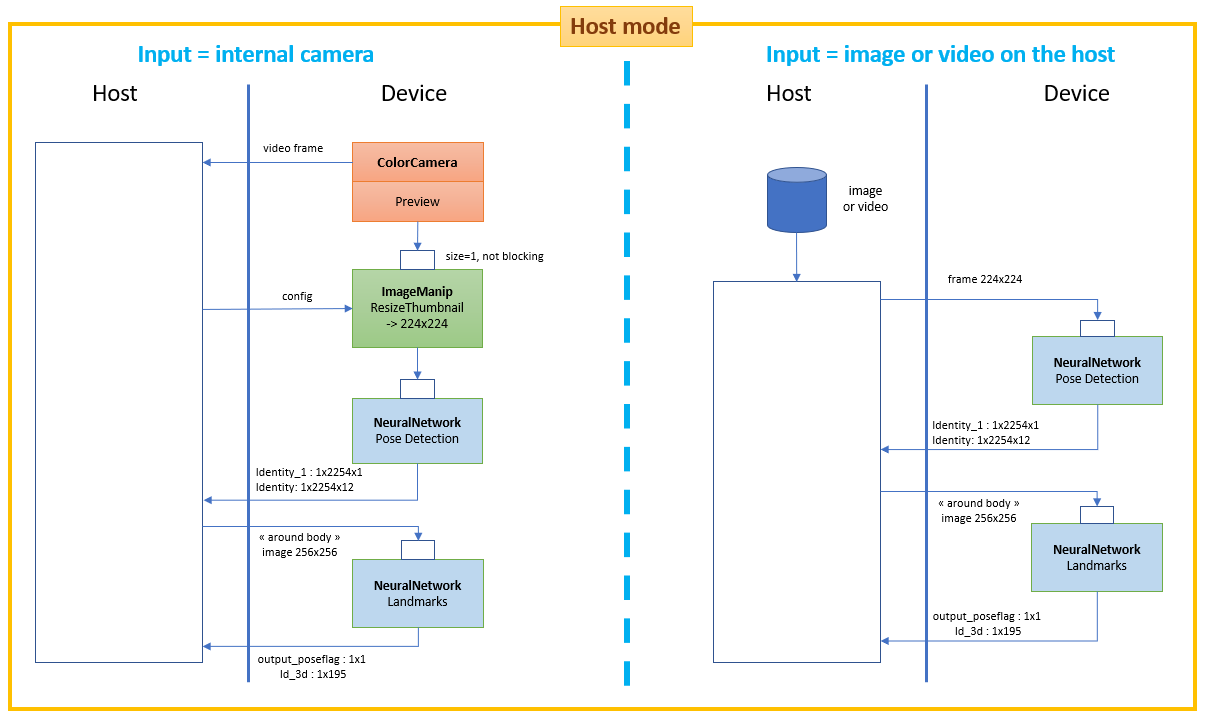
45.1 KB
depthai_blazepose/img/taichi.gif
0 → 100644
{kind=link}

4.0 MB
此差异已折叠。
文件已添加
文件已添加
文件已添加
文件已添加
depthai_blazepose/o3d_utils.py
0 → 100644