@@ -87,9 +87,7 @@ The processing of text into features can be nearly inexistent as it can be very
\color{red}Talk about evaluation metrics (mainly MOS)?\color{black}
\subsection{State of the art in multispeaker TTS}
Previous state of the art in SPSS includes hidden Markov models (HMM) based speech synthesis \cite{Tokuda-2013}. The speech generation pipeline is laid out in figure \ref{hmm_spss_framework}. In this framework, the acoustic model is a set of HMMs. The input features are rich linguistic contexts. Ideally, one would train an HMM for each possible context; but as the number of contexts increases exponentially with the number of factors considered, it is not practical to do so. Indeed, not every context will be found in a typical dataset and the training set would then be partitioned over the different contexts, which is very data inefficient. Instead, contexts are clustered using decision trees and an HMM is learned for each cluster \cite{HMMTTS}. Note that this does not solve entirely the training set fragmentation problem. The HMMs are trained to produce a distribution over mel-frequency cepstral coefficients (MFCC) with energy (called static features), their delta and delta-delta coefficients (called dynamic features) as well as a binary flag that indicates which parts of the audio should contain voice. This is shown in figure \ref{mlpg_features}. A new sequence of static features is retrieved from these static and dynamic features using the maximum likelihood parameter generation (MLPG) algorithm \cite{Tokuda-2000}. These static features are then fed through the MLSA \cite{MLSA} vocoder.
It is possible to modify the voice generated by conditioning on a speaker or tuning the generated speech parameters with adaptation or interpolation techniques (e.g. \cite{HMMSpeakerInterpolation}\color{red} elaborate a bit on these techniques?\color{black}), making HMM-based speech synthesis a multispeaker TTS system. \color{red} Compare with concatenative see \cite{SPSSDNN} and ieeexplore.ieee.org/document/541110.\color{black}
Previous state of the art in SPSS includes hidden Markov models (HMM) based speech synthesis \cite{Tokuda-2013}. The speech generation pipeline is laid out in figure \ref{hmm_spss_framework}. In this framework, the acoustic model is a set of HMMs. The input features are rich linguistic contexts. Ideally, one would train an HMM for each possible context; but as the number of contexts increases exponentially with the number of factors considered, it is not practical to do so. Indeed, not every context will be found in a typical dataset and the training set would then be partitioned over the different contexts, which is very data inefficient. Instead, contexts are clustered using decision trees and an HMM is learned for each cluster \cite{HMMTTS}. Note that this does not solve entirely the training set fragmentation problem. The HMMs are trained to produce a distribution over mel-frequency cepstral coefficients (MFCC) with energy (called static features), their delta and delta-delta coefficients (called dynamic features) as well as a binary flag that indicates which parts of the audio should contain voice. This is shown in figure \ref{mlpg_features}. A new sequence of static features is retrieved from these static and dynamic features using the maximum likelihood parameter generation (MLPG) algorithm \cite{Tokuda-2000}. These static features are then fed through the MLSA \cite{MLSA} vocoder. It is possible to modify the voice generated by conditioning on a speaker or tuning the generated speech parameters with adaptation or interpolation techniques (e.g. \cite{HMMSpeakerInterpolation}\color{red} elaborate a bit on these techniques?\color{black}), making HMM-based speech synthesis a multispeaker TTS system. \color{red} Compare with concatenative see \cite{SPSSDNN} and ieeexplore.ieee.org/document/541110.\color{black}
\begin{figure}[h]
\centering
...
...
@@ -108,10 +106,34 @@ It is possible to modify the voice generated by conditioning on a speaker or tun
\end{minipage}
\end{figure}
Improvements to this framework were later brought by feed-forward deep neural networks (DNN), as a result of progress in both hardware and software. \cite{SPSSDNN} proposes to replace entirely the decision tree-clustered HMMs in favor of a DNN. They argue for better data efficiency as the training set is no longer fragmented in different clusters of contexts\color{red}, and for a more powerful model?\color{black}. They demonstrate improvements over the speech quality with a number of parameters similar to that of the HMM-based approach. Their best model is a DNN with 4 layers of 256 units using a sigmoid activation function. Subjects assessing the quality of the generated audio samples report that the DNN-based models produces speech that sounds less muffled than that of the HMM-based models. Later researches corroborate these findings \cite{OnTheTrainingAspects}. \cite{Hashimoto-2015} additionally studies the effect of replacing MLPG with another DNN. The combinations of HMM/DNN and MLPG/DNN give rise to four possible frameworks, the novel ones being HMM+DNN and DNN+DNN\footnote{Note that since the two networks are consecutive in the framework, they can be considered a single network.}, while HMM+MLPG and DNN+MLPG are the frameworks described respectively in \cite{Tokuda-2013} and \cite{SPSSDNN}. Each DNN they use is 3 layers deep with 1024 units using a sigmoid activation function. MOS results confirm that DNN+MLPG is significantly better than HMM+MLPG. The DNN+DNN approach performs as well as HMM+MLPG while HMM+DNN is worse. In another experiment, they introduce a DNN before and after MLPG. While both approaches yield a MOS similar to DNN+MLPG, neither are statistically significantly better. \color{red} make this part nicer to read \color{black}
Improvements to this framework were later brought by feed-forward deep neural networks (DNN), as a result of progress in both hardware and software. \cite{SPSSDNN} proposes to replace entirely the decision tree-clustered HMMs in favor of a DNN. They argue for better data efficiency as the training set is no longer fragmented in different clusters of contexts\color{red}, and for a more powerful model?\color{black}. They demonstrate improvements over the speech quality with a number of parameters similar to that of the HMM-based approach. Their best model is a DNN with 4 layers of 256 units using a sigmoid activation function. Subjects assessing the quality of the generated audio samples report that the DNN-based models produces speech that sounds less muffled than that of the HMM-based models. Later researches corroborate these findings \cite{OnTheTrainingAspects}. \cite{Hashimoto-2015} additionally studies the effect of replacing MLPG with another DNN. The combinations of HMM/DNN and MLPG/DNN give rise to four possible frameworks, the novel ones being HMM+DNN and DNN+DNN\footnote{Note that since the two networks are consecutive in the framework, they can be considered a single network.}, while HMM+MLPG and DNN+MLPG are the frameworks described respectively in \cite{Tokuda-2013} and \cite{SPSSDNN}. Each DNN they use is 3 layers deep with 1024 units using a sigmoid activation function. MOS results confirm that DNN+MLPG is significantly better than HMM+MLPG. The DNN+DNN approach performs as well as HMM+MLPG while HMM+DNN is worse. In another experiment, they introduce a DNN before and after MLPG. While both approaches yield a MOS similar to DNN+MLPG, neither are statistically significantly better. \color{red} make this part nicer to read. Quid of the MOS?\color{black}
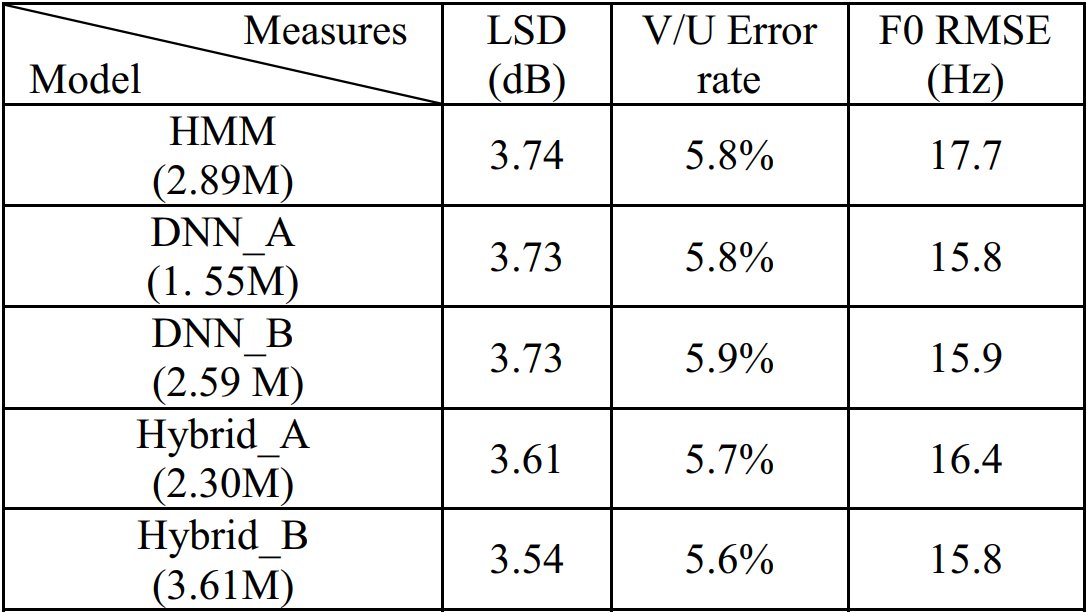
\cite{BDLSTMTTS} supports that RNNs make natural acoustic models as they are able to learn a compact representation of complex and long-span functions, better so than shallow architectures such as the decision trees used in HMM-based TTS. Furthermore, the internal state of RNNs makes the mapping from an input frame to output acoustic features no longer deterministic, allowing for more variety in the synthesized audio. As RNNs are fit to generate temporally consistent series, the static features can directly be determined by the acoustic model, alleviating the need for dynamic features and MLPG. The authors present two RNNs: Hybrid\_A with three feed-forward layers followed by one bidirectional (BDLSTM) layer and Hybrid\_B with two feed-forward layers followed by two BDLSTM layers. They argue that deeper structures of BDLSTM would worsen the performance due to imprecise gradient computation. They compare these networks against the HMM and DNN based approaches described previously, using objective and subjective measures. The objective measures are compared with the true ground: log spectral distance (LSD), V/UV error rate and F0 distortion in root mean squared error (RMSE). The subjective measure is a preference test where participants choose between two audio samples of different models and have the option to select neither. Results are shown in figures \ref{dblstm_objective} and \ref{dblstm_subjective}. DNN\_A is 6 layers deep with 512 units per layer while DNN\_B is 3 layers deep with 1024 units per layer. These two networks perform very similarly. Hybrid\_B systematically performs better than the other approaches.
\captionof{figure}{Performance of the different frameworks evaluated on objective measures. In parentheses are the number of parameters of each acoustic model.}
\captionof{figure}{Two by two comparisons of some of the frameworks in terms of preferences.}
\label{dblstm_subjective}
\end{minipage}
\end{figure}
%3: Main advantage: long span and compact representation of complex functions. DTs are shallow. Not only memory but also internal hidden states which means non determinism wrt input states.
%3: Because RNN good for sequences -> direct prediction of same static features without dynamic
- Could it be that in HMM-base synthesis, static features and their deltas (dynamic) are the same things as predicted mean and variance?
- How do i aggregate the different metrics: MOS, Preference score, LSD/VU error rate/F0 RMSE?
Self:
- Am I going to need a different embedding for the voice of a same speaker in two different languages? I may need to formulate a "unique encoding hypothesis", i.e. that two people with the same voice in language A would also have the same voice in language B. This is likely not a true hypothesis but still a reasonable simplification for the voice transfer problem.
- [1409.0473] "Most of the proposed neural machine translation models belong to a family of encoder–decoders (...), with an encoder and a decoder for each language, (...)". I could do something similar: a voice encoder and a synthesizer per language, and somehow manage to keep a shared embedding space for all languages. This reminds me of UNIT, I wonder if it's applicable here. Very likely, the best way to do this lies in recent NLP methods.
\ No newline at end of file
- [1409.0473] "Most of the proposed neural machine translation models belong to a family of encoder–decoders (...), with an encoder and a decoder for each language, (...)". I could do something similar: a voice encoder and a synthesizer per language, and somehow manage to keep a shared embedding space for all languages. This reminds me of UNIT, I wonder if it's applicable here. Very likely, the best way to do this lies in recent NLP methods.
IIRC "THE EFFECT OF NEURAL NETWORKS IN STATISTICAL PARAMETRIC SPEECH SYNTHESIS" talked somewhere about recurrence and neighbouring features. I can't find where again, but it'd be great if I did.
I think Hashimoto 2015 talked about cross language.
\ No newline at end of file
I think Hashimoto 2015 talked about cross-language.
Fundamentals of speaker recognition has a good deal of stuff for the definitions in the lexicon
{kind=link}
{kind=link}
