@@ -120,7 +120,7 @@ The role of the feature extractor is to provide data that is more indicative of
A common feature extraction technique is to build frames that will integrate surrounding context in a hierarchical fashion. For example, a frame at the syllable level could include the word that comprises it, its position in the word, the neighbouring syllables, the phonemes that make up the syllable, ... The lexical stress and accent of individual syllables can be predicted by a statistical model such as a decision tree. To encode prosody, a set of rules such as ToBI \citep{TOBI} can be used. Ultimately, there remains a work of feature engineering to present a frame as a numerical object to the model, e.g. categorical features are typically encoded using a one-hot representation.
% Spectrogram vs waveform
One could wonder why the acoustic model does not directly predict an audio waveform. Audio happens to be difficult to model: it is a particularly dense domain and audio signals are typically highly nonlinear. A representation that brings out features in a more tractable manner is the time-frequency domain. Spectrograms are much less dense than their waveform counterpart and also have the benefit of being two-dimensional, thus allowing models to better leverage spatial connectivity. Unfortunately, a spectrogram is a lossy representation of the waveform that discards the phase. There is no unique inverse transformation function, and deriving one that produces natural-sounding results is not trivial. When referring to speech, this generative function is called a vocoder. The choice of the vocoder is an important factor in determining the quality of the generated audio.
One could wonder why the acoustic model does not directly predict an audio waveform. Audio happens to be difficult to model: it is a particularly dense domain and audio signals are typically highly nonlinear. A representation that brings out features in a more tractable manner is the time-frequency domain. Spectrograms are smoother and much less dense than their waveform counterpart. They also have the benefit of being two-dimensional, thus allowing models to better leverage spatial connectivity. Unfortunately, a spectrogram is a lossy representation of the waveform that discards the phase. There is no unique inverse transformation function, and deriving one that produces natural-sounding results is not trivial. When referring to speech, this generative function is called a vocoder. The choice of the vocoder is an important factor in determining the quality of the generated audio.
\color{red}Talk about evaluation metrics (MOS and A/B testing)?\color{black}
...
...
@@ -436,7 +436,7 @@ In SV2TTS, the authors consider two datasets for training both the synthesizer a
\label{libri_vctk_cross}
\end{table}
Following the preprocessing methods of the authors, we use an Automatic Speech Recognition (ASR) model to force-align the LibriSpeech transcripts to text. We found the Montreal Forced Aligner\footnote{\url{https://montreal-forced-aligner.readthedocs.io/en/latest/}} to perform this task well. We've also made a cleaner version of these alignments public\footnote{\url{https://github.com/CorentinJ/librispeech-alignments}} to save some time for other users in need of them. With the audio aligned to the text, we can split utterances on silences. This helps the synthesizer to converge, both because of the removal of silences in the target spectrogram, but also due to the reduction of the median duration of the utterances in the dataset, as shorter sequences offer less room for timing errors. Additionally, isolating the silences allows to create a profile of the noise for all utterances of the same speaker. We found a Fourier-analysis based noise removal algorithm to perform well on this task, but unfortunately could not reimplement this algorithm in our preprocessing pipeline.
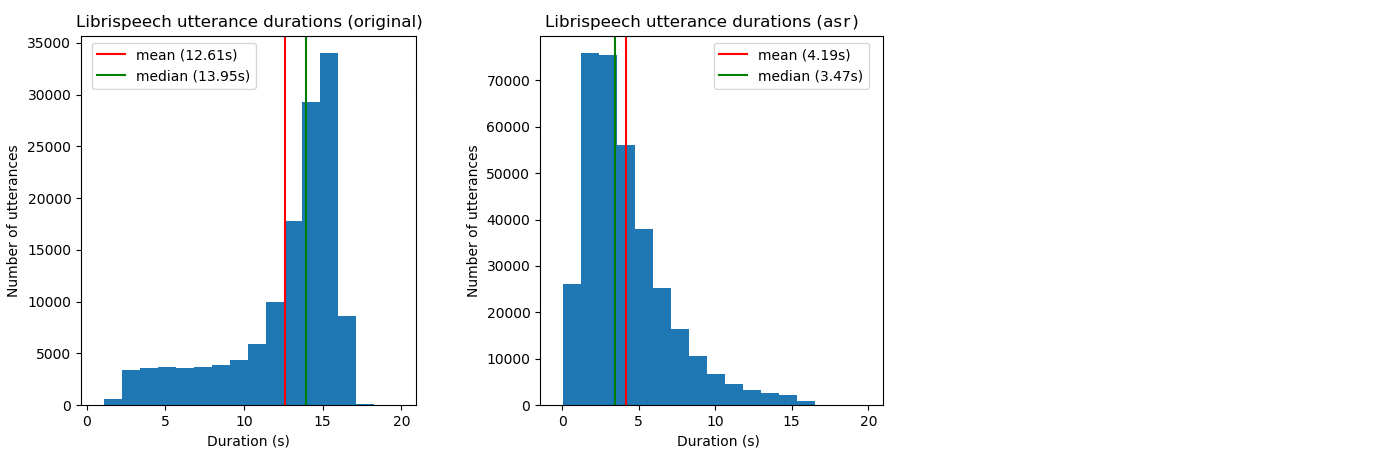
Following the preprocessing recommendations of the authors, we use an Automatic Speech Recognition (ASR) model to force-align the LibriSpeech transcripts to text. We found the Montreal Forced Aligner\footnote{\url{https://montreal-forced-aligner.readthedocs.io/en/latest/}} to perform well on this task. We've also made a cleaner version of these alignments public\footnote{\url{https://github.com/CorentinJ/librispeech-alignments}} to save some time for other users in need of them. With the audio aligned to the text, we can split utterances on silences. This helps the synthesizer to converge, both because of the removal of silences in the target spectrogram, but also due to the reduction of the median duration of the utterances in the dataset as shorter sequences offer less room for timing errors. We ensure that utterances are not shorter than 1.6 seconds, the duration of partial utterances used for training the encoder, and not longer than 11.25 seconds so as to save GPU memory for training. The distribution of the length of the utterances in the dataset is plotted in figure \ref{librispeech_durations}. Isolating the silences with force-aligning the text to the utterances additionally allows to create a profile of the noise for all utterances of the same speaker. We found a Fourier-analysis based noise removal algorithm to perform well on this task, but unfortunately could not reimplement this algorithm in our preprocessing pipeline.
\begin{figure}[h]
\centering
...
...
@@ -445,12 +445,37 @@ Following the preprocessing methods of the authors, we use an Automatic Speech R
\label{librispeech_durations}
\end{figure}
- no metrics:
- conditioning:
%- authors say themselves large variation within same speaker, and synthesizer trained to produce *same* spectrogram -> might want to be as accurate as possible with the embedding
%- the utterance embedding is used at inference
%- confusion as to whether speaker embeddings are normalized or not
%- minimum duration of the utterances in the dataset
In SV2TTS, the embeddings used to condition the synthesizer at training time are speaker embeddings. We argue that utterance embeddings of the same target utterance make for a more natural choice. At inference time, utterance embeddings are used. While the space of utterance and speaker embeddings is the same, speaker embeddings are not L2-normalized. This difference in domain should be small and have little impact, as the authors agreed when we asked them about it. However, they do not mention how many utterance embeddings are used to derive a speaker embedding. One would expect that all utterances available should be used; but with a larger number of utterance embeddings, the average vector (the speaker embedding) will further stray from its normalized version. Furthermore, the authors mention themselves that there are often large variations of tone and pitch within the utterances of a same speaker in the dataset, as they mimic different characters (see SV2TTS appendix B). Utterances have lower intra-variation as their scope is limited to a sentence at most. Therefore, the embedding of an utterance is expected to be a more accurate representation of the voice in the utterance than the embedding of the speaker. This holds if the utterance is long enough than to produce a meaningful embedding. While the "optimal" duration of reference speech was found to be 5 seconds, the embedding is shown to be already meaningful with only 2 seconds of reference speech (see table \ref{reference_speech_duration}). We believe that with utterances no shorter than the duration of partial utterances, the utterance embedding should be sufficient for a meaningful capture of the voice, hence we used utterance embeddings for training the synthesizer.
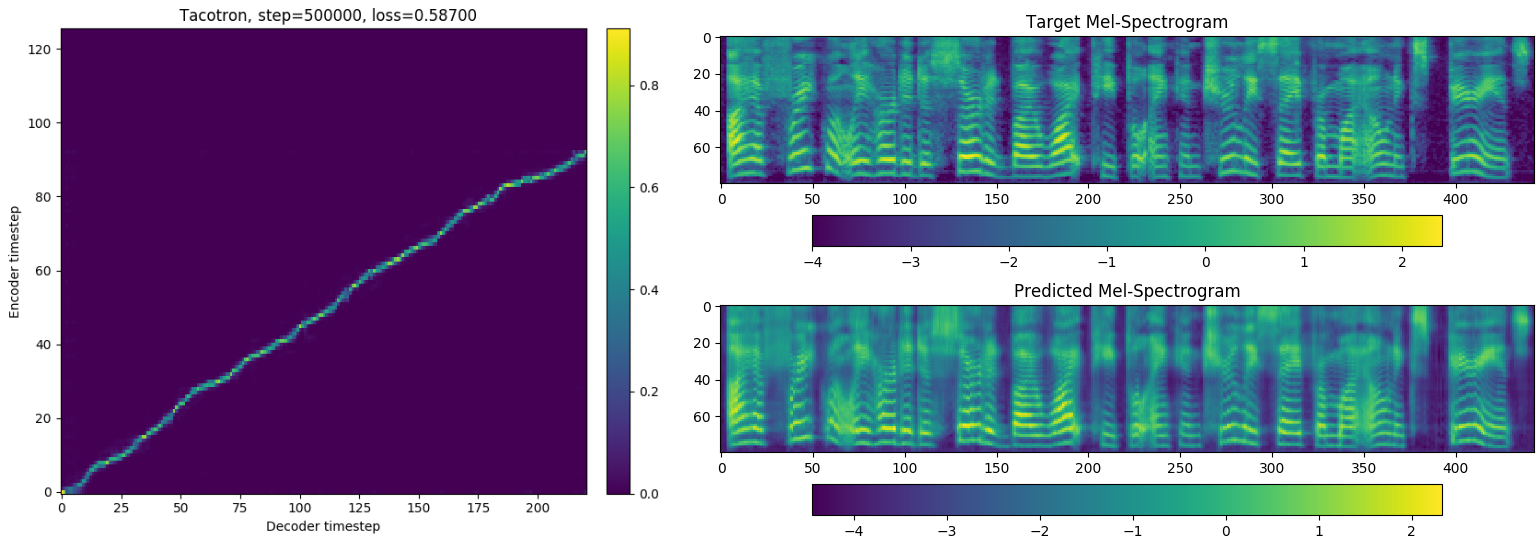
Unfortunately, as is also the case for the vocoder, it is difficult to provide any quantitative assessment of the performance of the model. We can observe that the model is producing correct outputs through informal listening tests, but evaluating it would require us to setup subjective score polls to derive the MOS. While most authors we referred to could do so, this is beyond our possibilities. In the case of the synthesizer however, one can also verify that the alignments generated by the attention module make sense.
\caption{(left) Example of alignment between the encoder steps and the decoder steps. (right) Comparison between the predicted spectrogram (with GTA) and the ground truth spectrogram.}
{kind=link}
{kind=link}

{kind=link}