Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
moyewuji
Python-100-Days
提交
a97f4ac4
P
Python-100-Days
项目概览
moyewuji
/
Python-100-Days
与 Fork 源项目一致
从无法访问的项目Fork
通知
1
Star
1
Fork
0
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
0
列表
看板
标记
里程碑
合并请求
0
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
P
Python-100-Days
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
0
Issue
0
列表
看板
标记
里程碑
合并请求
0
合并请求
0
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
体验新版 GitCode,发现更多精彩内容 >>
提交
a97f4ac4
编写于
5月 28, 2018
作者:
骆昊的技术专栏
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
更新了爬虫第1天的文档
上级
00b7d74c
变更
3
隐藏空白更改
内联
并排
Showing
3 changed file
with
23 addition
and
0 deletion
+23
-0
Day66-75/01.网络爬虫和相关工具.md
Day66-75/01.网络爬虫和相关工具.md
+23
-0
Day66-75/res/http-request.png
Day66-75/res/http-request.png
+0
-0
Day66-75/res/http-response.png
Day66-75/res/http-response.png
+0
-0
未找到文件。
Day66-75/01.网络爬虫和相关工具.md
浏览文件 @
a97f4ac4
...
...
@@ -89,7 +89,17 @@ Disallow: /
#### HTTP协议
在开始讲解爬虫之前,我们稍微对HTTP(超文本传输协议)做一些回顾,因为我们在网页上看到的内容通常是浏览器执行HTML语言得到的结果,而HTTP就是传输HTML数据的协议。HTTP是构建于TCP(传输控制协议)之上应用级协议,它利用了TCP提供的可靠的传输服务实现了Web应用中的数据交换。按照维基百科上的介绍,设计HTTP最初的目的是为了提供一种发布和接收
[
HTML
](
https://zh.wikipedia.org/wiki/HTML
)
页面的方法,也就是说这个协议是浏览器和Web服务器之间传输的数据的载体。关于这个协议的详细信息以及目前的发展状况,大家可以阅读阮一峰老师的
[
《HTTP 协议入门》
](
http://www.ruanyifeng.com/blog/2016/08/http.html
)
、
[
《互联网协议入门》
](
http://www.ruanyifeng.com/blog/2012/05/internet_protocol_suite_part_i.html
)
系列以及
[
《图解HTTPS协议》
](
http://www.ruanyifeng.com/blog/2014/09/illustration-ssl.html
)
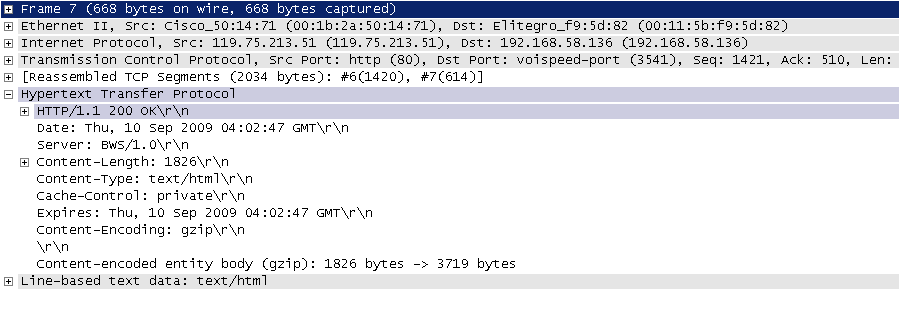
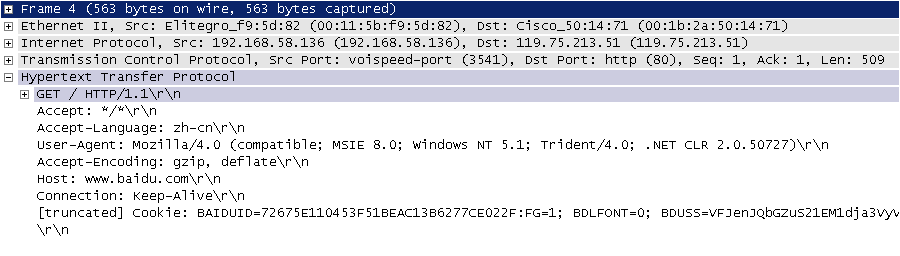
进行了解,下图是我在2009年9月10日凌晨4点在四川省网络通信技术重点实验室用开源协议分析工具Ethereal(抓包工具WireShark的前身)截取的访问百度首页时的HTTP请求和响应的报文(协议数据),由于Ethereal截取的是经过网络适配器的数据,因此可以清晰的看到从物理链路层到应用层的协议数据。
HTTP请求(请求行+请求头+空行+[消息体]):

HTTP响应(响应行+响应头+空行+消息体):

> 说明:但愿这两张如同泛黄的照片般的截图帮助你大概的了解到HTTP是一个怎样的协议。
#### 相关工具
...
...
@@ -148,6 +158,19 @@ Disallow: /
6.
robotparser:解析robots.txt的工具
```
Python
>>> from urllib import robotparser
>>> parser = robotparser.RobotFileParser()
>>> parser.set_url('https://www.taobao.com/robots.txt')
>>> parser.read()
>>> parser.can_fetch('Hellokitty', 'http://www.taobao.com/article')
False
>>> parser.can_fetch('Baiduspider', 'http://www.taobao.com/article')
True
>>> parser.can_fetch('Baiduspider', 'http://www.taobao.com/product')
False
```
### 一个简单的爬虫
构造一个爬虫一般分为数据采集、数据处理和数据存储三个部分的内容。
...
...
Day66-75/res/http-request.png
0 → 100644
浏览文件 @
a97f4ac4
5.9 KB
Day66-75/res/http-response.png
0 → 100644
浏览文件 @
a97f4ac4
6.4 KB
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录

{kind=link}
{kind=link}