initial version
上级
Showing
.gitignore
0 → 100644
LICENSE
0 → 100644
MANIFEST.in
0 → 100644
NOTICE
0 → 100644
README.md
0 → 100644
RELEASE.md
0 → 100644
SECURITY.md
0 → 100644
build/build.sh
0 → 100755
build/scripts/crc32.sh
0 → 100755
build/scripts/ui.sh
0 → 100755
docs/README.md
0 → 100644
docs/arch.png
0 → 100644
{kind=link}
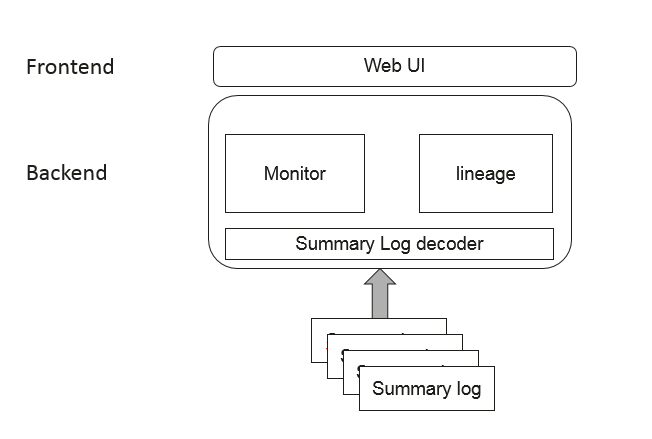
11.7 KB
mindinsight/__init__.py
0 → 100644
mindinsight/__main__.py
0 → 100644
mindinsight/_version.py
0 → 100644
mindinsight/backend/__init__.py
0 → 100644
mindinsight/backend/run.py
0 → 100644
mindinsight/common/__init__.py
0 → 100644
mindinsight/conf/__init__.py
0 → 100644
mindinsight/conf/constants.py
0 → 100644
mindinsight/conf/defaults.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
mindinsight/scripts/__init__.py
0 → 100644
此差异已折叠。
mindinsight/scripts/start.py
0 → 100644
此差异已折叠。
mindinsight/scripts/stop.py
0 → 100644
此差异已折叠。
mindinsight/ui/.browserslistrc
0 → 100644
此差异已折叠。
mindinsight/ui/.eslintrc.js
0 → 100644
此差异已折叠。
mindinsight/ui/.gitignore
0 → 100644
此差异已折叠。
mindinsight/ui/babel.config.js
0 → 100644
此差异已折叠。
mindinsight/ui/package.json
0 → 100644
此差异已折叠。
mindinsight/ui/postcss.config.js
0 → 100644
此差异已折叠。
mindinsight/ui/public/index.html
0 → 100644
此差异已折叠。
此差异已折叠。
mindinsight/ui/src/app.vue
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
mindinsight/ui/src/i18n.js
0 → 100644
此差异已折叠。
此差异已折叠。
mindinsight/ui/src/main.js
0 → 100644
此差异已折叠。
mindinsight/ui/src/router.js
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
mindinsight/ui/src/store.js
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
mindinsight/ui/vue.config.js
0 → 100644
此差异已折叠。
mindinsight/utils/__init__.py
0 → 100644
此差异已折叠。
mindinsight/utils/command.py
0 → 100644
此差异已折叠。
mindinsight/utils/constant.py
0 → 100644
此差异已折叠。
mindinsight/utils/exceptions.py
0 → 100644
此差异已折叠。
mindinsight/utils/hook.py
0 → 100644
此差异已折叠。
mindinsight/utils/log.py
0 → 100644
此差异已折叠。
requirements.txt
0 → 100644
此差异已折叠。
setup.py
0 → 100644
此差异已折叠。
tests/__init__.py
0 → 100644
此差异已折叠。
tests/st/func/__init__.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
tests/st/runtest.sh
0 → 100644
此差异已折叠。
tests/ut/__init__.py
0 → 100644
此差异已折叠。
tests/ut/backend/__init__.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
tests/ut/datavisual/__init__.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
tests/ut/datavisual/conftest.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
tests/ut/datavisual/mock.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
tests/ut/lineagemgr/__init__.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
tests/ut/runtest.sh
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
third_party/securec/src/gets_s.c
0 → 100644
此差异已折叠。
third_party/securec/src/input.inl
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
third_party/securec/src/scanf_s.c
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。