Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
MindSpore
docs
提交
ebff399c
D
docs
项目概览
MindSpore
/
docs
通知
5
Star
3
Fork
2
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
0
列表
看板
标记
里程碑
合并请求
0
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
D
docs
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
0
Issue
0
列表
看板
标记
里程碑
合并请求
0
合并请求
0
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
提交
ebff399c
编写于
6月 29, 2020
作者:
M
mindspore-ci-bot
提交者:
Gitee
6月 29, 2020
浏览文件
操作
浏览文件
下载
差异文件
!307 Add new notebook file in tutorials
Merge pull request !307 from lvmingfu/lmf-docs
上级
f2d23d56
0ef1bc56
变更
5
显示空白变更内容
内联
并排
Showing
5 changed file
with
699 addition
and
0 deletion
+699
-0
tutorials/notebook/mindinsight/images/data_lineage.png
tutorials/notebook/mindinsight/images/data_lineage.png
+0
-0
tutorials/notebook/mindinsight/images/model_lineage_all.png
tutorials/notebook/mindinsight/images/model_lineage_all.png
+0
-0
tutorials/notebook/mindinsight/images/model_lineage_cp.png
tutorials/notebook/mindinsight/images/model_lineage_cp.png
+0
-0
tutorials/notebook/mindinsight/images/summary_list.png
tutorials/notebook/mindinsight/images/summary_list.png
+0
-0
tutorials/notebook/mindinsight/mindinsight_model_lineage_and_data_lineage.ipynb
...dinsight/mindinsight_model_lineage_and_data_lineage.ipynb
+699
-0
未找到文件。
tutorials/notebook/mindinsight/images/data_lineage.png
0 → 100644
浏览文件 @
ebff399c
87.8 KB
tutorials/notebook/mindinsight/images/model_lineage_all.png
0 → 100644
浏览文件 @
ebff399c
164.7 KB
tutorials/notebook/mindinsight/images/model_lineage_cp.png
0 → 100644
浏览文件 @
ebff399c
146.5 KB
tutorials/notebook/mindinsight/images/summary_list.png
0 → 100644
浏览文件 @
ebff399c
32.9 KB
tutorials/notebook/mindinsight/mindinsight_model_lineage_and_data_lineage.ipynb
0 → 100644
浏览文件 @
ebff399c
{
"cells": [
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# <center/>MindInsight的模型溯源和数据溯源体验"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## 概述\n",
"在AI训练的过程中,面对陌生的神经网络训练,经常需要事先优化神经网络训练中的参数,毕竟在训练一个十分复杂的神经网络时,有时候需要花费少则几天多则几周甚至更多的时间,为了更好的管理、调试和优化神经网络的训练过程,我们需要一个工具来对训练过程中的计算图、各种指标随着时间的变化趋势以及训练中使用到的图像信息进行分析和记录工作,而MindSpore就提供了一个对用户十分易用友好的可视化工具MindInsight,赋能给用户进行数据溯源和模型溯源的可视化分析,能明显提升用户对网络搭建过程和数据增强过程的纠错调优能力。而本次体验会从MindInsight的数据记录,可视化效果,如何方便用户在模型调优,数据调优上做一次整体流程的体验。"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"下面按照MindSpore的训练数据模型的正常步骤进行,当使用到MindInsight或者`SummaryCollector`算子进行数据保存操作时,会增加相应的说明,本次体验的整体流程如下:"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"1、数据集的准备,这里使用的是MNIST数据集。\n",
"\n",
"2、构建一个网络,这里使用LeNet网络。(此处将使用第二种记录方式`ImageSummary`)。\n",
"\n",
"3、训练网络和测试网络的搭建及运行。(此处将操作`SummaryCollector`初始化,并记录模型训练和模型测试相关信息)。\n",
"\n",
"4、启动MindInsight服务。\n",
"\n",
"5、模型溯源的使用。调整模型参数多次存储数据,并使用MindInsight的模型溯源功能对不同优化参数下训练产生的模型作对比,了解MindSpore中的各类优化对训练过程的影响及如何调优训练过程。\n",
"\n",
"6、数据溯源的使用。调整数据参数多次存储数据,并使用MindInsight的数据溯源功能对不同数据集下训练产生的模型进行对比分析,了解如何调优。"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"本次体验将使用快速入门案例作为基础用例,将MindInsight的模型溯源和数据溯源的数据记录功能加入到案例中,快速入门案例的源码请参考:https://gitee.com/mindspore/docs/blob/master/tutorials/tutorial_code/lenet.py 。"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## 一、训练的数据集下载"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### 1、数据集准备"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### 方法一:\n",
"从以下网址下载,并将数据包解压缩后放至Jupyter的工作目录下:<br/>训练数据集:{\"http://yann.lecun.com/exdb/mnist/train-images-idx3-ubyte.gz\", \"http://yann.lecun.com/exdb/mnist/train-labels-idx1-ubyte.gz\"}\n",
"<br/>测试数据集:{\"http://yann.lecun.com/exdb/mnist/t10k-images-idx3-ubyte.gz\", \"http://yann.lecun.com/exdb/mnist/t10k-labels-idx1-ubyte.gz\"}<br/>我们用下面代码查询jupyter的工作目录。"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"import os\n",
"os.getcwd()"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"训练数据集放在----`Jupyter工作目录+\\MNIST_Data\\train\\`,此时`train`文件夹内应该包含两个文件,`train-images-idx3-ubyte`和`train-labels-idx1-ubyte` <br/>测试数据集放在----`Jupyter工作目录+\\MNIST_Data\\test\\`,此时`test`文件夹内应该包含两个文件,`t10k-images-idx3-ubyte`和`t10k-labels-idx1-ubyte`"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### 方法二:\n",
"直接执行下面代码,会自动进行训练集的下载与解压,但是整个过程根据网络好坏情况会需要花费几分钟时间。"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Network request module, data download module, decompression module\n",
"import urllib.request \n",
"from urllib.parse import urlparse\n",
"import gzip \n",
"\n",
"def unzipfile(gzip_path):\n",
" \"\"\"unzip dataset file\n",
" Args:\n",
" gzip_path: dataset file path\n",
" \"\"\"\n",
" open_file = open(gzip_path.replace('.gz',''), 'wb')\n",
" gz_file = gzip.GzipFile(gzip_path)\n",
" open_file.write(gz_file.read())\n",
" gz_file.close()\n",
" \n",
"def download_dataset():\n",
" \"\"\"Download the dataset from http://yann.lecun.com/exdb/mnist/.\"\"\"\n",
" print(\"******Downloading the MNIST dataset******\")\n",
" train_path = \"./MNIST_Data/train/\" \n",
" test_path = \"./MNIST_Data/test/\"\n",
" train_path_check = os.path.exists(train_path)\n",
" test_path_check = os.path.exists(test_path)\n",
" if train_path_check == False and test_path_check == False:\n",
" os.makedirs(train_path)\n",
" os.makedirs(test_path)\n",
" train_url = {\"http://yann.lecun.com/exdb/mnist/train-images-idx3-ubyte.gz\", \"http://yann.lecun.com/exdb/mnist/train-labels-idx1-ubyte.gz\"}\n",
" test_url = {\"http://yann.lecun.com/exdb/mnist/t10k-images-idx3-ubyte.gz\", \"http://yann.lecun.com/exdb/mnist/t10k-labels-idx1-ubyte.gz\"}\n",
" \n",
" for url in train_url:\n",
" url_parse = urlparse(url)\n",
" # split the file name from url\n",
" file_name = os.path.join(train_path,url_parse.path.split('/')[-1])\n",
" if not os.path.exists(file_name.replace('.gz', '')):\n",
" file = urllib.request.urlretrieve(url, file_name)\n",
" unzipfile(file_name)\n",
" os.remove(file_name)\n",
" \n",
" for url in test_url:\n",
" url_parse = urlparse(url)\n",
" # split the file name from url\n",
" file_name = os.path.join(test_path,url_parse.path.split('/')[-1])\n",
" if not os.path.exists(file_name.replace('.gz', '')):\n",
" file = urllib.request.urlretrieve(url, file_name)\n",
" unzipfile(file_name)\n",
" os.remove(file_name)\n",
"\n",
"download_dataset()"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"这样就完成了数据集的下载解压缩工作。"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### 2、数据集处理"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"数据集处理对于训练非常重要,好的数据集可以有效提高训练精度和效率。在加载数据集前,我们通常会对数据集进行一些处理。\n",
"<br/>我们定义一个函数`create_dataset`来创建数据集。在这个函数中,我们定义好需要进行的数据增强和处理操作:\n",
"<br/>1、定义数据集。\n",
"<br/>2、定义进行数据增强和处理所需要的一些参数。\n",
"<br/>3、根据参数,生成对应的数据增强操作。\n",
"<br/>4、使用`map`映射函数,将数据操作应用到数据集。\n",
"<br/>5、对生成的数据集进行处理。"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"> 具体的数据集操作可以在MindInsight的数据溯源中进行可视化分析。另外提取图像需要将`normalize`算子的数据处理(`CV.Rescale`)操作取消,否则取出来的图像为全黑图像。"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"import mindspore.dataset.transforms.vision.c_transforms as CV\n",
"import mindspore.dataset.transforms.c_transforms as C\n",
"from mindspore.dataset.transforms.vision import Inter\n",
"from mindspore.common import dtype as mstype\n",
"import mindspore.dataset as ds\n",
"\n",
"def create_dataset(data_path, batch_size=32, repeat_size=1,\n",
" num_parallel_workers=1):\n",
" \"\"\" create dataset for train or test\n",
" Args:\n",
" data_path: Data path\n",
" batch_size: The number of data records in each group\n",
" repeat_size: The number of replicated data records\n",
" num_parallel_workers: The number of parallel workers\n",
" \"\"\"\n",
" # define dataset\n",
" mnist_ds = ds.MnistDataset(data_path)\n",
"\n",
" # Define some parameters needed for data enhancement and rough justification\n",
" resize_height, resize_width = 32, 32\n",
" rescale = 1.0 / 255.0\n",
" shift = 0.0\n",
" rescale_nml = 1 / 0.3081\n",
" shift_nml = -1 * 0.1307 / 0.3081\n",
"\n",
" # According to the parameters, generate the corresponding data enhancement method\n",
" resize_op = CV.Resize((resize_height, resize_width), interpolation=Inter.LINEAR) # Resize images to (32, 32) by bilinear interpolation\n",
" rescale_nml_op = CV.Rescale(rescale_nml, shift_nml) # normalize images\n",
" rescale_op = CV.Rescale(rescale, shift) # rescale images\n",
" hwc2chw_op = CV.HWC2CHW() # change shape from (height, width, channel) to (channel, height, width) to fit network.\n",
" type_cast_op = C.TypeCast(mstype.int32) # change data type of label to int32 to fit network\n",
"\n",
" # Using map() to apply operations to a dataset\n",
" mnist_ds = mnist_ds.map(input_columns=\"label\", operations=type_cast_op, num_parallel_workers=num_parallel_workers)\n",
" mnist_ds = mnist_ds.map(input_columns=\"image\", operations=resize_op, num_parallel_workers=num_parallel_workers)\n",
" mnist_ds = mnist_ds.map(input_columns=\"image\", operations=rescale_op, num_parallel_workers=num_parallel_workers)\n",
" mnist_ds = mnist_ds.map(input_columns=\"image\", operations=rescale_nml_op, num_parallel_workers=num_parallel_workers)\n",
" mnist_ds = mnist_ds.map(input_columns=\"image\", operations=hwc2chw_op, num_parallel_workers=num_parallel_workers)\n",
" \n",
" # Process the generated dataset\n",
" buffer_size = 10000\n",
" mnist_ds = mnist_ds.shuffle(buffer_size=buffer_size) # 10000 as in LeNet train script\n",
" mnist_ds = mnist_ds.batch(batch_size, drop_remainder=True)\n",
" mnist_ds = mnist_ds.repeat(repeat_size)\n",
"\n",
" return mnist_ds"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## 二、构建LeNet5网络"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### 使用ImageSummary记录图像数据"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"在构建LeNet5网络的`__init__`中,初始化`ImageSummary`算子,同时在`construct`中将`ImageSummary`放在第一步,其第一个参数`image`为抽取出来的图片的自定义命名,第二个参数`x`是图像数据。此方法与`SummaryCollector`抽取图像的方法不冲突,可以同时使用。"
]
},
{
"cell_type": "code",
"execution_count": 1,
"metadata": {},
"outputs": [],
"source": [
"from mindspore.ops import operations as P\n",
"import mindspore.nn as nn\n",
"from mindspore.common.initializer import TruncatedNormal\n",
"\n",
"# Initialize 2D convolution function\n",
"def conv(in_channels, out_channels, kernel_size, stride=1, padding=0):\n",
" \"\"\"Conv layer weight initial.\"\"\"\n",
" weight = weight_variable()\n",
" return nn.Conv2d(in_channels, out_channels,\n",
" kernel_size=kernel_size, stride=stride, padding=padding,\n",
" weight_init=weight, has_bias=False, pad_mode=\"valid\")\n",
"\n",
"# Initialize full connection layer\n",
"def fc_with_initialize(input_channels, out_channels):\n",
" \"\"\"Fc layer weight initial.\"\"\"\n",
" weight = weight_variable()\n",
" bias = weight_variable()\n",
" return nn.Dense(input_channels, out_channels, weight, bias)\n",
"\n",
"# Set truncated normal distribution\n",
"def weight_variable():\n",
" \"\"\"Weight initial.\"\"\"\n",
" return TruncatedNormal(0.02)\n",
"\n",
"class LeNet5(nn.Cell):\n",
" \"\"\"Lenet network structure.\"\"\"\n",
" # define the operator required\n",
" def __init__(self):\n",
" super(LeNet5, self).__init__()\n",
" self.batch_size = 32 # 32 pictures in each group\n",
" self.conv1 = conv(1, 6, 5) # Convolution layer 1, 1 channel input (1 Figure), 6 channel output (6 figures), convolution core 5 * 5\n",
" self.conv2 = conv(6, 16, 5) # Convolution layer 2,6-channel input, 16 channel output, convolution kernel 5 * 5\n",
" self.fc1 = fc_with_initialize(16 * 5 * 5, 120)\n",
" self.fc2 = fc_with_initialize(120, 84)\n",
" self.fc3 = fc_with_initialize(84, 10)\n",
" self.relu = nn.ReLU()\n",
" self.max_pool2d = nn.MaxPool2d(kernel_size=2, stride=2)\n",
" self.flatten = nn.Flatten()\n",
" #Init ImageSummary\n",
" self.sm_image = P.ImageSummary()\n",
"\n",
" # use the preceding operators to construct networks\n",
" def construct(self, x):\n",
" self.sm_image(\"image\",x)\n",
" x = self.conv1(x) # 1*32*32-->6*28*28\n",
" x = self.relu(x) # 6*28*28-->6*14*14\n",
" x = self.max_pool2d(x) # Pool layer\n",
" x = self.conv2(x) # Convolution layer\n",
" x = self.relu(x) # Function excitation layer\n",
" x = self.max_pool2d(x) # Pool layer\n",
" x = self.flatten(x) # Dimensionality reduction\n",
" x = self.fc1(x) # Full connection\n",
" x = self.relu(x) # Function excitation layer\n",
" x = self.fc2(x) # Full connection\n",
" x = self.relu(x) # Function excitation layer\n",
" x = self.fc3(x) # Full connection\n",
" return x"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## 三、训练网络和测试网络构建"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### 1、使用SummaryCollector放入到训练网络中记录训练数据"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"`summary_callback`,即是`SummaryCollector`,在`model.train`的回调函数中使用,可以记录训练数据溯源和模型溯源信息。"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Training and testing related modules\n",
"from mindspore.train.callback import ModelCheckpoint, CheckpointConfig, LossMonitor, SummaryCollector, Callback\n",
"from mindspore.train import Model\n",
"import os\n",
"\n",
"\n",
"def train_net(model, epoch_size, mnist_path, repeat_size, ckpoint_cb, summary_collector):\n",
" \"\"\"Define the training method.\"\"\"\n",
" print(\"============== Starting Training ==============\")\n",
" # load training dataset\n",
" ds_train = create_dataset(os.path.join(mnist_path, \"train\"), 32, repeat_size)\n",
" model.train(epoch_size, ds_train, callbacks=[ckpoint_cb, LossMonitor(), summary_collector], dataset_sink_mode=True)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### 2、使用SummaryCollector放入到测试网络中记录测试数据"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"`summary_callback`,即是`SummaryCollector`,在`model.eval`的回调函数中使用,可以记录训练精度信息和测试样本数量信息。"
]
},
{
"cell_type": "code",
"execution_count": 3,
"metadata": {},
"outputs": [],
"source": [
"from mindspore.train.serialization import load_checkpoint, load_param_into_net\n",
"\n",
"def test_net(network, model, mnist_path, summary_collector):\n",
" \"\"\"Define the evaluation method.\"\"\"\n",
" print(\"============== Starting Testing ==============\")\n",
" # load the saved model for evaluation\n",
" param_dict = load_checkpoint(\"checkpoint_lenet-3_1875.ckpt\")\n",
" # load parameter to the network\n",
" load_param_into_net(network, param_dict)\n",
" # load testing dataset\n",
" ds_eval = create_dataset(os.path.join(mnist_path, \"test\"))\n",
" acc = model.eval(ds_eval, callbacks=[summary_collector], dataset_sink_mode=True)\n",
" print(\"============== Accuracy:{} ==============\".format(acc))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### 3、主程序运行入口"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"初始化`SummaryCollector`,使用`collect_specified_data`控制需要记录的数据,我们这里只需要记录模型溯源和数据溯源,所以将`collect_train_lineage`和`collect_eval_lineage`参数设置成`True`,其他的参数使用`keep_default_action`设置成`False`,SummaryCollector能够记录哪些数据,请参考官网:https://www.mindspore.cn/api/zh-CN/master/api/python/mindspore/mindspore.train.html?highlight=collector#mindspore.train.callback.SummaryCollector 。"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"from mindspore.train.callback import SummaryCollector\n",
"from mindspore.train.summary.summary_record import SummaryRecord\n",
"from mindspore.nn.metrics import Accuracy\n",
"from mindspore import context\n",
"from mindspore.nn.loss import SoftmaxCrossEntropyWithLogits\n",
"\n",
"if __name__==\"__main__\":\n",
" context.set_context(mode=context.GRAPH_MODE, device_target = \"GPU\")\n",
" lr = 0.01 # learning rate\n",
" momentum = 0.9 \n",
" epoch_size = 3\n",
" mnist_path = \"./MNIST_Data\"\n",
" \n",
" net_loss = SoftmaxCrossEntropyWithLogits(is_grad=False, sparse=True, reduction='mean')\n",
" repeat_size = epoch_size\n",
" # create the network\n",
" network = LeNet5()\n",
"\n",
" # define the optimizer\n",
" net_opt = nn.Momentum(network.trainable_params(), lr, momentum)\n",
" config_ck = CheckpointConfig(save_checkpoint_steps=1875, keep_checkpoint_max=10)\n",
" ckpoint_cb = ModelCheckpoint(prefix=\"checkpoint_lenet\", config=config_ck)\n",
" model = Model(network, net_loss, net_opt, metrics={\"Accuracy\": Accuracy()})\n",
" \n",
" collect_specified_data = {\"collect_eval_lineage\":True,\"collect_train_lineage\":True}\n",
" summary_collector = SummaryCollector(summary_dir=\"./summary_base/quick_start_summary01\", collect_specified_data=collect_specified_data, keep_default_action=False) \n",
" train_net(model, epoch_size, mnist_path, repeat_size, ckpoint_cb, summary_collector)\n",
" test_net(network, model, mnist_path, summary_collector)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## 五、启动及关闭MindInsight服务"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"这里主要展示如何启用及关闭MindInsight,更多的命令集信息,请参考MindSpore官方网站:https://www.mindspore.cn/tutorial/zh-CN/master/advanced_use/visualization_tutorials.html 。"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"- 启动MindInsight服务\n",
"\n",
" 在安装过MindInsight的环境中启动MindInsight服务:\n",
" - `--summary-base-dir`:MindInsight指定启动工作路径的命令。\n",
" - `./summary_base`:SummaryRecord保存文件夹的目录。\n",
" - `--port`:MindInsight指定启动的端口,数值可以任意为1~65535的范围内。"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"import os\n",
"os.system(\"mindinsight start --summary-base-dir=./summary_base --port=8090\")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"查询是否启动成功,在网址输入:`127.0.0.1:8090`,如果看到如下界面说明启动成功。"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
""
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"- 关闭MindInsight服务\n",
"\n",
" 在安装过MindInsight的环境中输入命令:`mindinsight stop --port=8090`\n",
" - `mindinsight stop`:MindInsight关闭服务命令。\n",
" - `--port=8090`:即MindInsight服务开启在`8090`端口,所以这里写成`--port=8090`。"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## 六、模型溯源"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### 1、连接到模型溯源地址"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
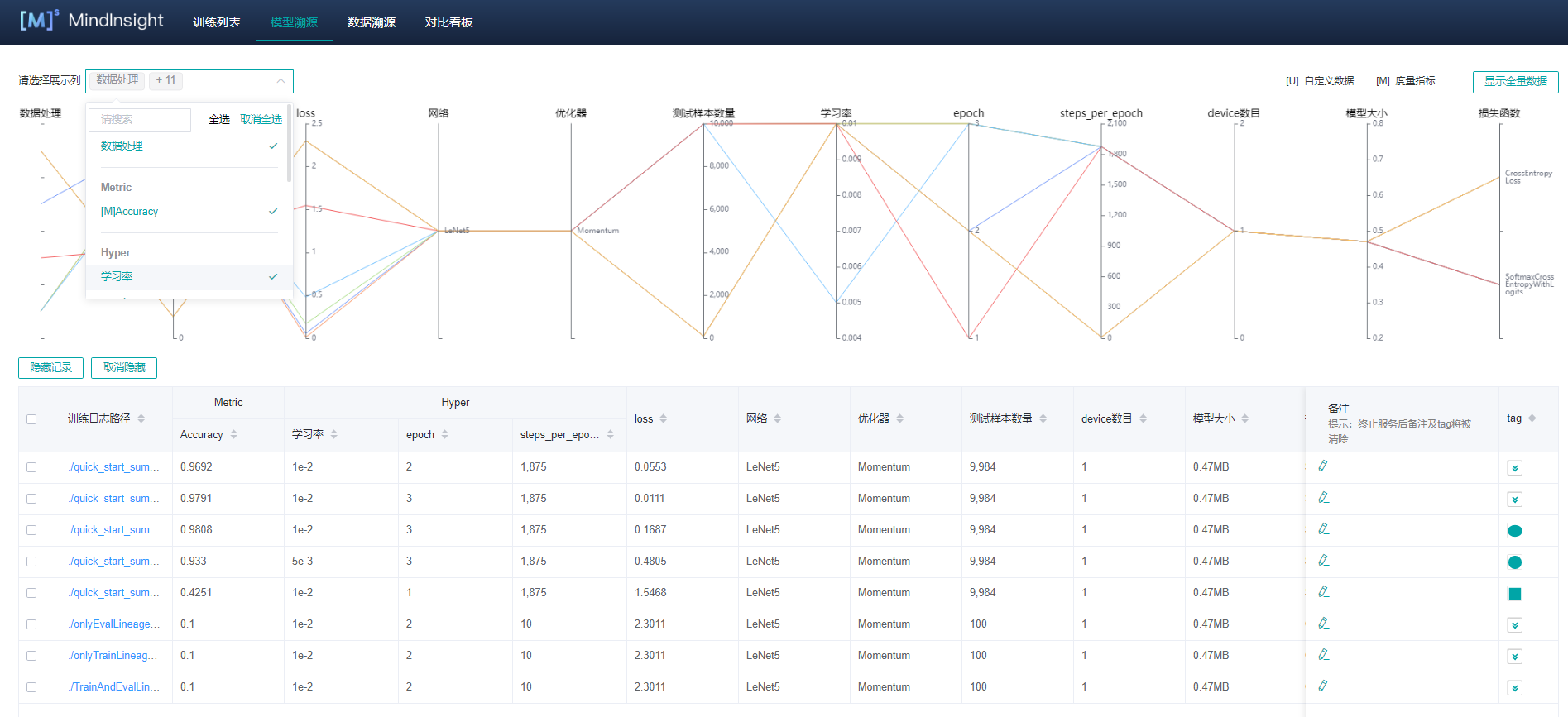
"浏览器中输入:`127.0.0.1:8090`,点击模型溯源,如下模型溯源界面:"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
""
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"我们可以勾选展示列,由于训练过程涉及的参数很多,在调整训练参数时,一般只会调整少量参数,所以对大部分相同参数可以去掉勾选,不显示出来,使得用户更方便的观察不同参数对模型训练的影响,上图中的不同参数的竖直线段代表的各个参数,数根连接各个参数的折线图代表不同的模型训练过程,其中各参数从左到右如下:"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"- `summary路径`:表示存储记录数据的文件夹路径,即`summary_dir`。\n",
"- `Accuracy`:模型的精度值。\n",
"- `loss`:模型的loss值。\n",
"- 网络:表示神经网络名称(用户可自行命名)。\n",
"- 优化器:表示训练过程中采用的优化器。\n",
"- 训练样本数量:训练样本数量。\n",
"- 测试样本数量:测试样本数量。\n",
"- 学习率:learning_rate的值。\n",
"- `epoch`:训练圈数。\n",
"- `steps`:训练步数。\n",
"- device数目:启用的训练卡数目。\n",
"- 模型大小:生成的模型文件`.ckpt`的大小。\n",
"- 损失函数:表示训练过程中采用的损失函数(用户可自行命名)。"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"根据上述记录的信息,我们可以调整模型训练过程中的参数,训练生成模型,然后选择要对比的训练,进行比对观察分析。"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### 2、观察分析记录下来的溯源参数"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
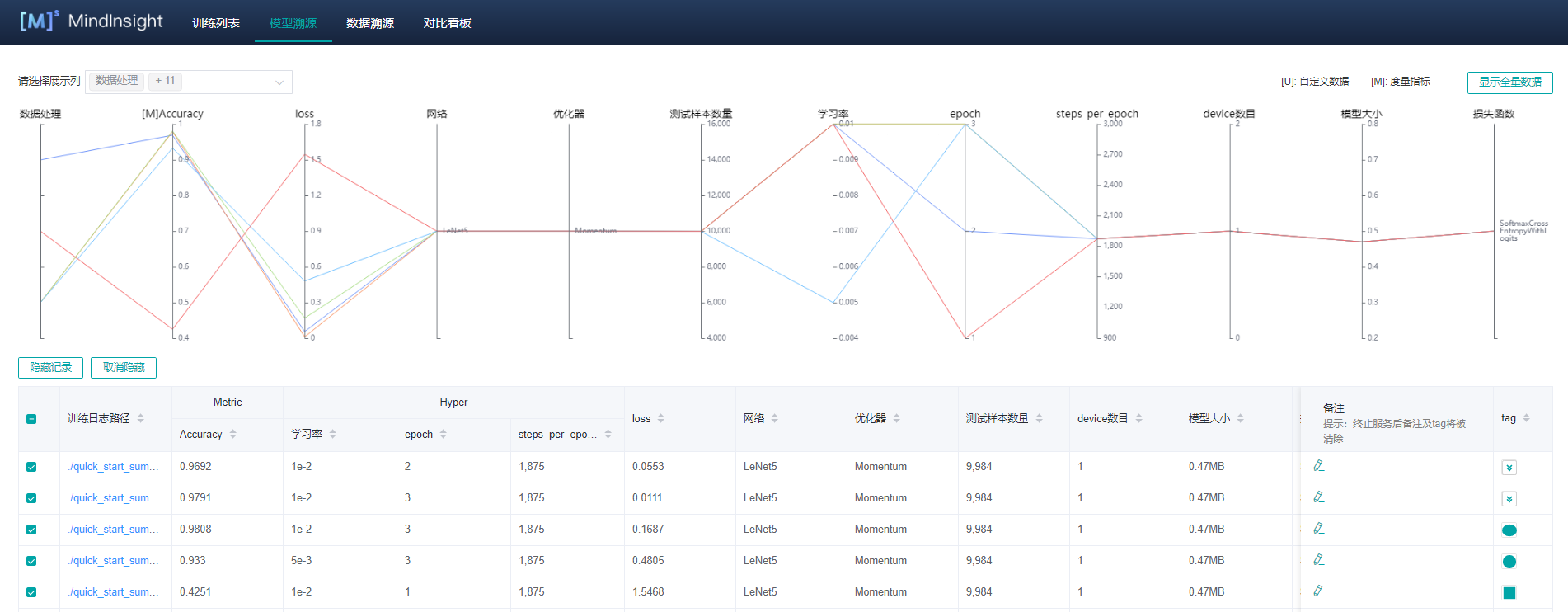
"下图选择了数条不同参数下训练生成的模型进行对比:"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
""
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"在这几次训练的参数中,优化器,epoch和学习率都不一致,可以看到不同的训练生成的模型精度`Accuracy`和loss值是不一致的,当然最好是调整单个参数来观察对模型生成的影响,避免多重因素干扰,难以分辨哪个参数是正影响,哪个参数是负影响。这需要我们调整不同的参数,多训练几遍生成模型,分析各参数对训练产生的影响,这对前期学习AI训练时很有帮助。在以后应对复杂训练时,可以节省不少时间。\n",
"> 在多次训练时,需要将`summary_dir`的保存路径的文件夹进行重命名操作,否则训练记录的数据会生成在同一个文件夹下,而在同一文件夹下MindInsight只会读取最后一位数字比较大的文件即最后生成的文件。"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## 七、数据溯源"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### 1、连接到数据溯源地址:"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
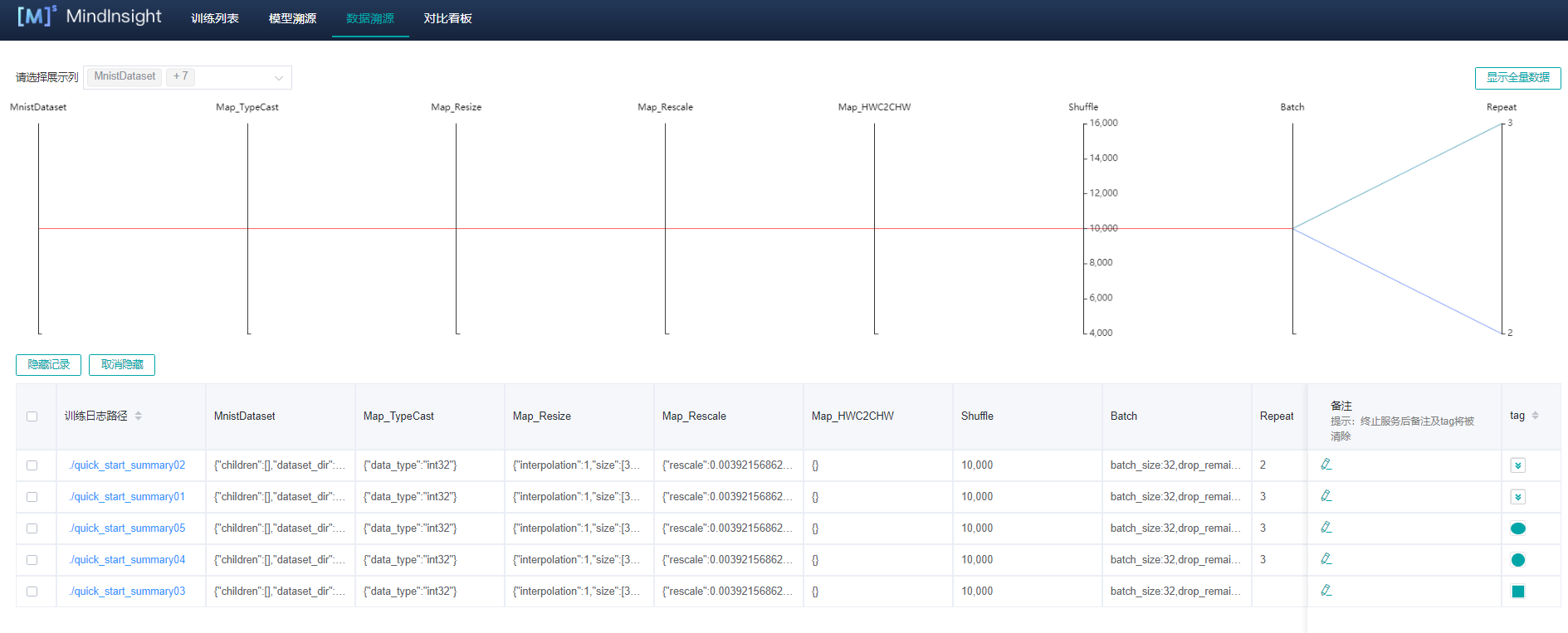
"浏览器中输入:127.0.0.1:8090连接上MindInsight的服务,点击模型溯源,如下图数据溯源界面:"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
""
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"数据溯源的根本是重现数据集从左到右进行数据增强的整个过程,方便自己发现增强过程中是否有遗漏的步骤或者不合理的操作,方便自己查找错误,也方便自己找到最优的数据增强方式,毕竟一个好的数据集对模型训练是有事半功倍的效果的。"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"- `summary路径`:表示存储记录数据的文件夹名称,即为`SummaryRecord`的路径下的文件夹名称。\n",
"- `MnistDataset`:表示数据集信息,包含数据集路径。\n",
"- `Map_TypeCast`:定义数据集的类型。\n",
"- `Map_Resize`:图像缩放后的尺寸。\n",
"- `Map_Rescale`:图像的缩放比例。\n",
"- `Map_HWC2CHW`:数据集的张量由:高×宽×通道-->通道×高×宽。\n",
"- `Shuffle`:数据集混洗的缓存空间。\n",
"- `Batch`:每组训练样本数量。\n",
"- `Repeat`:数据图片复制次数,用于增强数据的数量。"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"- 关闭MindInsight服务"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"import os\n",
"os.system(\"mindinsight stop --port=8090\")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"以上就是这次对MindInsight的使用方法,模型溯源和数据溯源的全部过程。"
]
}
],
"metadata": {
"kernelspec": {
"display_name": "Python 3",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.7.6"
}
},
"nbformat": 4,
"nbformat_minor": 4
}
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}
{kind=link}
{kind=link}
{kind=link}
