!318 add Mindinsight Notebook Doc for histogram,image and scalar to r0.5
Merge pull request !318 from zhangyi/MindInsightDoc_Add_r0.5
Showing
{kind=link}
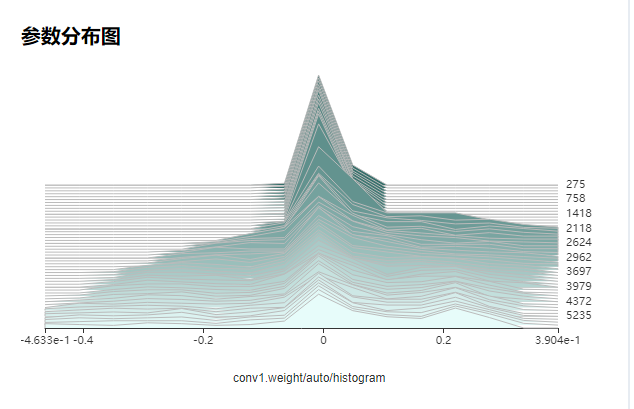
84.7 KB
{kind=link}

7.7 KB
{kind=link}
151.8 KB
{kind=link}
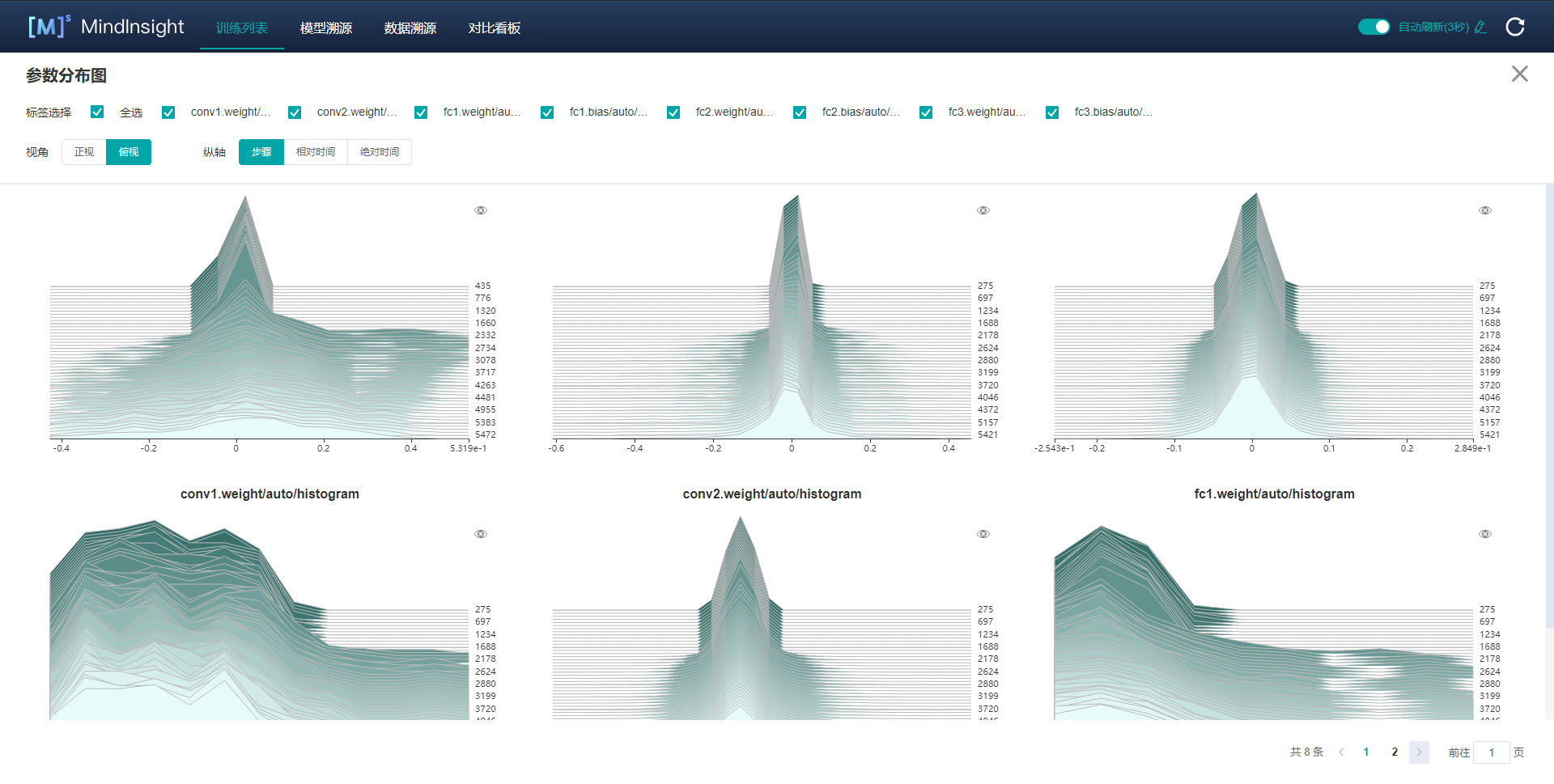
530.0 KB
{kind=link}
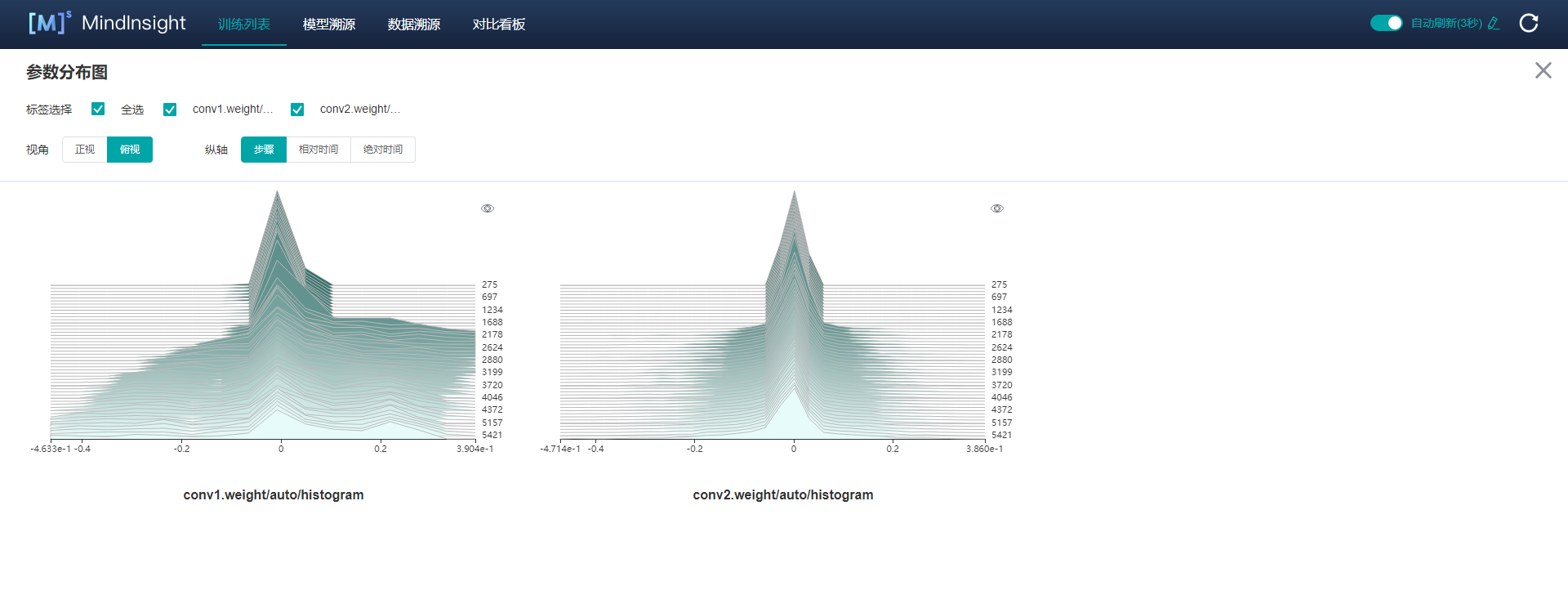
211.1 KB
{kind=link}

6.3 KB
{kind=link}
129.7 KB
{kind=link}
79.0 KB
{kind=link}
45.7 KB
{kind=link}
76.2 KB
{kind=link}

19.4 KB
{kind=link}
216.1 KB
{kind=link}
29.3 KB
{kind=link}
21.8 KB
{kind=link}
11.1 KB
{kind=link}
17.3 KB
{kind=link}
41.4 KB
{kind=link}

8.1 KB