MindSpore Lite is a lightweight deep neural network inference engine that provides the inference function for models trained by MindSpore on the device side. This tutorial describes how to use and compile MindSpore Lite.

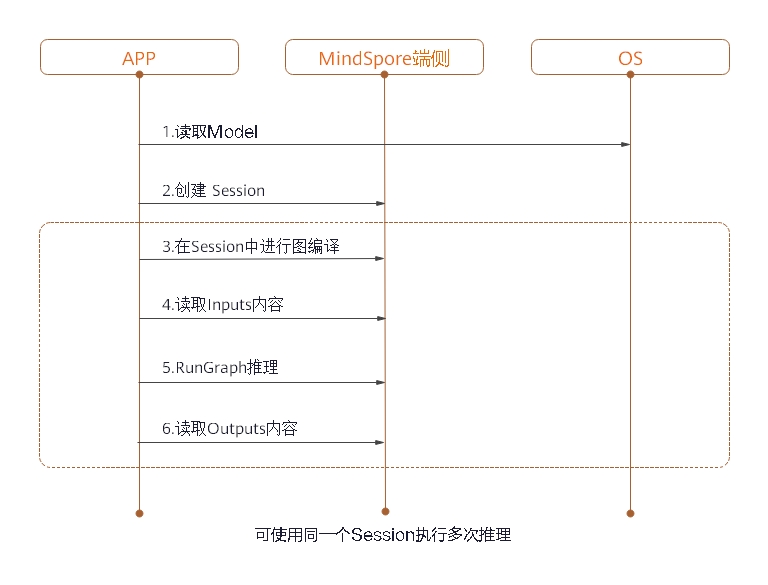
Figure 1 On-device inference frame diagram
Mindspore Lite's framework consists of frontend, IR, backend, Lite, RT and micro.
- Frontend: It used for model generation. Users can use the model building interface to build models, or transform third-party models into mindspore models.
- IR: It includes the tensor definition, operator prototype definition and graph definition of mindspore. The back-end optimization is based on IR.
- Backend: Graph optimization and high level optimization are independent of hardware, such as operator fusion and constant folding, while low level optimization is related to hardware; quantization includes weight quantization, activation value quantization and other post training quantization methods.
- Lite RT: In the inference runtime, session provides the external interface, kernel registry is operator registry, scheduler is operator heterogeneous scheduler and executor is operator executor. Lite RT and shares with Micro the underlying infrastructure layers such as operator library, memory allocation, runtime thread pool and parallel primitives.
- Micro: Code Gen generates .c files according to the model, and infrastructure such as the underlying operator library is shared with Lite RT.
## Compilation Method
You need to compile the MindSpore Lite by yourself. This section describes how to perform cross compilation in the Ubuntu environment.
3. Run the following command in the root directory of the source code to compile MindSpore Lite.
```bash
cd mindspore/lite
sh build.sh
```
4. Obtain the compilation result.
Go to the `lite/build` directory of the source code to view the generated documents. Then you can use various tools after changing directory.
## Use of On-Device Inference
When MindSpore is used to perform model inference in the APK project of an app, preprocessing input is required before model inference. For example, before an image is converted into the tensor format required by MindSpore inference, the image needs to be resized. After MindSpore completes model inference, postprocess the model inference result and sends the processed output to the app.
This section describes how to use MindSpore to perform model inference. The setup of an APK project and pre- and post-processing of model inference are not described here.
To perform on-device model inference using MindSpore, perform the following steps.
### Generating an On-Device Model File
1. After training is complete, load the generated checkpoint file to the defined network.
INFO [converter/converter.cc:146] Runconverter] CONVERTER RESULT: SUCCESS!
```
This means that the model has been successfully converted to the mindspore on_device inference model.
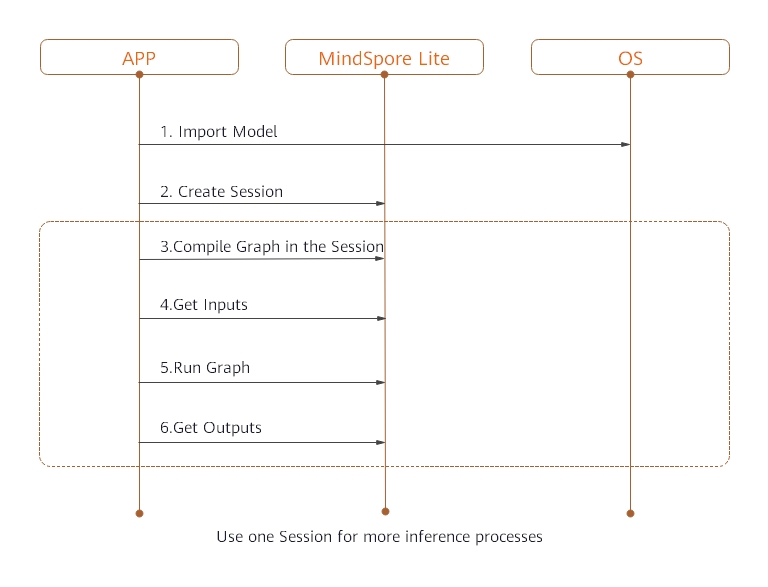
### Implementing On-Device Inference
Use the `.ms` model file and image data as input to create a session and implement inference on the device.

1. Load the `.ms` model file to the memory buffer. The ReadFile function needs to be implemented by users, according to the [C++ tutorial](http://www.cplusplus.com/doc/tutorial/files/).
{kind=link}

{kind=link}
{kind=link}

{kind=link}