Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
MindSpore
course
提交
58a87f49
C
course
项目概览
MindSpore
/
course
通知
4
Star
0
Fork
0
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
0
列表
看板
标记
里程碑
合并请求
0
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
C
course
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
0
Issue
0
列表
看板
标记
里程碑
合并请求
0
合并请求
0
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
提交
58a87f49
编写于
8月 25, 2020
作者:
D
dyonghan
提交者:
Gitee
8月 25, 2020
浏览文件
操作
浏览文件
下载
差异文件
!15 add Graph_Convolutional_Network
Merge pull request !15 from zhengnengjin2/update
上级
b4276402
05e415ec
变更
9
显示空白变更内容
内联
并排
Showing
9 changed file
with
1120 addition
and
0 deletion
+1120
-0
graph_convolutional_network/README.md
graph_convolutional_network/README.md
+443
-0
graph_convolutional_network/graph_to_mindrecord/citeseer/mr_api.py
...volutional_network/graph_to_mindrecord/citeseer/mr_api.py
+128
-0
graph_convolutional_network/graph_to_mindrecord/cora/mr_api.py
..._convolutional_network/graph_to_mindrecord/cora/mr_api.py
+105
-0
graph_convolutional_network/graph_to_mindrecord/graph_map_schema.py
...olutional_network/graph_to_mindrecord/graph_map_schema.py
+145
-0
graph_convolutional_network/graph_to_mindrecord/writer.py
graph_convolutional_network/graph_to_mindrecord/writer.py
+195
-0
graph_convolutional_network/images/gcn1.png
graph_convolutional_network/images/gcn1.png
+0
-0
graph_convolutional_network/images/gcn2.png
graph_convolutional_network/images/gcn2.png
+0
-0
graph_convolutional_network/images/t-SNE_visualization_on_Cora.gif
...volutional_network/images/t-SNE_visualization_on_Cora.gif
+0
-0
graph_convolutional_network/main.py
graph_convolutional_network/main.py
+104
-0
未找到文件。
graph_convolutional_network/README.md
0 → 100644
浏览文件 @
58a87f49
# Graph_Convolutional_Network
## Graph_Convolutional_Network原理
### 图卷积神经网络由来
**为什么传统的卷积神经网络不能直接运用到图上?还需要设计专门的图卷积网络?**
简单来说,卷积神经网络的研究的对象是限制在Euclidean domains的数据。Euclidean data最显著的特征就是有规则的空间结构,比如图片是规则的正方形栅格,或者语音是规则的一维序列。而这些数据结构能够用一维、二维的矩阵表示,卷积神经网络处理起来很高效。但是,我们的现实生活中有很多数据并不具备规则的空间结构,称为Non Euclidean data。比如推荐系统、电子交易、计算几何、脑信号、分子结构等抽象出的图谱。这些图谱结构每个节点连接都不尽相同,有的节点有三个连接,有的节点有两个连接,是不规则的数据结构。
如下图所示左图是欧式空间数据,右图为非欧式空间数据。其中绿色节点为卷积核。
> **观察可以发现**
>
> 1. 在图像为代表的欧式空间中,结点的邻居数量都是固定的。比如说绿色结点的邻居始终是8个。在图这种非欧空间中,结点有多少邻居并不固定。目前绿色结点的邻居结点有2个,但其他结点也会有5个邻居的情况。
> 2. 欧式空间中的卷积操作实际上是用固定大小可学习的卷积核来抽取像素的特征。对于非欧式空间因为邻居结点不固定,所以传统的卷积核不能直接用于抽取图上结点的特征。

为了解决传统卷积不能直接应用在邻居结点数量不固定的非欧式空间数据上的问题。
1.
提出一种方式把非欧空间的图转换成欧式空间。
2.
找出一种可处理变长邻居结点的卷积核在图上抽取特征。(图卷积属于这一种,后边又将其分为基于空间域和基于频域)
### 图卷积神经网络概述
GCN的本质目的就是用来提取拓扑图的空间特征。 图卷积神经网络主要有两类,一类是基于空间域(spatial domain)或顶点域(vertex domain)的,另一类则是基于频域或谱域(spectral domain)的。GCN属于频域图卷积神经网络。
基于空域卷积的方法直接将卷积操作定义在每个结点的连接关系上,它跟传统的卷积神经网络中的卷积更相似一些。在这个类别中比较有代表性的方法有 Message Passing Neural Networks(MPNN), GraphSage, Diffusion Convolution Neural Networks(DCNN), PATCHY-SAN等。
频域方法希望借助图谱的理论来实现拓扑图上的卷积操作。从整个研究的时间进程来看:首先研究GSP(graph signal processing)的学者定义了graph上的傅里叶变化(Fourier Transformation),进而定义了graph上的卷积,最后与深度学习结合提出了Graph Convolutional Network(GCN)。
### GCN网络过程
过程:
1.
定义graph上的Fourier Transformation傅里叶变换
2.
定义graph上的convolution卷积
#### 图上的傅里叶变换
传统的傅里叶变换:
$$
F(w) =
\i
nt f(t)e^{-jwt}dt
$$
其中$ e^{-jwt} $为基函数、特征向量。
注:特征向量定义:特征方程$ AV=
\l
ambda V $中V为特征向量,$
\l
ambda $为特征值
由于图节点为离散的,我们将上面傅里叶变换离散化,使用有限项分量来近似F(w) ,得到图上的傅里叶变换:
$ F(
\l
ambda _l) =
\h
at {f(
\l
ambda _l)} =
\s
um_{i=1}^{N}{f(i)}u_l(i)i $
其中$u_l(i)$为基函数、特征向量,$
\l
ambda _l$为$u_l(i)$对应的特征值,$ f(i)$为特i征值$
\l
ambda _l$下的$f$ 。即:特征值$
\l
ambda _l$下的$f$ 的傅里叶变换是该分量与$
\l
ambda _l$对应的特征向量$u_l$进行内积运算。这里用拉普拉斯向量$u_l$替换傅里叶变换的基$ e^{-jwt} $,后边我们将定义拉普拉斯矩阵。
利用矩阵乘法将Graph上的傅里叶变换推广到矩阵形式:
$$
\l
eft[
\b
egin{matrix}
\h
at {f(
\l
ambda _1)}
\\
\h
at {f(
\l
ambda _2)}
\\
...
\\
\h
at {f(
\l
ambda _N)}
\e
nd{matrix}
\r
ight] =
\l
eft[
\b
egin{matrix} u_1(1) & u_1(2) & ... & u_1(N)
\\
u_2(1) & u_2(2) & ... & u_2(N)
\\
... & ... & ... & ...
\\
u_N(1) & u_N(2) & ... & u_N(N)
\e
nd{matrix}
\r
ight]
\l
eft[
\b
egin{matrix} {f(1)}
\\
{f(2)}
\\
...
\\
{f(N)}
\e
nd{matrix}
\r
ight]
$$
即 f 在Graph上傅里叶变换的矩阵形式为:$
\h
at f = U^Tf$
f 在Graph上傅里叶逆变换的矩阵形式为:$f = U
\h
at f$
其中$U$为f的特征矩阵,拉普拉斯矩阵的正交基(后边我们会提到拉普拉斯矩阵)。它是一个对称正交矩阵,故$U^T=U^{-1}$
#### 图卷积
传统卷积:
卷积定理:函数$f(t)$、$h(t)$(h为卷积核)的卷积是其傅里叶变换的逆运算,所以传统卷积可以定义为:
$$
f
*
h = F^{-1}[
\h
at {f(w)}
\h
at {h(w)}] =
\f
rac{1}{2
\p
i}
\i
nt
\h
at {f(w)}
\h
at {h(w)}e^jwtdw
$$
图卷积:
根据卷积定理和前面得到的Graph上的傅里叶逆变换可以得到图卷积为:
$$
(f
*
h)_G = F^{-1}[U^Tf F(h)]=UF(h)U^Tf
$$
其中h为卷积核,F(h)为h的傅里叶变换。
将F(h)写成对角矩阵形式得到:
$$
H = F(h)=
\l
eft[
\b
egin{matrix}
\h
at {h(
\l
ambda _1)} & &
\\
& ... &
\\
& &
\h
at {h(
\l
ambda _N)}
\e
nd{matrix}
\r
ight]
$$
图卷积可以写成如下形式:
$$
(f
*
h)_G = U
\l
eft[
\b
egin{matrix}
\h
at {h(
\l
ambda _1)} & &
\\
& ... &
\\
& &
\h
at {h(
\l
ambda _N)}
\e
nd{matrix}
\r
ight]U^Tf = Lf
$$
其中L为拉普拉斯矩阵。U为L的正交化矩阵。上面式子也是GCN算法计算公式,通俗的解释,我们可以把GCN看成是基于拉普拉斯矩阵的特征分解。
### 拉普拉斯矩阵
GCN的核心基于拉普拉斯矩阵的谱分解(特征分解)。所以GCN算法的关键在于定义拉普拉斯矩阵。
本文的拉普拉斯矩阵定义如下:
$$
L =
\w
idetilde U^{-
\f
rac{1}{2}}
\w
idetilde H
\w
idetilde U^{-
\f
rac{1}{2}}
$$
其中
$$
\w
idetilde U^{-
\f
rac{1}{2}}
\w
idetilde H
\w
idetilde U^{-
\f
rac{1}{2}} = I + U^{-
\f
rac{1}{2}}HU^{-
\f
rac{1}{2}}
$$
$$
\w
idetilde H= H + I
\\
\w
idetilde U_{ii} =
\s
um_{j}
\w
idetilde H_{ij}
$$
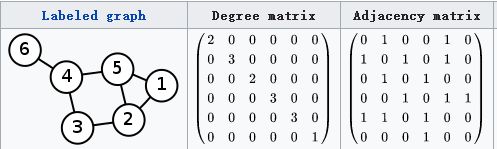
U取图的度矩阵(如下图中的degree matrix),H取图的邻接矩阵(如下图中的adjacency matrix)

[
Graph_Convolutional_Network原理引用于论文
]:
https://arxiv.org/pdf/1609.02907.pdf
## 实验介绍
图卷积网络(Graph Convolutional Network,GCN)是近年来逐渐流行的一种神经网络结构。不同于只能用于网格结构(grid-based)数据的传统网络模型 LSTM 和 CNN,图卷积网络能够处理具有广义拓扑图结构的数据,并深入发掘其特征和规律。
本实验主要介绍在下载的Cora和Citeseer数据集上使用MindSpore进行图卷积网络的训练。
## 实验目的
-
了解GCN相关知识;
-
在MindSpore中使用Cora和Citeseer数据集训练GCN示例。
## 预备知识
-
熟练使用Python,了解Shell及Linux操作系统基本知识。
-
具备一定的深度学习理论知识,如前馈神经网络、卷积神经网络、图卷积网络等。
-
了解并熟悉MindSpore AI计算框架,MindSpore官网:
[
https://www.mindspore.cn
](
https://www.mindspore.cn/
)
## 实验环境
-
MindSpore 0.5.0(MindSpore版本会定期更新,本指导也会定期刷新,与版本配套);
-
华为云ModelArts:ModelArts是华为云提供的面向开发者的一站式AI开发平台,集成了昇腾AI处理器资源池,用户可以在该平台下体验MindSpore。ModelArts官网:https://www.huaweicloud.com/product/modelarts.html
## 实验准备
### 数据集准备
从
[
github
](
https://github.com/kimiyoung/planetoid
)
下载/kimiyoung/planetoid提供的数据集Cora或Citeseer。这是Planetoid的一种实现,以下论文提出了一种基于图的半监督学习方法:
[
图嵌入技术在半监督学习中的应用
](
https://arxiv.org/abs/1603.08861
)
将数据集放置到所需的路径下,该文件夹应包含以下文件:
```
└─data
├─ind.cora.allx
├─ind.cora.ally
├─...
├─ind.cora.test.index
├─trans.citeseer.tx
├─trans.citeseer.ty
├─...
└─trans.pubmed.y
```
其中模型的输入包含:
-
`x`
,标记训练实例的特征向量,
-
`y`
,即已标记的训练实例的热门标签,
-
`allx`
,标记的和未标记的训练实例(的超集
`x`
)的特征向量,
-
`graph`
,
`dict`
格式为
`{index: [index_of_neighbor_nodes]}.`
令n为标记和未标记训练实例的数量。这n个实例的索引应从0到n-1
`graph`
,其顺序与中的顺序相同
`allx`
。
除了
`x`
,
`y`
,
`allx`
,和
`graph`
如上所述,预处理的数据集还包括:
-
`tx`
,测试实例的特征向量,
-
`ty`
,测试实例的热门标签,
-
`test.index`
,
`graph`
对于归纳设置,中的测试实例的索引,
-
`ally`
,是中实例的标签
`allx`
。
`graph`
转换设置中测试实例的索引是从
`#x`
到
`#x + #tx - 1`
,与中的顺序相同
`tx`
。
### 脚本准备
从
[
MindSpore model_zoo
](
https://gitee.com/mindspore/mindspore/tree/r0.5/model_zoo/gcn
)
中下载GCN代码;
[
课程gitee仓库
](
https://gitee.com/mindspore/course
)
上下载本实验相关脚本。
### 上传文件
将脚本和数据集放到到experiment文件夹中,组织为如下形式:
```
experiment
├── data
├── graph_to_mindrecord
│ ├── citeseer
│ ├── cora
│ ├── graph_map_schema.py
│ ├── writer.py
│── src
│ ├── config.py
│ ├── dataset.py
│ ├── gcn.py
│ ├── metrics.py
│── README.md
└── main.py
```
## 实验步骤
### 代码梳理
#### 数据处理
将Cora或Citeseer生成mindrecord格式的数据集。(可在cfg中设置
`DATASET_NAME`
为cora或者citeseer来转换不同的数据集)
```
python
def
run
(
cfg
):
args
=
read_args
()
#建立输出文件夹
cur_path
=
os
.
getcwd
()
M_PATH
=
os
.
path
.
join
(
cur_path
,
cfg
.
MINDRECORD_PATH
)
if
os
.
path
.
exists
(
M_PATH
):
shutil
.
rmtree
(
M_PATH
)
# 删除文件夹
os
.
mkdir
(
M_PATH
)
cfg
.
SRC_PATH
=
os
.
path
.
join
(
cur_path
,
cfg
.
SRC_PATH
)
#参数
args
.
mindrecord_script
=
cfg
.
DATASET_NAME
args
.
mindrecord_file
=
os
.
path
.
join
(
cfg
.
MINDRECORD_PATH
,
cfg
.
DATASET_NAME
)
args
.
mindrecord_partitions
=
cfg
.
mindrecord_partitions
args
.
mindrecord_header_size_by_bit
=
cfg
.
mindrecord_header_size_by_bit
args
.
mindrecord_page_size_by_bit
=
cfg
.
mindrecord_header_size_by_bit
args
.
graph_api_args
=
cfg
.
SRC_PATH
start_time
=
time
.
time
()
# pass mr_api arguments
os
.
environ
[
'graph_api_args'
]
=
args
.
graph_api_args
try
:
mr_api
=
import_module
(
'graph_to_mindrecord.'
+
args
.
mindrecord_script
+
'.mr_api'
)
except
ModuleNotFoundError
:
raise
RuntimeError
(
"Unknown module path: {}"
.
format
(
args
.
mindrecord_script
+
'.mr_api'
))
# init graph schema
graph_map_schema
=
GraphMapSchema
()
num_features
,
feature_data_types
,
feature_shapes
=
mr_api
.
node_profile
graph_map_schema
.
set_node_feature_profile
(
num_features
,
feature_data_types
,
feature_shapes
)
num_features
,
feature_data_types
,
feature_shapes
=
mr_api
.
edge_profile
graph_map_schema
.
set_edge_feature_profile
(
num_features
,
feature_data_types
,
feature_shapes
)
graph_schema
=
graph_map_schema
.
get_schema
()
```
### 参数配置
训练参数可以在config.py中设置。
```
shell
"learning_rate"
: 0.01,
# Learning rate
"epochs"
: 200,
# Epoch sizes for training
"hidden1"
: 16,
# Hidden size for the first graph convolution layer
"dropout"
: 0.5,
# Dropout ratio for the first graph convolution layer
"weight_decay"
: 5e-4,
# Weight decay for the parameter of the first graph convolution layer
"early_stopping"
: 10,
# Tolerance for early stopping
```
### 运行训练
```
shell
def train
(
args_opt
)
:
"""Train model."""
np.random.seed
(
args_opt.seed
)
config
=
ConfigGCN
()
adj, feature, label
=
get_adj_features_labels
(
args_opt.data_dir
)
nodes_num
=
label.shape[0]
train_mask
=
get_mask
(
nodes_num, 0, args_opt.train_nodes_num
)
eval_mask
=
get_mask
(
nodes_num, args_opt.train_nodes_num, args_opt.train_nodes_num + args_opt.eval_nodes_num
)
test_mask
=
get_mask
(
nodes_num, nodes_num - args_opt.test_nodes_num, nodes_num
)
class_num
=
label.shape[1]
gcn_net
=
GCN
(
config, adj, feature, class_num
)
gcn_net.add_flags_recursive
(
fp16
=
True
)
eval_net
=
LossAccuracyWrapper
(
gcn_net, label, eval_mask, config.weight_decay
)
test_net
=
LossAccuracyWrapper
(
gcn_net, label, test_mask, config.weight_decay
)
train_net
=
TrainNetWrapper
(
gcn_net, label, train_mask, config
)
loss_list
=
[]
for
epoch
in
range
(
config.epochs
)
:
t
=
time.time
()
train_net.set_train
()
train_result
=
train_net
()
train_loss
=
train_result[0].asnumpy
()
train_accuracy
=
train_result[1].asnumpy
()
eval_net.set_train
(
False
)
eval_result
=
eval_net
()
eval_loss
=
eval_result[0].asnumpy
()
eval_accuracy
=
eval_result[1].asnumpy
()
loss_list.append
(
eval_loss
)
if
epoch%10
==
0:
print
(
"Epoch:"
,
'%04d'
%
(
epoch
)
,
"train_loss="
,
"{:.5f}"
.format
(
train_loss
)
,
"train_acc="
,
"{:.5f}"
.format
(
train_accuracy
)
,
"val_loss="
,
"{:.5f}"
.format
(
eval_loss
)
,
"val_acc="
,
"{:.5f}"
.format
(
eval_accuracy
)
,
"time="
,
"{:.5f}"
.format
(
time.time
()
- t
))
if
epoch
>
config.early_stopping and loss_list[-1]
>
np.mean
(
loss_list[-
(
config.early_stopping+1
)
:-1]
)
:
print
(
"Early stopping..."
)
break
t_test
=
time.time
()
test_net.set_train
(
False
)
test_result
=
test_net
()
test_loss
=
test_result[0].asnumpy
()
test_accuracy
=
test_result[1].asnumpy
()
print
(
"Test set results:"
,
"loss="
,
"{:.5f}"
.format
(
test_loss
)
,
"accuracy="
,
"{:.5f}"
.format
(
test_accuracy
)
,
"time="
,
"{:.5f}"
.format
(
time.time
()
- t_test
))
if
__name__
==
'__main__'
:
#------------------------定义变量------------------------------
parser
=
argparse.ArgumentParser
(
description
=
'GCN'
)
parser.add_argument
(
'--data_url'
,
type
=
str,
default
=
'./data'
,
help
=
'Dataset directory'
)
args_opt
=
parser.parse_args
()
dataname
=
'cora'
datadir_save
=
'./data_mr'
datadir
=
os.path.join
(
datadir_save, dataname
)
cfg
=
edict
({
'SRC_PATH'
:
'./data'
,
'MINDRECORD_PATH'
: datadir_save,
'DATASET_NAME'
: dataname,
# citeseer,cora
'mindrecord_partitions'
:1,
'mindrecord_header_size_by_bit'
: 18,
'mindrecord_page_size_by_bit'
: 20,
'data_dir'
: datadir,
'seed'
: 123,
'train_nodes_num'
:140,
'eval_nodes_num'
:500,
'test_nodes_num'
:1000
})
#转换数据格式
print
(
"============== Graph To Mindrecord =============="
)
run
(
cfg
)
#训练
print
(
"============== Starting Training =============="
)
train
(
cfg
)
```
MindSpore暂时没有提供直接访问OBS数据的接口,需要通过MoXing提供的API与OBS交互。将OBS中存储的数据拷贝至执行容器:
```
python
import
moxing
as
mox
mox
.
file
.
copy_parallel
(
args
.
data_url
,
dst_url
=
'./data'
)
```
将训练模型Checkpoint从执行容器拷贝至OBS:
```
python
mox
.
file
.
copy_parallel
(
src_url
=
'data_mr'
,
dst_url
=
cfg
.
MINDRECORD_PATH
)
```
### 实验结果
训练结果将存储在脚本路径中,该路径的文件夹名称以“ train”开头。可以在日志中找到类似以下结果。
```
shell
Epoch: 0000
train_loss
=
1.95401
train_acc
=
0.12143
val_loss
=
1.94917
val_acc
=
0.31400
time
=
36.95478
Epoch: 0010
train_loss
=
1.86495
train_acc
=
0.85000
val_loss
=
1.90644
val_acc
=
0.50200
time
=
0.00491
Epoch: 0020
train_loss
=
1.75353
train_acc
=
0.88571
val_loss
=
1.86284
val_acc
=
0.53000
time
=
0.00525
Epoch: 0030
train_loss
=
1.59934
train_acc
=
0.87857
val_loss
=
1.80850
val_acc
=
0.55400
time
=
0.00517
Epoch: 0040
train_loss
=
1.45166
train_acc
=
0.91429
val_loss
=
1.74404
val_acc
=
0.59400
time
=
0.00502
Epoch: 0050
train_loss
=
1.29577
train_acc
=
0.94286
val_loss
=
1.67278
val_acc
=
0.67200
time
=
0.00491
Epoch: 0060
train_loss
=
1.13297
train_acc
=
0.97857
val_loss
=
1.59820
val_acc
=
0.72800
time
=
0.00482
Epoch: 0070
train_loss
=
1.05231
train_acc
=
0.95714
val_loss
=
1.52455
val_acc
=
0.74800
time
=
0.00506
Epoch: 0080
train_loss
=
0.97807
train_acc
=
0.97143
val_loss
=
1.45385
val_acc
=
0.76800
time
=
0.00519
Epoch: 0090
train_loss
=
0.85581
train_acc
=
0.97143
val_loss
=
1.39556
val_acc
=
0.77400
time
=
0.00476
Epoch: 0100
train_loss
=
0.81426
train_acc
=
0.98571
val_loss
=
1.34453
val_acc
=
0.78400
time
=
0.00479
Epoch: 0110
train_loss
=
0.74759
train_acc
=
0.97143
val_loss
=
1.28945
val_acc
=
0.78400
time
=
0.00516
Epoch: 0120
train_loss
=
0.70512
train_acc
=
0.99286
val_loss
=
1.24538
val_acc
=
0.78600
time
=
0.00517
Epoch: 0130
train_loss
=
0.69883
train_acc
=
0.98571
val_loss
=
1.21186
val_acc
=
0.78200
time
=
0.00531
Epoch: 0140
train_loss
=
0.66174
train_acc
=
0.98571
val_loss
=
1.19131
val_acc
=
0.78400
time
=
0.00481
Epoch: 0150
train_loss
=
0.57727
train_acc
=
0.98571
val_loss
=
1.15812
val_acc
=
0.78600
time
=
0.00475
Epoch: 0160
train_loss
=
0.59659
train_acc
=
0.98571
val_loss
=
1.13203
val_acc
=
0.77800
time
=
0.00553
Epoch: 0170
train_loss
=
0.59405
train_acc
=
0.97143
val_loss
=
1.12650
val_acc
=
0.78600
time
=
0.00555
Epoch: 0180
train_loss
=
0.55484
train_acc
=
1.00000
val_loss
=
1.09338
val_acc
=
0.78000
time
=
0.00542
Epoch: 0190
train_loss
=
0.52347
train_acc
=
0.99286
val_loss
=
1.07537
val_acc
=
0.78800
time
=
0.00510
Test
set
results:
loss
=
1.01702
accuracy
=
0.81400
time
=
6.51215
```
运行main.py会在当前目录下生成一个关于Cora训练数据的动态图t-SNE_visualization_on_Cora.gif。

### 适配训练作业
创建训练作业时,运行参数会通过脚本传参的方式输入给脚本代码,脚本必须解析传参才能在代码中使用相应参数。如data_url和train_url,分别对应数据存储路径(OBS路径)和训练输出路径(OBS路径)。脚本对传参进行解析后赋值到
`args`
变量里,在后续代码里可以使用。
```
python
import
argparse
parser
=
argparse
.
ArgumentParser
()
parser
.
add_argument
(
'--data_url'
,
required
=
False
,
default
=
None
,
help
=
'Location of data.'
)
parser
.
add_argument
(
'--train_url'
,
required
=
False
,
default
=
None
,
help
=
'Location of training outputs.'
)
args
=
parser
.
parse_args
()
dataset
=
args
.
dataset
```
MindSpore暂时没有提供直接访问OBS数据的接口,需要通过MoXing提供的API与OBS交互。将OBS中存储的数据拷贝至执行容器(见
`start.py`
):
```
python
import
moxing
as
mox
mox
.
file
.
copy_parallel
(
src_url
=
args
.
data_url
,
dst_url
=
'data/'
)
```
### 创建训练作业
可以参考
[
使用常用框架训练模型
](
https://support.huaweicloud.com/engineers-modelarts/modelarts_23_0238.html
)
来创建并启动训练作业。
创建训练作业的参考配置:
-
算法来源:常用框架->Ascend-Powered-Engine->MindSpore
-
代码目录:选择上述新建的OBS桶中的experiment目录
-
启动文件:选择上述新建的OBS桶中的experiment目录下的
`start.py`
-
数据来源:数据存储位置->选择上述新建的OBS桶中的experiment目录下的data目录
-
训练输出位置:选择上述新建的OBS桶中的experiment目录并在其中创建output目录
-
作业日志路径:同训练输出位置
-
规格:Ascend:1
*
Ascend 910
-
其他均为默认
启动并查看训练过程:
1.
点击提交以开始训练;
2.
在训练作业列表里可以看到刚创建的训练作业,在训练作业页面可以看到版本管理;
3.
点击运行中的训练作业,在展开的窗口中可以查看作业配置信息,以及训练过程中的日志,日志会不断刷新,等训练作业完成后也可以下载日志到本地进行查看;
4.
参考上述代码梳理,在日志中找到对应的打印信息,检查实验是否成功。
graph_convolutional_network/graph_to_mindrecord/citeseer/mr_api.py
0 → 100644
浏览文件 @
58a87f49
# Copyright 2020 Huawei Technologies Co., Ltd
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# ==============================================================================
"""
User-defined API for MindRecord GNN writer.
"""
import
os
import
pickle
as
pkl
import
numpy
as
np
import
scipy.sparse
as
sp
# parse args from command line parameter 'graph_api_args'
# args delimiter is ':'
args
=
os
.
environ
[
'graph_api_args'
].
split
(
':'
)
CITESEER_PATH
=
args
[
0
]
dataset_str
=
'citeseer'
# profile: (num_features, feature_data_types, feature_shapes)
node_profile
=
(
2
,
[
"float32"
,
"int32"
],
[[
-
1
],
[
-
1
]])
edge_profile
=
(
0
,
[],
[])
node_ids
=
[]
def
_normalize_citeseer_features
(
features
):
row_sum
=
np
.
array
(
features
.
sum
(
1
))
r_inv
=
np
.
power
(
row_sum
*
1.0
,
-
1
).
flatten
()
r_inv
[
np
.
isinf
(
r_inv
)]
=
0.
r_mat_inv
=
sp
.
diags
(
r_inv
)
features
=
r_mat_inv
.
dot
(
features
)
return
features
def
_parse_index_file
(
filename
):
"""Parse index file."""
index
=
[]
for
line
in
open
(
filename
):
index
.
append
(
int
(
line
.
strip
()))
return
index
def
yield_nodes
(
task_id
=
0
):
"""
Generate node data
Yields:
data (dict): data row which is dict.
"""
print
(
"Node task is {}"
.
format
(
task_id
))
names
=
[
'x'
,
'y'
,
'tx'
,
'ty'
,
'allx'
,
'ally'
]
objects
=
[]
for
name
in
names
:
with
open
(
"{}/ind.{}.{}"
.
format
(
CITESEER_PATH
,
dataset_str
,
name
),
'rb'
)
as
f
:
objects
.
append
(
pkl
.
load
(
f
,
encoding
=
'latin1'
))
x
,
y
,
tx
,
ty
,
allx
,
ally
=
tuple
(
objects
)
test_idx_reorder
=
_parse_index_file
(
"{}/ind.{}.test.index"
.
format
(
CITESEER_PATH
,
dataset_str
))
test_idx_range
=
np
.
sort
(
test_idx_reorder
)
tx
=
_normalize_citeseer_features
(
tx
)
allx
=
_normalize_citeseer_features
(
allx
)
# Fix citeseer dataset (there are some isolated nodes in the graph)
# Find isolated nodes, add them as zero-vecs into the right position
test_idx_range_full
=
range
(
min
(
test_idx_reorder
),
max
(
test_idx_reorder
)
+
1
)
tx_extended
=
sp
.
lil_matrix
((
len
(
test_idx_range_full
),
x
.
shape
[
1
]))
tx_extended
[
test_idx_range
-
min
(
test_idx_range
),
:]
=
tx
tx
=
tx_extended
ty_extended
=
np
.
zeros
((
len
(
test_idx_range_full
),
y
.
shape
[
1
]))
ty_extended
[
test_idx_range
-
min
(
test_idx_range
),
:]
=
ty
ty
=
ty_extended
features
=
sp
.
vstack
((
allx
,
tx
)).
tolil
()
features
[
test_idx_reorder
,
:]
=
features
[
test_idx_range
,
:]
features
=
features
.
A
labels
=
np
.
vstack
((
ally
,
ty
))
labels
[
test_idx_reorder
,
:]
=
labels
[
test_idx_range
,
:]
line_count
=
0
for
i
,
label
in
enumerate
(
labels
):
if
not
1
in
label
.
tolist
():
continue
node
=
{
'id'
:
i
,
'type'
:
0
,
'feature_1'
:
features
[
i
].
tolist
(),
'feature_2'
:
label
.
tolist
().
index
(
1
)}
line_count
+=
1
node_ids
.
append
(
i
)
yield
node
print
(
'Processed {} lines for nodes.'
.
format
(
line_count
))
def
yield_edges
(
task_id
=
0
):
"""
Generate edge data
Yields:
data (dict): data row which is dict.
"""
print
(
"Edge task is {}"
.
format
(
task_id
))
with
open
(
"{}/ind.{}.graph"
.
format
(
CITESEER_PATH
,
dataset_str
),
'rb'
)
as
f
:
graph
=
pkl
.
load
(
f
,
encoding
=
'latin1'
)
line_count
=
0
for
i
in
graph
:
for
dst_id
in
graph
[
i
]:
if
not
i
in
node_ids
:
print
(
'Source node {} does not exist.'
.
format
(
i
))
continue
if
not
dst_id
in
node_ids
:
print
(
'Destination node {} does not exist.'
.
format
(
dst_id
))
continue
edge
=
{
'id'
:
line_count
,
'src_id'
:
i
,
'dst_id'
:
dst_id
,
'type'
:
0
}
line_count
+=
1
yield
edge
print
(
'Processed {} lines for edges.'
.
format
(
line_count
))
graph_convolutional_network/graph_to_mindrecord/cora/mr_api.py
0 → 100644
浏览文件 @
58a87f49
# Copyright 2020 Huawei Technologies Co., Ltd
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# ==============================================================================
"""
User-defined API for MindRecord GNN writer.
"""
import
os
import
pickle
as
pkl
import
numpy
as
np
import
scipy.sparse
as
sp
# parse args from command line parameter 'graph_api_args'
# args delimiter is ':'
args
=
os
.
environ
[
'graph_api_args'
].
split
(
':'
)
CORA_PATH
=
args
[
0
]
dataset_str
=
'cora'
# profile: (num_features, feature_data_types, feature_shapes)
node_profile
=
(
2
,
[
"float32"
,
"int32"
],
[[
-
1
],
[
-
1
]])
edge_profile
=
(
0
,
[],
[])
def
_normalize_cora_features
(
features
):
row_sum
=
np
.
array
(
features
.
sum
(
1
))
r_inv
=
np
.
power
(
row_sum
*
1.0
,
-
1
).
flatten
()
r_inv
[
np
.
isinf
(
r_inv
)]
=
0.
r_mat_inv
=
sp
.
diags
(
r_inv
)
features
=
r_mat_inv
.
dot
(
features
)
return
features
def
_parse_index_file
(
filename
):
"""Parse index file."""
index
=
[]
for
line
in
open
(
filename
):
index
.
append
(
int
(
line
.
strip
()))
return
index
def
yield_nodes
(
task_id
=
0
):
"""
Generate node data
Yields:
data (dict): data row which is dict.
"""
print
(
"Node task is {}"
.
format
(
task_id
))
names
=
[
'tx'
,
'ty'
,
'allx'
,
'ally'
]
objects
=
[]
for
name
in
names
:
with
open
(
"{}/ind.{}.{}"
.
format
(
CORA_PATH
,
dataset_str
,
name
),
'rb'
)
as
f
:
objects
.
append
(
pkl
.
load
(
f
,
encoding
=
'latin1'
))
tx
,
ty
,
allx
,
ally
=
tuple
(
objects
)
test_idx_reorder
=
_parse_index_file
(
"{}/ind.{}.test.index"
.
format
(
CORA_PATH
,
dataset_str
))
test_idx_range
=
np
.
sort
(
test_idx_reorder
)
features
=
sp
.
vstack
((
allx
,
tx
)).
tolil
()
features
[
test_idx_reorder
,
:]
=
features
[
test_idx_range
,
:]
features
=
_normalize_cora_features
(
features
)
features
=
features
.
A
labels
=
np
.
vstack
((
ally
,
ty
))
labels
[
test_idx_reorder
,
:]
=
labels
[
test_idx_range
,
:]
line_count
=
0
for
i
,
label
in
enumerate
(
labels
):
node
=
{
'id'
:
i
,
'type'
:
0
,
'feature_1'
:
features
[
i
].
tolist
(),
'feature_2'
:
label
.
tolist
().
index
(
1
)}
line_count
+=
1
yield
node
print
(
'Processed {} lines for nodes.'
.
format
(
line_count
))
def
yield_edges
(
task_id
=
0
):
"""
Generate edge data
Yields:
data (dict): data row which is dict.
"""
print
(
"Edge task is {}"
.
format
(
task_id
))
with
open
(
"{}/ind.{}.graph"
.
format
(
CORA_PATH
,
dataset_str
),
'rb'
)
as
f
:
graph
=
pkl
.
load
(
f
,
encoding
=
'latin1'
)
line_count
=
0
for
i
in
graph
:
for
dst_id
in
graph
[
i
]:
edge
=
{
'id'
:
line_count
,
'src_id'
:
i
,
'dst_id'
:
dst_id
,
'type'
:
0
}
line_count
+=
1
yield
edge
print
(
'Processed {} lines for edges.'
.
format
(
line_count
))
graph_convolutional_network/graph_to_mindrecord/graph_map_schema.py
0 → 100644
浏览文件 @
58a87f49
# Copyright 2019 Huawei Technologies Co., Ltd
#
# Licensed under the Apache License, Version 2.0 (the "License")
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# ==============================================================================
"""
Graph data convert tool for MindRecord.
"""
import
numpy
as
np
__all__
=
[
'GraphMapSchema'
]
class
GraphMapSchema
:
"""
Class is for transformation from graph data to MindRecord.
"""
def
__init__
(
self
):
"""
init
"""
self
.
num_node_features
=
0
self
.
num_edge_features
=
0
self
.
union_schema_in_mindrecord
=
{
"first_id"
:
{
"type"
:
"int64"
},
"second_id"
:
{
"type"
:
"int64"
},
"third_id"
:
{
"type"
:
"int64"
},
"type"
:
{
"type"
:
"int32"
},
"attribute"
:
{
"type"
:
"string"
},
# 'n' for ndoe, 'e' for edge
"node_feature_index"
:
{
"type"
:
"int32"
,
"shape"
:
[
-
1
]},
"edge_feature_index"
:
{
"type"
:
"int32"
,
"shape"
:
[
-
1
]}
}
def
get_schema
(
self
):
"""
Get schema
"""
return
self
.
union_schema_in_mindrecord
def
set_node_feature_profile
(
self
,
num_features
,
features_data_type
,
features_shape
):
"""
Set node features profile
"""
if
num_features
!=
len
(
features_data_type
)
or
num_features
!=
len
(
features_shape
):
raise
ValueError
(
"Node feature profile is not match."
)
self
.
num_node_features
=
num_features
for
i
in
range
(
num_features
):
k
=
i
+
1
field_key
=
'node_feature_'
+
str
(
k
)
field_value
=
{
"type"
:
features_data_type
[
i
],
"shape"
:
features_shape
[
i
]}
self
.
union_schema_in_mindrecord
[
field_key
]
=
field_value
def
set_edge_feature_profile
(
self
,
num_features
,
features_data_type
,
features_shape
):
"""
Set edge features profile
"""
if
num_features
!=
len
(
features_data_type
)
or
num_features
!=
len
(
features_shape
):
raise
ValueError
(
"Edge feature profile is not match."
)
self
.
num_edge_features
=
num_features
for
i
in
range
(
num_features
):
k
=
i
+
1
field_key
=
'edge_feature_'
+
str
(
k
)
field_value
=
{
"type"
:
features_data_type
[
i
],
"shape"
:
features_shape
[
i
]}
self
.
union_schema_in_mindrecord
[
field_key
]
=
field_value
def
transform_node
(
self
,
node
):
"""
Executes transformation from node data to union format.
Args:
node(schema): node's data
Returns:
graph data with union schema
"""
node_graph
=
{
"first_id"
:
node
[
"id"
],
"second_id"
:
0
,
"third_id"
:
0
,
"attribute"
:
'n'
,
"type"
:
node
[
"type"
],
"node_feature_index"
:
[]}
for
i
in
range
(
self
.
num_node_features
):
k
=
i
+
1
node_field_key
=
'feature_'
+
str
(
k
)
graph_field_key
=
'node_feature_'
+
str
(
k
)
graph_field_type
=
self
.
union_schema_in_mindrecord
[
graph_field_key
][
"type"
]
if
node_field_key
in
node
:
node_graph
[
"node_feature_index"
].
append
(
k
)
node_graph
[
graph_field_key
]
=
np
.
reshape
(
np
.
array
(
node
[
node_field_key
],
dtype
=
graph_field_type
),
[
-
1
])
else
:
node_graph
[
graph_field_key
]
=
np
.
reshape
(
np
.
array
([
0
],
dtype
=
graph_field_type
),
[
-
1
])
if
node_graph
[
"node_feature_index"
]:
node_graph
[
"node_feature_index"
]
=
np
.
array
(
node_graph
[
"node_feature_index"
],
dtype
=
"int32"
)
else
:
node_graph
[
"node_feature_index"
]
=
np
.
array
([
-
1
],
dtype
=
"int32"
)
node_graph
[
"edge_feature_index"
]
=
np
.
array
([
-
1
],
dtype
=
"int32"
)
for
i
in
range
(
self
.
num_edge_features
):
k
=
i
+
1
graph_field_key
=
'edge_feature_'
+
str
(
k
)
graph_field_type
=
self
.
union_schema_in_mindrecord
[
graph_field_key
][
"type"
]
node_graph
[
graph_field_key
]
=
np
.
reshape
(
np
.
array
([
0
],
dtype
=
graph_field_type
),
[
-
1
])
return
node_graph
def
transform_edge
(
self
,
edge
):
"""
Executes transformation from edge data to union format.
Args:
edge(schema): edge's data
Returns:
graph data with union schema
"""
edge_graph
=
{
"first_id"
:
edge
[
"id"
],
"second_id"
:
edge
[
"src_id"
],
"third_id"
:
edge
[
"dst_id"
],
"attribute"
:
'e'
,
"type"
:
edge
[
"type"
],
"edge_feature_index"
:
[]}
for
i
in
range
(
self
.
num_edge_features
):
k
=
i
+
1
edge_field_key
=
'feature_'
+
str
(
k
)
graph_field_key
=
'edge_feature_'
+
str
(
k
)
graph_field_type
=
self
.
union_schema_in_mindrecord
[
graph_field_key
][
"type"
]
if
edge_field_key
in
edge
:
edge_graph
[
"edge_feature_index"
].
append
(
k
)
edge_graph
[
graph_field_key
]
=
np
.
reshape
(
np
.
array
(
edge
[
edge_field_key
],
dtype
=
graph_field_type
),
[
-
1
])
else
:
edge_graph
[
graph_field_key
]
=
np
.
reshape
(
np
.
array
([
0
],
dtype
=
graph_field_type
),
[
-
1
])
if
edge_graph
[
"edge_feature_index"
]:
edge_graph
[
"edge_feature_index"
]
=
np
.
array
(
edge_graph
[
"edge_feature_index"
],
dtype
=
"int32"
)
else
:
edge_graph
[
"edge_feature_index"
]
=
np
.
array
([
-
1
],
dtype
=
"int32"
)
edge_graph
[
"node_feature_index"
]
=
np
.
array
([
-
1
],
dtype
=
"int32"
)
for
i
in
range
(
self
.
num_node_features
):
k
=
i
+
1
graph_field_key
=
'node_feature_'
+
str
(
k
)
graph_field_type
=
self
.
union_schema_in_mindrecord
[
graph_field_key
][
"type"
]
edge_graph
[
graph_field_key
]
=
np
.
array
([
0
],
dtype
=
graph_field_type
)
return
edge_graph
graph_convolutional_network/graph_to_mindrecord/writer.py
0 → 100644
浏览文件 @
58a87f49
# Copyright 2020 Huawei Technologies Co., Ltd
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# ==============================================================================
"""
######################## write mindrecord example ########################
Write mindrecord by data dictionary:
python writer.py --mindrecord_script /YourScriptPath ...
"""
import
argparse
import
os
import
time
from
importlib
import
import_module
from
multiprocessing
import
Pool
import
shutil
from
mindspore.mindrecord
import
FileWriter
from
.graph_map_schema
import
GraphMapSchema
# import cora.mr_api
def
read_args
():
"""
read args
"""
parser
=
argparse
.
ArgumentParser
(
description
=
'Mind record writer'
)
parser
.
add_argument
(
'--mindrecord_script'
,
type
=
str
,
default
=
"template"
,
help
=
'path where script is saved'
)
parser
.
add_argument
(
'--mindrecord_file'
,
type
=
str
,
default
=
"/tmp/mindrecord/xyz"
,
help
=
'written file name prefix'
)
parser
.
add_argument
(
'--mindrecord_partitions'
,
type
=
int
,
default
=
1
,
help
=
'number of written files'
)
parser
.
add_argument
(
'--mindrecord_header_size_by_bit'
,
type
=
int
,
default
=
24
,
help
=
'mindrecord file header size'
)
parser
.
add_argument
(
'--mindrecord_page_size_by_bit'
,
type
=
int
,
default
=
25
,
help
=
'mindrecord file page size'
)
parser
.
add_argument
(
'--mindrecord_workers'
,
type
=
int
,
default
=
8
,
help
=
'number of parallel workers'
)
parser
.
add_argument
(
'--num_node_tasks'
,
type
=
int
,
default
=
1
,
help
=
'number of node tasks'
)
parser
.
add_argument
(
'--num_edge_tasks'
,
type
=
int
,
default
=
1
,
help
=
'number of node tasks'
)
parser
.
add_argument
(
'--graph_api_args'
,
type
=
str
,
default
=
"/tmp/nodes.csv:/tmp/edges.csv"
,
help
=
'nodes and edges data file, csv format with header.'
)
ret_args
=
parser
.
parse_args
()
return
ret_args
def
run
(
cfg
):
args
=
read_args
()
#建立输出文件夹
cur_path
=
os
.
getcwd
()
M_PATH
=
os
.
path
.
join
(
cur_path
,
cfg
.
MINDRECORD_PATH
)
if
os
.
path
.
exists
(
M_PATH
):
shutil
.
rmtree
(
M_PATH
)
# 删除文件夹
os
.
mkdir
(
M_PATH
)
cfg
.
SRC_PATH
=
os
.
path
.
join
(
cur_path
,
cfg
.
SRC_PATH
)
#参数
args
.
mindrecord_script
=
cfg
.
DATASET_NAME
args
.
mindrecord_file
=
os
.
path
.
join
(
cfg
.
MINDRECORD_PATH
,
cfg
.
DATASET_NAME
)
args
.
mindrecord_partitions
=
cfg
.
mindrecord_partitions
args
.
mindrecord_header_size_by_bit
=
cfg
.
mindrecord_header_size_by_bit
args
.
mindrecord_page_size_by_bit
=
cfg
.
mindrecord_header_size_by_bit
args
.
graph_api_args
=
cfg
.
SRC_PATH
start_time
=
time
.
time
()
# pass mr_api arguments
os
.
environ
[
'graph_api_args'
]
=
args
.
graph_api_args
try
:
mr_api
=
import_module
(
'graph_to_mindrecord.'
+
args
.
mindrecord_script
+
'.mr_api'
)
except
ModuleNotFoundError
:
raise
RuntimeError
(
"Unknown module path: {}"
.
format
(
args
.
mindrecord_script
+
'.mr_api'
))
# init graph schema
graph_map_schema
=
GraphMapSchema
()
num_features
,
feature_data_types
,
feature_shapes
=
mr_api
.
node_profile
graph_map_schema
.
set_node_feature_profile
(
num_features
,
feature_data_types
,
feature_shapes
)
num_features
,
feature_data_types
,
feature_shapes
=
mr_api
.
edge_profile
graph_map_schema
.
set_edge_feature_profile
(
num_features
,
feature_data_types
,
feature_shapes
)
graph_schema
=
graph_map_schema
.
get_schema
()
#----------------------------------------------------------------------------------------------
def
init_writer
(
mr_schema
):
"""
init writer
"""
print
(
"Init writer ..."
)
mr_writer
=
FileWriter
(
args
.
mindrecord_file
,
args
.
mindrecord_partitions
)
# set the header size
if
args
.
mindrecord_header_size_by_bit
!=
24
:
header_size
=
1
<<
args
.
mindrecord_header_size_by_bit
mr_writer
.
set_header_size
(
header_size
)
# set the page size
if
args
.
mindrecord_page_size_by_bit
!=
25
:
page_size
=
1
<<
args
.
mindrecord_page_size_by_bit
mr_writer
.
set_page_size
(
page_size
)
# create the schema
mr_writer
.
add_schema
(
mr_schema
,
"mindrecord_graph_schema"
)
# open file and set header
mr_writer
.
open_and_set_header
()
return
mr_writer
def
run_parallel_workers
():
"""
run parallel workers
"""
# set number of workers
num_workers
=
args
.
mindrecord_workers
task_list
=
list
(
range
(
args
.
num_node_tasks
))
if
num_workers
>
args
.
num_node_tasks
:
num_workers
=
args
.
num_node_tasks
if
os
.
name
==
'nt'
:
for
window_task_id
in
task_list
:
exec_task
(
window_task_id
,
False
)
elif
args
.
num_node_tasks
>
1
:
with
Pool
(
num_workers
)
as
p
:
p
.
map
(
exec_task
,
task_list
)
else
:
exec_task
(
0
,
False
)
def
exec_task
(
task_id
,
parallel_writer
=
True
):
"""
Execute task with specified task id
"""
print
(
"exec task {}, parallel: {} ..."
.
format
(
task_id
,
parallel_writer
))
imagenet_iter
=
mindrecord_dict_data
(
task_id
)
batch_size
=
512
transform_count
=
0
while
True
:
data_list
=
[]
try
:
for
_
in
range
(
batch_size
):
data
=
imagenet_iter
.
__next__
()
if
'dst_id'
in
data
:
data
=
graph_map_schema
.
transform_edge
(
data
)
else
:
data
=
graph_map_schema
.
transform_node
(
data
)
data_list
.
append
(
data
)
transform_count
+=
1
writer
.
write_raw_data
(
data_list
,
parallel_writer
=
parallel_writer
)
print
(
"transformed {} record..."
.
format
(
transform_count
))
except
StopIteration
:
if
data_list
:
writer
.
write_raw_data
(
data_list
,
parallel_writer
=
parallel_writer
)
print
(
"transformed {} record..."
.
format
(
transform_count
))
break
#-------------------------------------------------------------------------------------
# init writer
writer
=
init_writer
(
graph_schema
)
# write nodes data
mindrecord_dict_data
=
mr_api
.
yield_nodes
run_parallel_workers
()
# write edges data
mindrecord_dict_data
=
mr_api
.
yield_edges
run_parallel_workers
()
# writer wrap up
ret
=
writer
.
commit
()
end_time
=
time
.
time
()
print
(
"--------------------------------------------"
)
print
(
"END. Total time: {}"
.
format
(
end_time
-
start_time
))
print
(
"--------------------------------------------"
)
graph_convolutional_network/images/gcn1.png
0 → 100644
浏览文件 @
58a87f49
57.0 KB
graph_convolutional_network/images/gcn2.png
0 → 100644
浏览文件 @
58a87f49
16.2 KB
graph_convolutional_network/images/t-SNE_visualization_on_Cora.gif
0 → 100644
浏览文件 @
58a87f49
6.3 MB
graph_convolutional_network/main.py
0 → 100644
浏览文件 @
58a87f49
import
time
import
argparse
import
os
from
easydict
import
EasyDict
as
edict
import
numpy
as
np
from
mindspore
import
context
from
src.gcn
import
GCN
,
LossAccuracyWrapper
,
TrainNetWrapper
from
src.config
import
ConfigGCN
from
src.dataset
import
get_adj_features_labels
,
get_mask
from
graph_to_mindrecord.writer
import
run
os
.
environ
[
'DEVICE_ID'
]
=
'6'
context
.
set_context
(
mode
=
context
.
GRAPH_MODE
,
device_target
=
"Ascend"
,
save_graphs
=
False
)
def
train
(
args_opt
):
"""Train model."""
np
.
random
.
seed
(
args_opt
.
seed
)
config
=
ConfigGCN
()
adj
,
feature
,
label
=
get_adj_features_labels
(
args_opt
.
data_dir
)
nodes_num
=
label
.
shape
[
0
]
train_mask
=
get_mask
(
nodes_num
,
0
,
args_opt
.
train_nodes_num
)
eval_mask
=
get_mask
(
nodes_num
,
args_opt
.
train_nodes_num
,
args_opt
.
train_nodes_num
+
args_opt
.
eval_nodes_num
)
test_mask
=
get_mask
(
nodes_num
,
nodes_num
-
args_opt
.
test_nodes_num
,
nodes_num
)
class_num
=
label
.
shape
[
1
]
gcn_net
=
GCN
(
config
,
adj
,
feature
,
class_num
)
gcn_net
.
add_flags_recursive
(
fp16
=
True
)
eval_net
=
LossAccuracyWrapper
(
gcn_net
,
label
,
eval_mask
,
config
.
weight_decay
)
test_net
=
LossAccuracyWrapper
(
gcn_net
,
label
,
test_mask
,
config
.
weight_decay
)
train_net
=
TrainNetWrapper
(
gcn_net
,
label
,
train_mask
,
config
)
loss_list
=
[]
for
epoch
in
range
(
config
.
epochs
):
t
=
time
.
time
()
train_net
.
set_train
()
train_result
=
train_net
()
train_loss
=
train_result
[
0
].
asnumpy
()
train_accuracy
=
train_result
[
1
].
asnumpy
()
eval_net
.
set_train
(
False
)
eval_result
=
eval_net
()
eval_loss
=
eval_result
[
0
].
asnumpy
()
eval_accuracy
=
eval_result
[
1
].
asnumpy
()
loss_list
.
append
(
eval_loss
)
if
epoch
%
10
==
0
:
print
(
"Epoch:"
,
'%04d'
%
(
epoch
),
"train_loss="
,
"{:.5f}"
.
format
(
train_loss
),
"train_acc="
,
"{:.5f}"
.
format
(
train_accuracy
),
"val_loss="
,
"{:.5f}"
.
format
(
eval_loss
),
"val_acc="
,
"{:.5f}"
.
format
(
eval_accuracy
),
"time="
,
"{:.5f}"
.
format
(
time
.
time
()
-
t
))
if
epoch
>
config
.
early_stopping
and
loss_list
[
-
1
]
>
np
.
mean
(
loss_list
[
-
(
config
.
early_stopping
+
1
):
-
1
]):
print
(
"Early stopping..."
)
break
t_test
=
time
.
time
()
test_net
.
set_train
(
False
)
test_result
=
test_net
()
test_loss
=
test_result
[
0
].
asnumpy
()
test_accuracy
=
test_result
[
1
].
asnumpy
()
print
(
"Test set results:"
,
"loss="
,
"{:.5f}"
.
format
(
test_loss
),
"accuracy="
,
"{:.5f}"
.
format
(
test_accuracy
),
"time="
,
"{:.5f}"
.
format
(
time
.
time
()
-
t_test
))
if
__name__
==
'__main__'
:
#------------------------定义变量------------------------------
parser
=
argparse
.
ArgumentParser
(
description
=
'GCN'
)
parser
.
add_argument
(
'--data_url'
,
type
=
str
,
default
=
'./data'
,
help
=
'Dataset directory'
)
parser
.
add_argument
(
'--train_url'
,
type
=
str
,
default
=
None
,
help
=
'Train output url'
)
args
,
unknown
=
parser
.
parse_known_args
()
import
moxing
as
mox
mox
.
file
.
copy_parallel
(
args
.
data_url
,
dst_url
=
'./data'
)
# 将OBS桶中数据拷贝到容器中
dataname
=
'cora'
datadir_save
=
'./data_mr'
datadir
=
os
.
path
.
join
(
datadir_save
,
dataname
)
cfg
=
edict
({
'SRC_PATH'
:
'./data'
,
'MINDRECORD_PATH'
:
datadir_save
,
'DATASET_NAME'
:
dataname
,
# citeseer,cora
'mindrecord_partitions'
:
1
,
'mindrecord_header_size_by_bit'
:
18
,
'mindrecord_page_size_by_bit'
:
20
,
'data_dir'
:
datadir
,
'seed'
:
123
,
'train_nodes_num'
:
140
,
'eval_nodes_num'
:
500
,
'test_nodes_num'
:
1000
})
#转换数据格式
print
(
"============== Graph To Mindrecord =============="
)
run
(
cfg
)
#训练
print
(
"============== Starting Training =============="
)
train
(
cfg
)
mox
.
file
.
copy_parallel
(
src_url
=
'data_mr'
,
dst_url
=
cfg
.
MINDRECORD_PATH
)
# src_url本地 将容器输出放入OBS桶中
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}

{kind=link}
{kind=link}
