`milvus_benchmark` is a non-functional testing tool which allows users to run tests on k8s cluster or at local, the primary use case is performance/load/stability testing, the objective is to expose problems in milvus project.
The milvus_benchmark is a non-functional testing tool or service which allows users to run tests on k8s cluster or at local, the primary use case is performance/load/stability testing, the objective is to expose problems in milvus project.
## Quick start
### Description:
### Description
- Test cases in `milvus_benchmark` can be organized with `yaml`
- Test can run with local mode or helm mode
- local: install and start your local server, and pass the host/port param when start the tests
- helm: install the server by helm, which will manage the milvus in k8s cluster, and you can interagte the test stage into argo workflow or jenkins pipeline
### Usage
### Usage:
1. Using jenkins:
- Using jenkins:
Use `ci/main_jenkinsfile` as the jenkins pipeline file
2. Using argo:
- Using argo:
example argo workflow yaml configuration: `ci/argo.yaml`
if we need to use the sift/deep dataset as the raw data input, we need to mount NAS and update `RAW_DATA_DIR` in `config.py`, the example mount command:
`sudo mount -t cifs -o username=test,vers=1.0 //172.16.70.249/test /test`
The top level is the runner type: the other test types including: `search_performance/build_performance/insert_performance/accuracy/locust_insert/...`, each test type corresponds to the different runner conponent defined in directory `runnners`
- other fields under runner type
The other parts in the test yaml is the params pass to the runner, such as:
- The field `collection_name` means which kind of collection will be created in milvus
- The field `ni_per` means the batch size
- The filed `build_index` means that whether to create index during inserting
While using argo workflow as benchmark pipeline, the test suite is made of both `client` and `server` configmap, an example will be like this:
`server`
```
kind: ConfigMap
apiVersion: v1
metadata:
name: server-cluster-8c16m
namespace: qa
uid: 3752f85c-c840-40c6-a5db-ae44146ad8b5
resourceVersion: '42213135'
creationTimestamp: '2021-05-14T07:00:53Z'
managedFields:
- manager: dashboard
operation: Update
apiVersion: v1
time: '2021-05-14T07:00:53Z'
fieldsType: FieldsV1
fieldsV1:
'f:data':
.: {}
'f:config.yaml': {}
data:
config.yaml: |
server:
server_tag: "8c16m"
milvus:
deploy_mode: "cluster"
```
`client`
```
kind: ConfigMap
apiVersion: v1
metadata:
name: client-insert-batch-1000
namespace: qa
uid: 8604c277-f00f-47c7-8fcb-9b3bc97efa74
resourceVersion: '42988547'
creationTimestamp: '2021-07-09T08:33:02Z'
managedFields:
- manager: dashboard
operation: Update
apiVersion: v1
fieldsType: FieldsV1
fieldsV1:
'f:data':
.: {}
'f:config.yaml': {}
data:
config.yaml: |
insert_performance:
collections:
-
milvus:
wal_enable: true
collection_name: sift_1m_128_l2
ni_per: 1000
build_index: false
index_type: ivf_sq8
index_param:
nlist: 1024
```
## Overview of the benchmark
### Conponents
-`main.py`
The entry file: parse the input params and initialize the other conponent: `metric`, `env`, `runner`
-`metric`
The test result can be used to analyze the regression or improvement of the milvus system, so we upload the metrics of the test result when a test suite run finished, and then use `redash` to make sense of our data
Test suite yaml defines the test process, users need to write test suite yaml if adding a customized test into the current test framework.
-`db`
Take the test file `2_insert_data.yaml` as an example, the top level is the test type: `insert_performance`, there are lots of test types including: `search_performance/build_performance/insert_performance/accuracy/locust_insert/...`, each test type corresponds to this different runner defined in directory `runnners`, the other parts in the test yaml is the params pass to the runner, such as the field `collection_name` means which kind of collection will be created in milvus.
Currently we use the `mongodb` to store the test result
### Test result:
-`env`
Test result will be uploaded if run with the helm mode, which will be used to judge if the test run pass or failed.
The `env` component defines the server environment and environment management, the instance of the `env` corresponds to the run mode of the benchmark
-`local`: Only defines the host and port for testing
-`helm/docker`: Install and uninstall the server in benchmark stage
-`runner`
The actual executor in benchmark, each test type defined in test suite will generate the corresponding runner instance, there are three stages in `runner`:
-`extract_cases`: There are several test cases defined in each test suite yaml, and each case shares the same server environment and shares the same `prepare` stage, but the `metric` for each case is different, so we need to extract cases from the test suite before the cases runs
-`prepare`: Prepare the data and operations, for example, before running searching, index needs to be created and data needs to be loaded
-`run_case`: Do the core operation and set `metric` value
-`suites`: There are two ways to take the content to be tested as input parameters:
- Test suite files under `suites` directory
- Test suite configmap name including `server_config_map` and `client_config_map` if using argo workflow
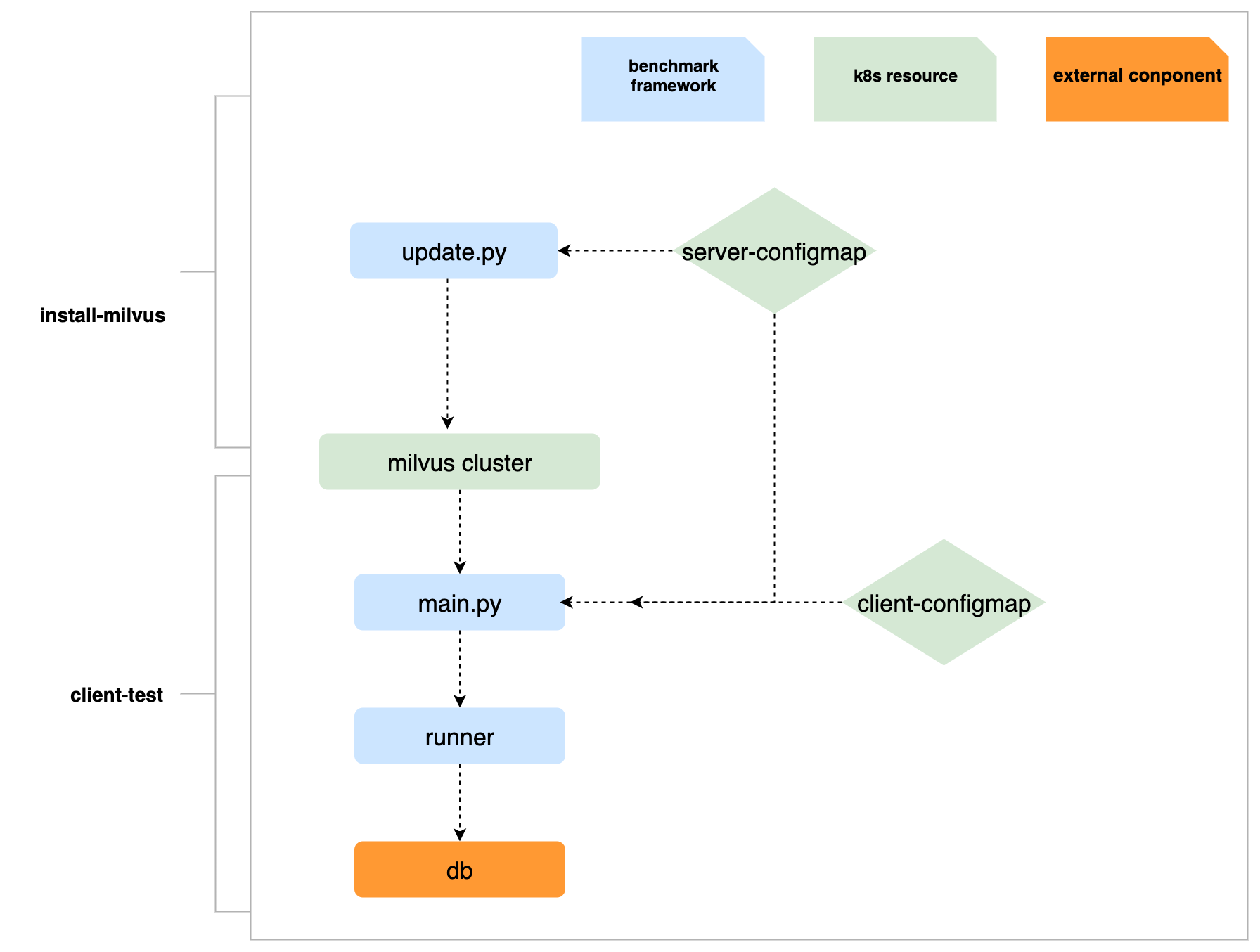
-`update.py`: While using argo workflow as benchmark pipeline, we have two steps in workflow template: `install-milvus` and `client-test`
- In stage `install-milvus`, `update.py` is used to generate a new `values.yaml` which will be a param while in `helm install` operation
- In stage `client-test`, it runs `main.py` and receives the milvus host and port as the cmd params, with the run mode `local`
### Conceptual overview
The following diagram shows the runtime execution graph of the benchmark (local mode based on argo workflow)
{kind=link}